

Last time around, I briefly discussed the Mayastor project we have been working on. Back then, it was not publicly available, but that has changed and is available for anyone and everyone to use, fork, contribute, and whatnot. And thanks for those of you already finding it, using it, and even contributing to it this Hacktoberfest!
As a reminder, one of the things we aspire to do is to "abstract away the underlying storage differences" with the help of Kubernetes and make the data layer "composable." Composable kind of has a ring to it (arguably), but what does it mean practically? What value does it bring, and perhaps most important: what problems does it solve? In this article, I'll try to explain that by giving an example based on something that most of you use every day: pipes, and I'll show how we are taking this concept to deliver a secure and cloud independent data layer.
Pipes
In the Unix world, the principle of building something small, and have this small thing only do one thing and one thing only, has withstood the test of time. This model works so well; that is not all that strange; we see the concept of micro services in modern-day apps.
Consider the following simple example:.png?width=467&name=carbon%20(3).png) I'm sure almost everyone has done this one way or the other. The (anonymous) pipe, between the two programs, is a form of transport that allows these apps to communicate with one and other. The `grep` command here will, in this case, filter out any lines that match `something,` and one could argue that it applies a transformation to the data.
I'm sure almost everyone has done this one way or the other. The (anonymous) pipe, between the two programs, is a form of transport that allows these apps to communicate with one and other. The `grep` command here will, in this case, filter out any lines that match `something,` and one could argue that it applies a transformation to the data.
However, things get a little more complicated if you wish to decompose your data layer this way. Data and the inherent gravity of data, to an extent far greater than you perhaps would like, impact how you develop your application. This is true in particular when you are on the path of transforming your legacy application to adopt more cloud-native paradigms.
In any case, when we refer to the "composable" part of what we mean is the ability to pipe your data between different layers of transformation, very much looks like the cat | grep example above. We have a layer that does one thing, and then we have another layer that does another. We know that this model works, right? The visionary designers of Unix have proven this!
Applying it to Mayastor
Now let's assume I have a k8s node that has some local storage, whether cloud volumes or NVMe physical systems. I want to pipe this storage in and out of the system. Although the pipe model still holds, it's not really a pipe as above, as it's anonymous, it has one reader and one writer. With named pipes, however, we can be a lot more creative, and we can replace the "|" by an actual NVMF fabric.
Our Nexus can connect to these pipes and start yet another pipe to which we will connect, for example, a Network Block Device (NBD) service. We can create these connections by merely using `mctl`: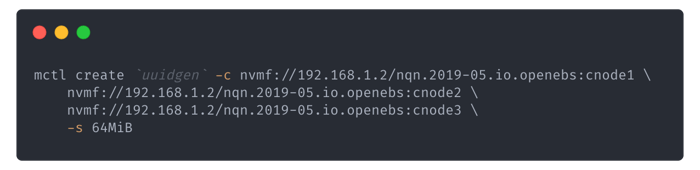
And then finally, we connect to the Nexus with NBD:
Now, of course, this is not entirely the same as with pipes but what we more or less have this: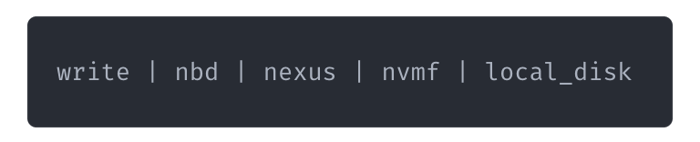
But we can do more. We can, for example, add a "transformation" and create this pipeline:
So now we have added encryption into our IO pipeline, and all data before leaving the Nexus is encrypted or in other words: in flight data gets encrypted. The other beautiful thing about this is that I can remove the encrypt pipe, and still read and pipe, and thus move the data without decrypting it first. We can still make backups onto some shared object store or whatever else we want. Compose it however you like, see?
MayaStor encryption
As you might imagine, the above example isn't theoretical. Recently we added encryption support to Mayastor, which by itself is not all that interesting. There are plenty of products that already do encryption. The difference with Mayastor, though, is that it is not tied to a particular cloud vendor. If you make use of a public cloud, chances are the data you store there is encrypted (right?!). If you want to move the data out of that cloud, however — let us say to a different vendor, how does that work? Can you, as with MayaStor, copy over the encrypted volume? As long as you have the keys, you have transferred your data over the web encrypted. Seems logical but not possible with the biggest cloud vendor. You need a "pipeline" roughly like this:
Let us go over these steps:
First, you need to read the data from the disk, where at (1) decryption takes place. This is handled implicitly by the cloud provider when encryption is enabled. You don't need to do anything for that except enabling it and keep track of your keys.
(2) Before you transfer it over the web, surely you want to do that encrypted, so you encrypt it again.
(3) Once received, you need to decrypt it again. And then finally write it to whatever target you use in the target cloud — encrypted with their encryption engine.
(4) That seems like a whole lot of risk and effort for copying data around, even setting aside the cost; for example, you need to have an instance running to crypt/decrypt the data and need to manage these encryption cycles on both ends independently. Who knew — there is such a thing as too much encryption
Wrapping up the pipeline
I hope you somewhat see that by abstracting the storage systems through the Nexus and being able to apply "transformations" that are somewhat analogous to pipelines, you get an idea of what we mean by a "composable" architecture. But, of course, there is more. The pipes need to be smart too.
By adding a (data) control plane, we can determine the optimal data "pipeline" best suited for the current environment/workload. For example, if you have a database that is connected through a single replica iSCSI, which connects to a container on the same node, why go through the overhead - of iSCSI and TCP (not to mention the network stack and the plural of iptables).
This would reduce latency significantly, giving more bang for the buck. In effect, it would allow you to negotiate what type of pipe you want to use between your app and your storage. It would even be possible to have an ordered list of connections sorted by connection preference. Add newer technologies like microVMs into the mix and thus virtio where we are also contributing — and you can see how it is important that pipes are smart as well or at the very least interchangeable by the control plane.
So if you are considering to build a cloud-native data lake or at least a lot of connected puddles, make sure you have your piping in order.
Please join me as we continue to build Mayastor into the open governance processes of the OpenEBS community - we have a community hangout on road map prioritization coming up after KubeCon. In the meantime, you feel free to add any specific features you would like to see on the repo. Find me on the OpenEBS community at @gila or on Twitter @jeffrymolanus.





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu