

As you may know from some of my talks, we feel strongly that applications have changed, yet someone forgot to tell storage. Since the inception of the OpenEBS project, we have been very keen on finding and exploring cloud native patterns because we feel that the world does not need yet another storage system. There are, arguably, already too many out there.
When initially talking to potential users, they all seemed to think that they needed a distributed storage system because, well, they need performance and capacity. I can't help but wonder why people are still looking? There are so many solutions already out there. Some are natively supported by the Linux kernel, such as OrangeFS, Coda, and OCFS2, with some of the brightest minds in the world working on them.
Then there are those that don't live in the kernel, but are open source, versatile and distributed nonetheless. For example, MooseFS, GlusterFS, Lustre …
Then there are proprietary systems, each of which have embraced cloud native as a market and a tag line, if not yet as an architecture.
So, should we start a new distributed storage system? No thank you! Not just because these systems are extremely difficult to build and mature and there are plenty of them already, but also because we realized years ago that you really do not need them.
The primary reason for this is that your applications are already distributed systems themselves, which is what I mean when I say they have changed. In the cloud native landscape, if you depend on your storage systems to scale your application, you might want to strongly reconsider your architecture.
There is one class of storage that does make perfect sense to distribute, and that is object storage. Not Ceph-like object storage, but rather S3-type object storage. It is ideal to store any type of static content, ranging from simple pictures for your WordPress blog to full backups of your databases, as native to the web.
Sometimes, this phenomenon is referred to as “flash or trash,” where the flash tier is needed for high throughput low latency workloads, whereas the latter is simply big and deep for storing anything and everything. Note that this does not mean that S3-type object storage is slow, as demonstrated by our OSS friends at Minio.
This also does not mean that there is no storage problem to solve. It simply means that the problem that requires solving is not in the domain of performance and capacity, but rather embracing new technology, understanding the workloads that need to be served, and targeting the right persona.
It is not just the software that is changing
In addition to the SW changes, HW is changing as well. Even though core frequency has been relatively stable, or stagnating at the very least, the amount of silicon keeps increasing. To actually use this silicon at its full potential, you have to understand to a certain extent, that “throwing more threads the problem” does not help. In fact, it can actually be counterproductive. This is the well-known concurrency vs parallelism concept, and we can see that concurrency primitives become first-class citizens of more modern programming languages that use “M:N” threading models. Now, I do not want to get into too much detail about that, but it suffices to say that this also impacts storage.
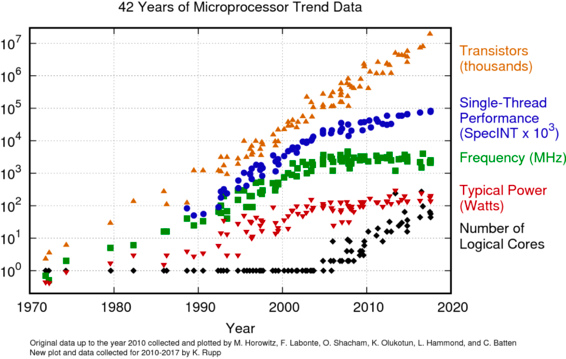 42 Years of Microprocessor Trend Data
42 Years of Microprocessor Trend Data
As storage or persistent media is becoming faster and faster, we also see that the way we interact with these devices needs to change. For example, DAX file systems have started to emerge where our trusty friend the page cache simply gets in our way. NVMe devices achieve DDR4 performances. With SCM, it looks as though the CPU is starting to become the bottleneck, whereas not too long ago, it was considered the opposite.
When we started the OpenEBS project, we knew that it was going to be important to leverage these technologies from day one as the changes in HW and SW are simply too big to monkey patch as responding to these changes requires fundamental changes throughout the entire IO stack.
So, instead of doing the performance dance with existing monolithic systems that would like nothing more than to have us play their ball game, we doubled down on understanding these new technologies and how we can leverage them in a meaningful way such that, for the developer, the system would let itself be composed by declarative intent. Get the workflow first, and optimize performance later.
We have now come to that second part. Now that OpenEBS is into the CNCF and the container attached category, though it was once ignored and even mocked, it is now accepted and widely deployed: let’s change the game again. With MayaStor, we are starting to show that the architecture we’ve built is also a far a better solution for achieving outsized performance as well, as always on a per workload and per team basis. Let’s dive into how we accomplish this.
NVMe
If you’d like to learn about the internals of NVMe and why we’ve built OpenEBS to be able to take advantage of NVMe, keep reading. It is fundamental, but I can imagine many of you want to skip ahead, so feel free to do so.
When you go over the implementation of the design specifications of NVMe, it refers to something called a subsystem. To try and explain this, consider the NVMe device you see in laptops. This could be anything that connects to your PCI bus, where the process of actual storing is handled by a set of NAND flash chips, or more generic: persistent media.
If you bisect the NVMe device, it consists, at a high level, of a controller, queues, namespaces, namespace IDs, and the actual media, with some form of an interface that is not relevant to us.
If you logically group the media into sections, we speak of namespaces. Namespaces are analogous to an OS partition, except the partitioning is done by the controller and not the OS. (You can have OS partitions on namespaces). Namespaces have an associated ID, which is an ordinal number.
However, some namespaces might be hidden from you, such that you see one namespace, but there are actually more. This is because flash needs to rotate between the cells to stay performant as it does not allow for immediate overwriting. The controller typically uses firmware to perform this "smart" rotation, garbage collection, etc. There are SSDs where this FW is entirely open, and you can develop your logic, but that is not something we are looking into at the moment.
The final piece is that the controller connects to a port through the set of queues and a namespace through their respective namespace IDs. In your laptop, this port is a PCIe port. In a fabric, this port can be a TCP, RDMA socket, or FC, and we speak of NVMe over Fabric (NVMe-oF)
A controller is allowed to connect to multiple namespaces, and a namespace is allowed to be controlled by multiple controllers and, therefore, multiple ports. I hope that you can start to see the reason for calling it a fabric as if you were to smear out this NVMe device into multiple computers, it is a fabric.
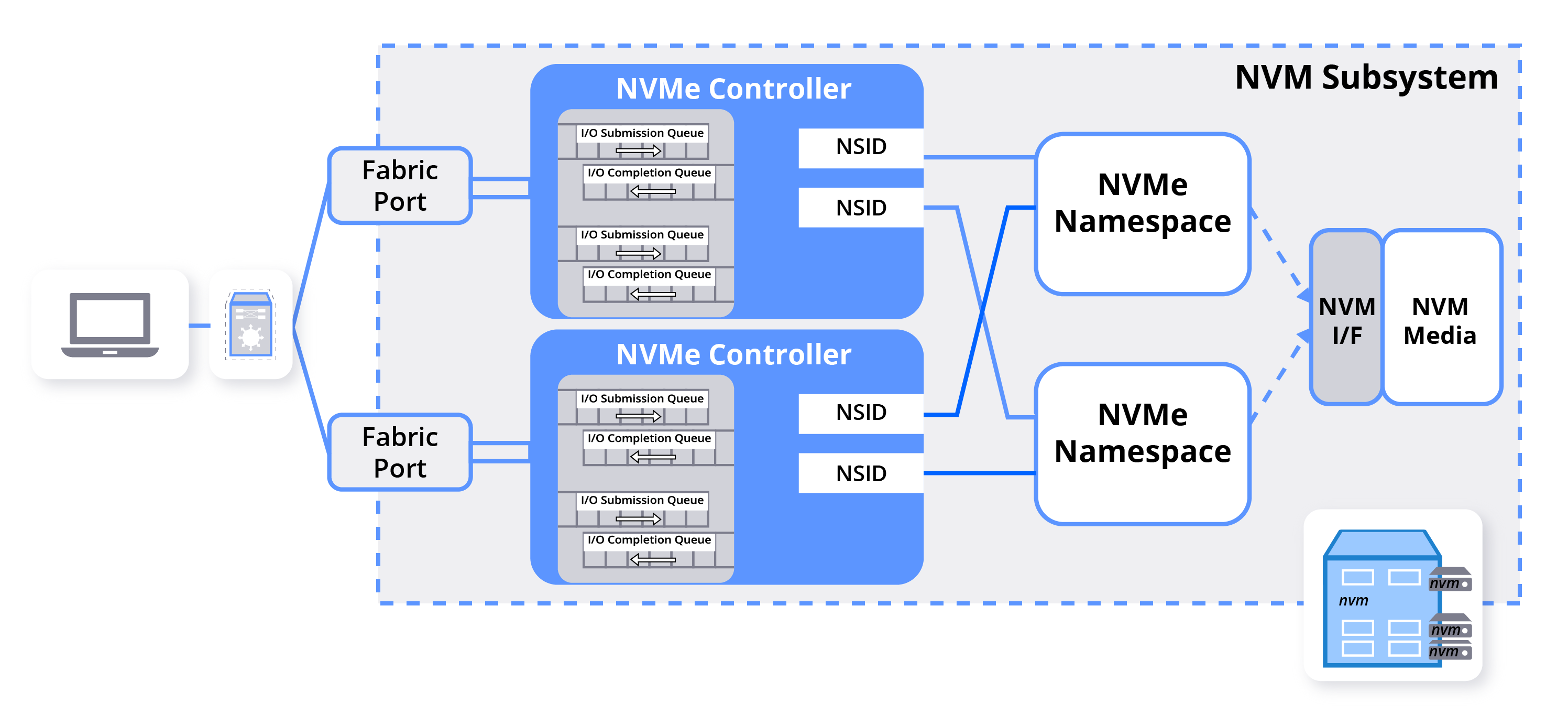 NVM Subsystems
NVM Subsystems
The internet has many good articles detailing what NVMe queues are, but what is essential to understand is that each CPU gets its private queue to communicate with the device. Because of shared nothing design, it is capable of achieving high speeds as there are no locks between queues that live on the cores. If you were to have more than one controller, each controller would get its own set of queues per CPU. It is this design that allows us to achieve high IOPS numbers as the number of cores continually increases.
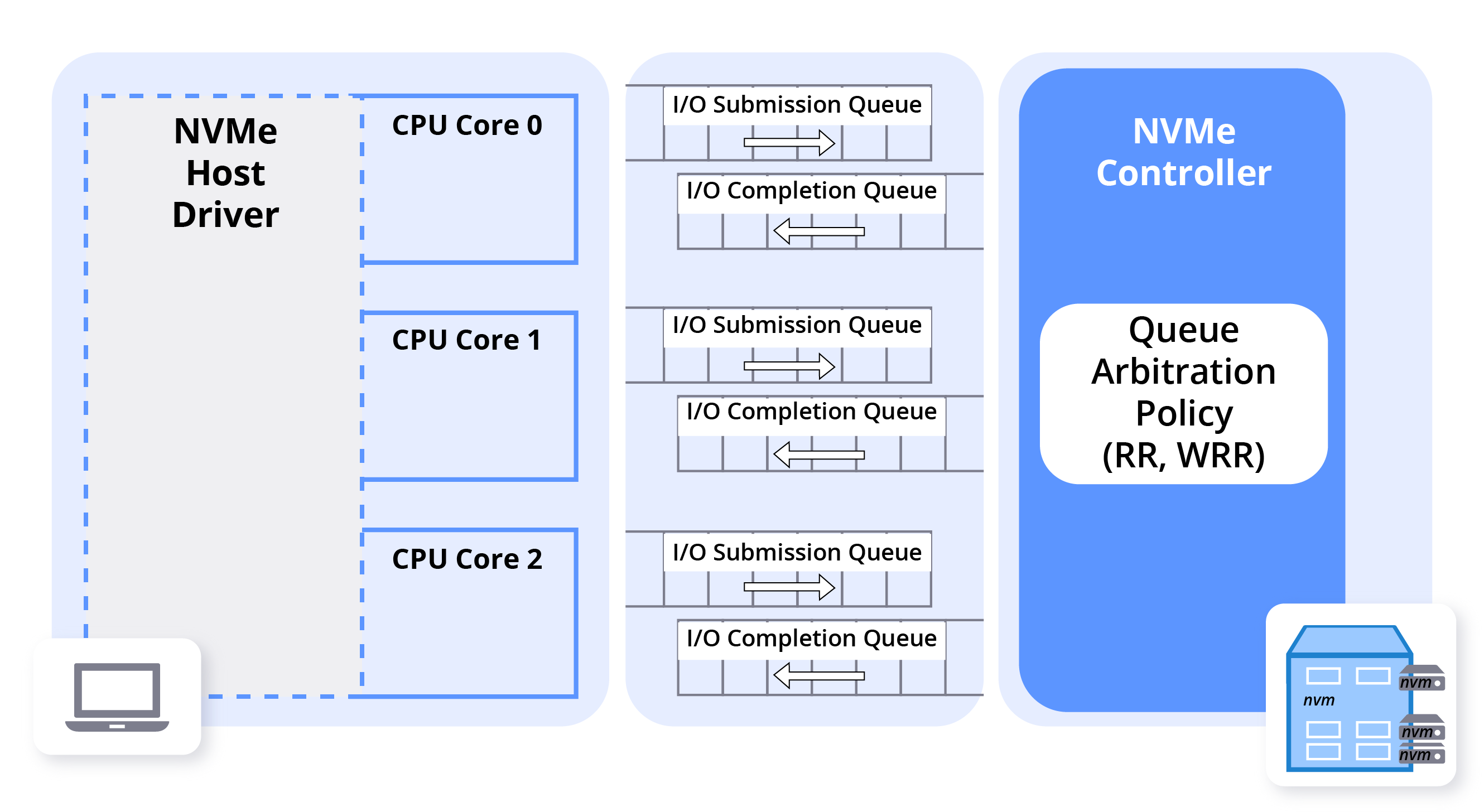 NVMe Controller Architecture
NVMe Controller Architecture
As an aside, The Linux kernel is starting to make use of this approach in many places and recently received a completely new asynchronous IO system called io_uring. In particular, the latter is an entirely new implementation of more or less doing the same thing as before, but where the implementation needs to be different to saturate the HW. It uses the same underpinnings as found in the NVMe protocol.
How we Implement OpenEBS CAS with NVMe
With MayaStor, we move to the next logical extreme of Container Attached Storage (CAS), where we containerize the NVMe subsystems. We ad-hoc, slice and dice your persistent media into controllers, namespaces, subsystems, NQNs, and ports.
We use NVMF to connect PVCs on different nodes with one another. Note that the actual storage devices we use, which are not necessarily supplied by us, can be existing iSCSI LU's, local SSDs, or existing NVMF devices. We do not care, we abstract away the underlying storage infrastructure just as k8s abstracts away your compute infrastructure.
Even if the devices are rotational and won't need NVMF in terms of performance, we will still use NVMF to connect them: it is our core fabric that connects and binds all of the block devices and PVCs together. Internally, we are able (but not required) to pool the storage media together and slice out volumes from the pool, not unlike the OpenEBS cStor engine does today. The volumes provide the basics for snapshotting, cloning and thin provisioning. These volumes are then exposed through a port over the network.
This part of MayaStor is what we refer to as the Storage Service. It simply makes storage available, whatever it is, over the network to mayastor itself. Please keep in mind that we run all of this fully in userspace, and we do not require any support from the host to construct these storage services. Perhaps redundantly, existing in userspace is important, not because you cannot do it in the kernel, but because you don't want to depend on the kernel for access. An Ubuntu kernel in GKE is not the same as an Ubuntu kernel in AWS. It is an excellent kernel for sure but is simply different. Operating in userspace allows us to abstract away these differences.
Once we have the Storage Services setup, the next step is to tie them together. This is where the Nexus driver comes into play. It is our interface that can connect one or more storage services together and, therefore, allows us to construct a 3-way replica. In turn, the nexus driver can be exported by a variety of protocols (more about that later).
Rust
To be honest, I only happened to stumble upon RUST. For a large portion of my career (if you can call it that), I’ve been using C/C++ and I was browsing some talks from cppnow to learn more about “what's new.” As I was working with a video in the background, along came Niko, who started talking about the problems with C++ and, well, one thing led to another and now here I am trying to explain how we make use of it.
MayaStor is very callback driven (hopefully we can move towards await in the future), Also, we use closures in RUST to construct, for example a Nexus device. To keep things simple, it looks similar to this with a single replica:
| // signature of nexus_create pub fn nexus_create<F>(args: NexusArgs, f: F) where F: FnOnce(Result<NvmeCreateCtx, i32>) // a simplified nvmf URI if let Some(n) = NvmfUri::new("nvmf://node1/uuid") { if let Ok(args) = NvmfArgs::try_from(n) { nexus_create(args, | result | { // look for the Storage Service Target which // is already created by the CSI driver }); } } |
The Nexus will then “route” the IO towards the target, where the target is hosted on a k8s node, which is, in turn, exposing its storage media on a different NVMe subsystem. The pod that claims the PVC is connected to the Nexus, and the Nexus itself is represented as a CRD. The CRD can be patched, so we can add/remove replicas over time to achieve data mobility. There is quite a bit going on under the hood here. For example, we determine whether we actually need to go over the network or not, but I hope to come back to discuss more implementation details once the code is out.
Let’s assume for a second we have a 3-way replica. Internally, the Nexus knows to what NvmfURI’s it should connect and is connected to. This means that replication (oversimplified) is a matter of:
|
pub (crate) fn bio_sumbit( READ => { .... }, } } |
Here, RUST helps by allowing us to build safe abstractions on top of inherently unsafe code. We deal a lot with scatter-gather lists of IO, and if we keep those code pieces small and encapsulated in unsafe{}, and provide higher functions to operate on the data, the location of possible errors concentrates within the unsafe blocks. This makes code review and the addition of new features less risky. Despite a steep learning curve, we are already starting to see the benefits.
Nexus
Another thing I would like to mention related to Nexus is that it speaks multiple protocols. So, this means that northbound, it does not have to speak NVMF. One of the reasons I mention this explicitly is the rise of micro VM technology such as firecracker, rust-vmm and kata containers. Systems like these leverage existing hypervisor technology to address gaping holes in containers and make them less of a problem. They typically use virtio so that you can directly connect your micro VM to bypassing fabric. Figuring out how “best to connect” is part of the control plane and allows us to form a data mesh where the actual connection types are abstracted away.
MOAC
To orchestrate this, we also redesigned a control plane that speaks CSI from the get-go, called Mother of All CAS (MOAC). When the OpenEBS project started, there was no CSI, so we had to implement this from scratch, yet there are still shortcomings in CSI when evaluated against what we need to do for certain use cases. However, the basics of CSI do make sense for our applications as it only dictates an interface, not an implementation. At the control plane level, MayaStor provides 2 additional CRDs:
- Pool CRD, which describes the storage pool that is used where we carve out volumes that are being used as targets for the nexus.
- MayaStor Volume CRD, which describes, in detail, the topology of the volume itself. This means that it reflects what or who the nexus is connected to, its state, number of replicas, etc.
Before you can create MayaStor PVCs, a pool must be created. To do this, we have implemented additional gRPC methods next to CSI that directly talk to the nodes.
| cat <<EOF | kubectl create -f - apiVersion: "openebs.io/v1alpha1" kind: MayastorPool metadata: name: pool spec: node: node1 disks: ["/dev/vdb"] EOF |
This will result in a pool that looks something like this:
Name: pool Namespace: Labels: <none> Annotations: <none> API Version: openebs.io/v1alpha1 Kind: MayastorPool Metadata: Creation Timestamp: 2019-04-09T21:41:47Z Generation: 1 Resource Version: 1281064 Self Link: /apis/openebs.io/v1alpha1/mayastorpools/pool UID: 46aa02bf-5b10-11e9-9825-589cfc0d76a7 Spec: Disks: /dev/vdb Node: node1 Status: Capacity: 10724835328 Reason: State: ONLINE Used: 0 Events: <none> |
Once the pool has been created, we can construct a PVC that MOAC will schedule using some heuristics on the best node(s). The most simplistic algorithm here is to use first fit on the nodes that have the lowest active volume count. However, over time more sophisticated algorithms will be added as we continually collect more runtime information from the nodes to determine the best fit.
On the selected nodes, MOAC will create a Storage Service Target (SST) and expose that over NVMe. We are given a UUID through the dynamic provisioner, so all replicas will be internally referenceable by that UUID. The next steps are then to create a storage class and PVC:
| cat <<EOF | kubectl create -f - kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: mayastor provisioner: io.openebs.csi-mayastor EOF |
| cat <<EOF | kubectl create -f - apiVersion: v1 kind: PersistentVolumeClaim metadata: name: ms-volume-claim spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi storageClassName: mayastor EOF |
Finally, we can start a POD that consumes the PVC using, for example, FIO:
| cat <<EOF | kubectl create -f - kind: Pod apiVersion: v1 metadata: name: fio spec: volumes: - name: ms-volume persistentVolumeClaim: claimName: ms-volume-claim containers: - name: fio image: dmonakhov/alpine-fio args: - sleep - "1000000" volumeMounts: - mountPath: "/volume" name: ms-volume EOF |
Taking It for a Spin
The reason for all this was to raise the performance to a level where it realistically needs to be. So, where is “it” and how do we determine “it”? Depending on what features you wish to use (i.e replication, encryption, etc), the performance degradation for a single replica should not be higher than, what? As a matter of fact, while writing all this, we had a bet among each other for free drinks to guess what the overhead would be.
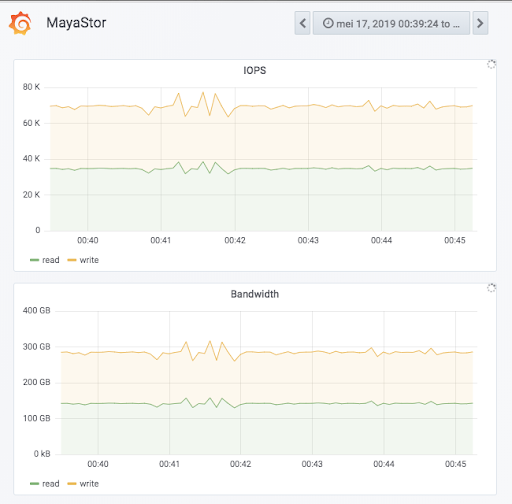
We had a device that was, on paper, capable of doing somewhere around 100K IOPS. When we put Mayastor on top of that using FIO, the workload was run as 100% read, 100% write, and finally 50/50 random read-write, and we saw 0% overhead.
This brings me to a problem. Not everyone is able and capable of running NVMF (yet), even though NVMF-TCP has been available for quite some time. Though it takes some time for this to trickle down and stabilize. So, for the last KubeCon, we added NBD support for the Nexus, which allows people to use MayaStor with NBD without NVMF.
Do reach out to us over slack with your comments and Feedback.





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu