

Last week, I was invited to give a talk about OpenEBS during the Kubernetes meetup in Berlin. The event was hosted by the friendly folks at Profitbricks, who once again I want to thank for the lovely venue and experience. Matt Baldwin, from our friends at StackPoint Cloud, was once again an organizer — thank you Matt for your ongoing support of the community (and of OpenEBS as well).

As we went over some of the nitty-gritty details on how we are building OpenEBS, I received a few questions that I thought deserved an extended response. I will address one of those here.
A common question was: “If I’m running on an <insert cloud vendor> system, what is the benefit of OpenEBS?”
So, let’s dive into one of the biggest questions— what if you are running on AWS and you are using EBS volumes, why use OpenEBS on top?
First of all, we already made the implicit assumption that if you were to run an application managed by Kubernetes, you are using EBS volumes. But, this assumption does not have to be true. In fact, if you want fast and performant storage, AWS suggests that you use optimized storage instances, meaning *not using EBS* volumes at all.
The EBS volumes are not the fastest thing you can get from AWS, but they do provide replication across zones and snapshots. This brings me to the second part, a snapshot, in AWS, is stored in S3. That bill (depending on dataset size) can quickly and easily pile up with the number of snaps. With OpenEBS, we store the snapshot locally on the volume itself, and we don’t require you to “copy” this into S3 or a similar location. Also, consider the amount of time it takes for a snapshot to be created in AWS; it can take hours and the snapshot restores require you to attach a new EBS volume. Moreover, if you do these types of things, you have to “fiddle” with the OS to get it attached, something that OpenEBS handles for you, making snapshots instantly and allowing you to rollback immediately.
There is also the matter of granularity; with OpenEBS, you can control everything per application or even per workload. You can fine-tune the replication factors (or not have it all) and you can use just one EBS volume for all your apps since OpenEBS handles the slicing and dicing for you.
So, this was about using EBS volumes, I hope the advantages are apparent and easy to understand. This brings data agility to your applications, not just in AWS, but also across clouds: public, private or hybrid. The developer does not have to make any changes to his or her YAML, and can write once and run everywhere, precisely what containers are supposed to do. Do not let others take that freedom away from you =)
Back to the non-EBS volumes, what AWS refers to as “instance store.” More information from Amazon:
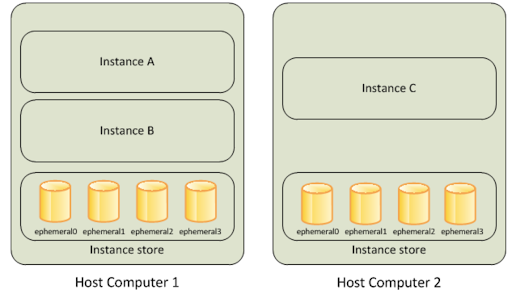
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/InstanceStorage.html
As the docs point out, when you use this, you get high speed with zero features. With OpenEBS, you get high speed and all of the features if you delegate control of the “instance store” to OpenEBS. An interesting note, the instance store comes with the price of the machine instance itself, so there are no extra charges on your bill.
In a future blog I’ll cover some other common questions that arose — and I’m also going to continue talking about the shift of IO and so forth to the user space, and what it may mean for Container Attached Storage and running IO intensive workloads in general.
Feel free to ask any questions below, or maybe I’ll see you on the OpenEBS slack community where we are discussing many related subjects.
This article was first published on Jun 1, 2018 on OpenEBS's Medium Account





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu