

OpenEBS Jiva Volumes are a great way to provide highly available persistent volumes to Kubernetes stateful workloads by making use of the local storage available on each node. Installing and setting up OpenEBS is very easy, almost like running just another application in Kubernetes Cluster. Of course, the best part is that OpenEBS Jiva volumes are completely Kubernetes Native and can be managed directly via kubectl.
For setting up OpenEBS and using Jiva volumes, please refer to this documentation.
In this blog, I will focus on some of the common questions that come up in the OpenEBS Users Slack channel, related to running Jiva volumes in production.
Overview of Jiva Volumes
Before we get into the specifics, OpenEBS Jiva volumes are implemented with microservices/containers and comprise of two main components, as depicted in the following diagram.
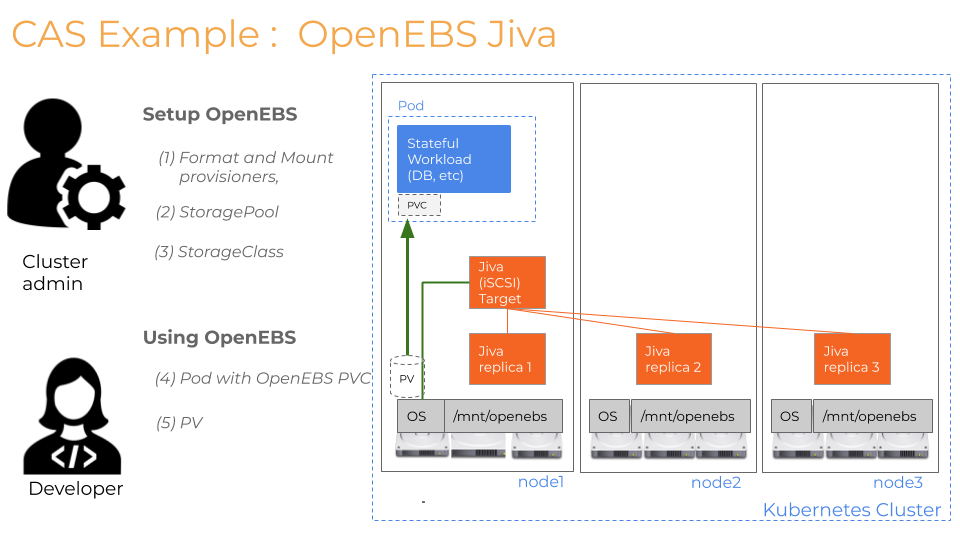
- Jiva Controller is responsible for serving the data to the application by contacting the Jiva Replicas from different nodes. Jiva controller does synchronous replication to all the replicas. To extend this further, a copy of the data is sent to all the nodes.
- Jiva Replica is responsible for saving the data on the local storage on the nodes and maintain data consistency. Rebuild the data from other replicas after recovering from a failure. Note that Replica’s once scheduled on to a node remain on that node. They are pinned to the node using the hostname label.
The health of the Jiva Volume can be checked by using mayactl, which provides details status of the controller and the replicas. A sample output looks as follows:
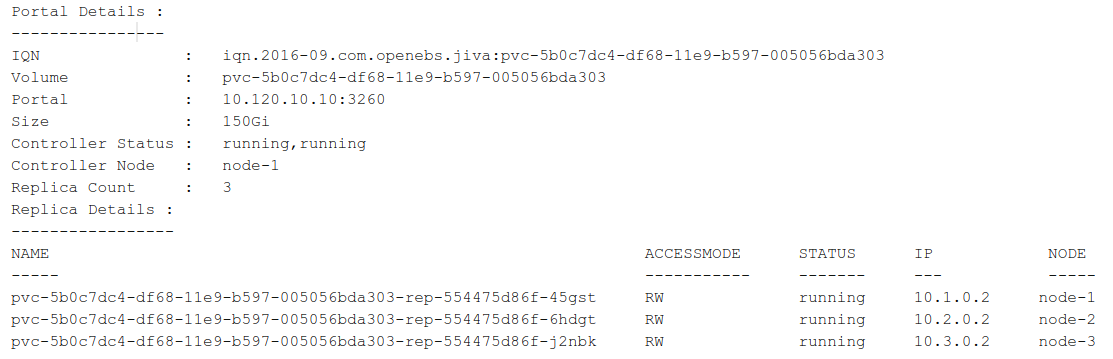
mayactl describe volume
More information on how to run mayactl is available in the OpenEBS Docs.
Understanding the Replica Status
A Replica is considered healthy if it is in RW State.
OpenEBS Jiva Controller checks that a minimum of 51% of its replicas is healthy (aka RW) for serving the data to the application. So if there are three replicas, then for a volume to be available, at least two out of three replicas must be in RW state.
Due to cluster conditions like a node shutdown or loss of network connectivity, a replica can go into the following states:
- NA — This indicates that the controller is no longer able to contact the replica and vice versa.
- WO (Write Only) — This indicates that the replica has just restarted either due to network loss or node shutdown, and is in the process of rebuilding the data from other replicas.
WO is a valid state and will remain in this state, till all the data is rebuilt. In the current version, if the Replica is lagging behind from the healthy replica, then a full rebuild is initiated. The time taken to rebuild depends on the amount of the data, the speed of the network, and the storage.
The replicas that are stuck in the NA state need some manual intervention. The NA state can be due to the following scenarios:
- The replica pod is hung or is unable to make any outgoing connections to the controller. In this case, restarting the replica pod can help.
- The node on which the replica pod has been taken out from the cluster. In this case, the replica deployment node affinity needs to be updated so that the replica pod can be scheduled to a new node in the cluster, that replaced the older node. The steps to recover from this scenario are mentioned below.
- In case all the replicas are in NA state, this indicates an issue with the controller pod unable to respond to the replica requests or controller pod is down, or all the nodes are down where replicas are scheduled. If the controller remains down for a very long time scheduling it on another node will help.
Recover from NA if replica pod is in the pending state
Note: We use Node Affinity to pin the replica on the desired worker nodes to avoid multiple copies of data across more than the desired number of replication and also to optimize the rebuilding process.
Prerequisites:
- Min n/2+1 replicas should be up and healthy (RW) to ensure volume is up, where n is the replication factor. For exp, if Replication factor = 3, min 2 replicas should be up and healthy.
Here are the steps to schedule replica on the other node:
- kubectl get deployment -n <ns_of_pvc> (get the deployment of the replica that requires scheduling {say replica_deployment})
- kubectl get pods -n <ns_of_pvc> -o wide (get the name of the node from where you want to detach the replica {say N3})
- kubectl edit deployment <replica_deployment> -n <ns_of_pvc>
- Now replace the worker node(N3) from the following field with the new worker node N4
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
— N1
— N2
— N3 (replace with N4)5. Now save and exit, and you will notice a new replica pod will be scheduled to the new worker node.
Another multi-failure scenario to consider is that if multiple replicas remain in the non-healthy state for a longer duration, the application node can mark the volume as read-only. After using the above resolution steps to bring back the volume to a healthy state, a manual step needs to be performed on the application node to make the volume as read-write again. The steps for recovering from the read-only states are available in the OpenEBS Troubleshooting section.
Upcoming Enhancements
Optimizing the rebuild to reduce the time taken for a replica to go from WO to RW state. Also, right now, I am actively working on a Jiva Operator that can help automatically recovering the replicas that are stuck in the NA state — due to a complete node failure.
Feel free to reach out to me to learn about the internals of Jiva or providing feedback and suggestions to improve your experience with OpenEBS Jiva volumes.
Thank you, Kiran Mova, for your valuable suggestions and edits.





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu