


For a while now, we have been saying that OpenEBS Mayastor is “high” performance and community members have written blogs showing that the performance of OpenEBS Mayastor indeed is much better or on par with others even when running on relatively slow cloud volumes. However, is Mayastor high performance or just “as fast” as the other things out there?
It used to be the case that CPUs were much faster than the storage systems they served. With modern NVMe, this does not have to be the case anymore. NVMe is a protocol that can go fast but does not have to be fast. What this means is that you can use NVMe as your transport protocol for any block device, not just flash. Yes, this is what Mayastor does. It is really useful to keep in mind the distinction between NVMe as a protocol and NVMe devices - you don’t need to use them together but, when you do, additional performance can be unlocked.
If you’d like to jump right to a recorded demo and explanation, please watch Glen Bullingham, Director of Product Management recorded for Intel’s Memory and Storage Moment in late 2020
In this blog, we will be using Mayastor to try out some of the fastest NVMe devices currently available on the market and see how we perform on top of these devices within k8s, using the container attached storage approach for which OpenEBS is well known. We will show what happens when you marry NVMe as a protocol (embedded within Mayastor) and fast NVMe devices from our friends at Intel.
Before we get started, you might wonder how we came to this point that a new project like OpenEBS Mayastor was able to deliver amongst the fastest storage available today. Richard Elling of Viking / Sanmina recently wrote an excellent blog on the trends in hardware design that puts NVMe and OpenEBS Mayastor into context: https://richardelling.substack.com/p/the-pendulum-swings-hard-towards
Hardware setup
Let’s get to it. We will be using three machines which will run kernel version 5.8. The hardware configuration of each host is as follows:
- Intel(R) Xeon(R) Gold 6252 CPU @ 2.10GHz
- Intel Corporation NVMe Datacenter SSD [Optane]
- Mellanox Technologies MT28908 Family [ConnectX-6]
Baseline performance
To understand the performance of the device we will be using throughout the test, we run the following Fio workload:
[global]
ioengine=linuxaio
thread=1
group_reporting=1
direct=1
norandommap=1
bs=4k
numjobs=8
time_based=1
ramp_time=0
runtime=300
iodepth=64
[random-read-QD64]
filename=/dev/nvme1n1
rw=randread
stonewall
[random-write-QD64]
filename=/dev/nvme1n1
rw=randwrite
stonewall
[random-rw-QD64]
filename=/dev/nvme1n1
rw=randrw
stonewall
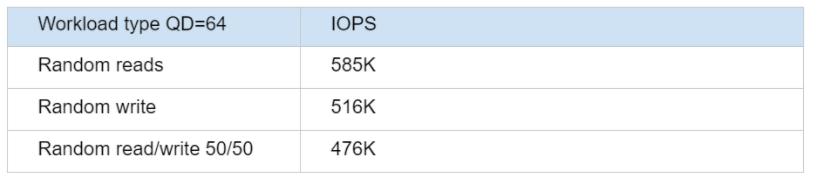
These numbers are incredibly high and are provided by a single device. Note that the benchmark itself is rather synthetic in the sense that, in practice, no workload is 100% random.
High-level overview of the experiments
My approach in this benchmarking is very much OpenEBS Mayastor “the hard way”. If you want an easier to use solution that for example automates pool creation and device selection and so on - we call that offering Kubera Propel (also open source btw). You can learn more about Kubera Propel on the MayaData.io web site.
On two of the nodes, we create a pool (MSP CRD) which we use in the control plane to determine replica placement. To construct pools, we must have what we call a persistence layer. We support several ways to access this persistence layer. To select a particular scheme we use URIs. In this case we will be using today the pcie:/// scheme. This means that Mayastor will directly write into the NVMe devices listed above. The nice thing is that from the user perspective, things do not change that much. We simply replace disks: [‘/dev/nvme0n1’] with disks: [‘pcie:///80:00.0’]. Note that this persistence layer is used to store the replicas of the PVC. Once we have this layer up and running, we will create storage classes and select that we want to use nvmf (NVMe-oF) as the transport layer between the replicas, resulting in NVMe all the way through.
After we have deployed mayastor we applied to following two storage classes:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: nvmf
parameters:
repl: '1'
protocol: 'nvmf'
provisioner: io.openebs.csi-mayastor
---kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: nvmf-mirror
parameters:
repl: '2'
protocol: 'nvmf'
provisioner: io.openebs.csi-mayastor
Note that `protocol: `nvmf` is just a shorthand for the NVMe-oF format mentioned above. We will be using both storage classes to run a single replica followed by a two way replica AKA mirror. We use the following YAML to create the volume.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ms-volume-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100G
storageClassName: nvmfAfter creating the PVC, Mayastor’s control plane creates a CRD, “Mayastor Volume” (MSV), that contains additional information about the corresponding volume. Using kubectl describe msv -n mayastor we get:
Name: ba081dc3-46db-445b-969c-7e5245aba146
Namespace: mayastor
Labels: <none>
Annotations: <none>
API Version: openebs.io/v1alpha1
Kind: MayastorVolume
Metadata:
Creation Timestamp: 2020-09-11T08:49:30Z
Generation: 1
Managed Fields:
API Version: openebs.io/v1alpha1
Fields Type: FieldsV1
fieldsV1:
f:spec:
.:
f:limitBytes:
f:preferredNodes:
f:replicaCount:
f:requiredBytes:
f:requiredNodes:
f:status:
.:
f:nexus:
.:
f:children:
f:deviceUri:
f:state:
f:node:
f:reason:
f:replicas:
f:size:
f:state:
Manager: unknown
Operation: Update
Time: 2020-09-11T08:51:18Z
Resource Version: 56571
Self Link: /apis/openebs.io/v1alpha1/namespaces/mayastor/mayastorvolumes/ba081dc3-46db-445b-969c-7e5245aba146
UID: 94e11d58-fed9-44c9-9368-95b6f0712ddf
Spec:
Limit Bytes: 0
Preferred Nodes:
Replica Count: 1
Required Bytes: 100000000000
Required Nodes:
Status:
Nexus:
Children:
State: CHILD_ONLINE
Uri: bdev:///ba081dc3-46db-445b-969c-7e5245aba146
Device Uri: nvmf://x.y.z.y:8420/nqn.2019-05.io.openebs:nexus-ba081dc3-46db-445b-969c-7e5245aba146
State: NEXUS_ONLINE
Node: atsnode3
Reason:
Replicas:
Node: node3
Offline: false
Pool: pool-atsnode3
Uri: bdev:///ba081dc3-46db-445b-969c-7e5245aba146
Size: 100000000000
State: healthy
Events: <none>Results single replica
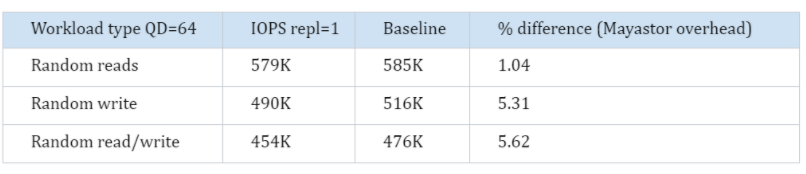
From the results we can see that we are very close to the performance of the local device. To be sure we can put it in the right perspective, the difference between the experiments here is that with the baseline, the workload was local. With repl=1 we use the same NVMe device but export it through our pool layer (and thus provide volume management), but also go over the network.
Results 2 replicas (mirror)
We are going to repeat the same test, this time, we will use two replicas. As we now have double the disks bandwidth, we expect to see that the read performance will go up. For writes, however, we actually expect a drop in performance, because we must do each write to both disks before we can acknowledge the IO. Note that Mayastor does not cache - if you read the blog referenced above from Richard Elling you can learn why caching seems to be falling out of favor for use cases in which millions of IOPS are desired.
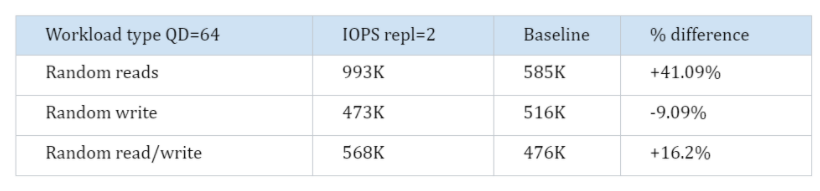
Wrapup
With the above experiments, we have demonstrated that with OpenEBS Mayastor we have built a foundational layer that allows us to abstract storage in a way that Kubernetes abstracts compute. While doing so, the user can focus on what's important -- deploying and operating stateful workloads.
If you’re interested in trying out Mayastor for yourself, instructions for how to setup your own cluster, and run a benchmark like `fio` may be found at mayastor.gitbook.io/.
And if you are a Kubera Propel user, you’ll find that we’ve productized some of the benchmarking above so that platform teams and other users can programmatically use benchmarks in their decisions about workload placement. We are working with a number of users about operating OpenEBS Mayastor / Kubera Propel at scale. Please get in touch if you have suggestions, feedback, ideas for interesting use cases and so on. Contributions of all kinds are welcome!





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu