

My expectations of KubeCon North America 2018 were high, and it passed with flying colors. It was the busiest I’ve ever been at a show — and I’ve been to quite a few.

In this blog, I’ll look back on the discussions we had and the questions we fielded; I hope you’ll agree that they provide a useful window into how Kubernetes adoption is changing as it spreads.
Kubernetes has graduated in the field
The enterprise adoption of Kubernetes is clearly visible when you face questions like — “We are running Kafka on a 20 node Kubernetes cluster, it is time to upgrade Kubernetes from 1.8 to 1.12, we are exploring using a blue-green deployment approach for our Kafka workloads across these clusters. Do you have anything to offer?”

Kubernetes
Many users have moved from just exploring the idea of stateful workloads to resolving challenges around stateful application upgrades in a DevOps friendly way,(try that with your traditional storage :)). It is also apparent that stateful applications are receiving maximum coverage of discussions around DevOps teams. For example, the Cloud Native Storage day was oversubscribed more than 10 times. When we started OpenEBS a couple of years ago, with the crazy idea of taking an open source cloud-native approach to delivering storage and data management in Cloud Native environments, I hoped but never expected this kind of interest. Who would have imagined that there could be 600+ KubeCon attendees on a waiting list for the Cloud Native Storage day?
Observability
Next observation you cannot miss is the sheer number of booths that showcased observability and related solutions around Kubernetes. Some are just about logs; some are just about metrics, some are a mix of logs, metrics, and tracing, etc. But, it directly shows the readiness of Kubernetes for mainstream adoption for data sensitive applications or stateful applications. The Cortex project which recently made it to CNCF sandbox is starting to gain many takers as a large-scale Prometheus metrics platform. And of course, Uber used their main stage time to talk about their project for very large scale Prometheus data management.
https://schd.ws/hosted_files/kccna18/5e/Smooth%20Operator.pdf
One of our favorite questions to a Kubernetes user is: “Are you running stateful workloads?” If the answer is “well, not really…” then we inevitably ask, “What about Prometheus and Elastic?”.
You know if Uber has spent years and many millions building a data management platform for Prometheus that works around the current limitations of block storage (which we are fixing!), then pretty clearly the trend of observing everything via Prometheus and similar systems running on Kubernetes is helping to drive a reevaluation of storage architectures.

Cloud is no longer the buzz word, today’s newness is multi-cloud
Container Attached Storage or Cloud Native Storage also seem to have gained mainstream adoption and conversations which are leading towards data management as opposed to simple data connectivity. It was nice to see most of the sponsor companies in the CNS day, emphasizing data portability and anti-data gravity on clouds so that users do not get into cloud lock-in. While Kubernetes has enabled the adoption of a multi-cloud vision, it is now starting to be understood that a common data layer is required to enable true data portability, and achieve stateful application portability across Kubernetes clusters.
In this context, multi-cluster use cases seem to be the most common among DevOps admin, triggered by Kubernetes platform upgrades or just by treating clusters as disposable abstractions much as pods themselves have been. You even hear of Kubernetes being used to schedule Kubernetes which will make this pattern of disposable clusters more common and possibly easier to manage at scale.
As we all know, Kubernetes release cycles are often happening and meanwhile stateful applications (take for example Kafka), do not easily support upgrades across K8s versions. If you are running K8S 1.9 and want to move directly to 1.13, stateful applications break in the Blue-Green deployment scenario, as they are tested and certified for only incremental upgrades of K8s versions. DevOps admins are taking the approach of setting up a new K8s Cluster with 1.13 version and do the blue-green deployment scenario between the two clusters. Being able to setup access to the common data for both clusters, here is the key need/challenge. Data portability across two clusters with incremental snapshots, synching between Blue and Green clusters is a common use case now for our cStor engine within OpenEBS.
The key takeaway here is, we are moving from the times of “how do we keep the stateful application always connected?” to “how do we keep the same data available between the two clusters during upgrades?”
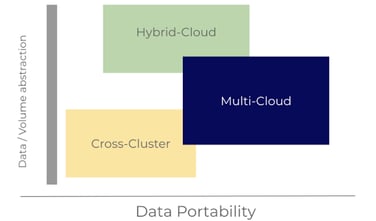
Data Portability needs data or volume abstraction and leads true multi-cloud
As one user at our booth put it very aptly
“I want to write my application data to a volume where the volume is abstracted from the underlying cloud providers.”
Adoption of our own OpenEBS project
While our analytics say there are hundreds of thousands of OpenEBS installations (based on recently added initial call home pings), it is still a bit hard to understand how they are being used in production, especially at a time when you are just announcing the commercial availability in KubeCon. We have created an ongoing survey that readers can contribute to in 2–3 minutes to help us learn more about use cases:
https://www.surveymonkey.com/r/BRDCCWY
So, while we have some metrics, surveys, and good chats with users on Slack and remotely, nothing beats the experience of a happy (or mostly happy) user stopping by to say hello and thank you. As an example, I got to meet Vasiliy Lukyanets, who has been running OpenEBS on a 20 node KubeAdm, managed Kubernetes cluster on AWS for RabbitMq, Kafka and Jenkins and some other workloads. All running more than 2TB of production data and for around 6 months now. Open source rocks, always!!

Last year OpenEBS received some recognition as the easiest to run cloud native storage. And this was further confirmed at the CNS day as user Ryan Luckie from Cisco spun up a multi-node deployment of PostgreSQL with the help of a fresh install of OpenEBS in less than 20 seconds in his talk. He also walks through their evaluation of alternatives and why they selected OpenEBS:
You’ll also note that support for enabling state even though clusters were disposable was a requirement.

For the last year, our focus has been on day 2 operations. To that end, we are innovating at many levels. Within OpenEBS, operators are being made available to manage the volume and disk resources and then above OpenEBS, new offers like DMaaS are made available which builds upon Heptio Ark and the COW snapshot capability of OpenEBS to enable per workload mobility and control of backup and restore.
Community is paramount. Of course, we have the beginnings of the community helping each other organically and sharing the best practices around data management. The feedback from the users around data management has started pouring in. Maybe by next North America KubeCon, OpenEBS will be rewarded as the easiest to use data management solution as well. Thanks a bunch to the OpenEBS community!!
This article was originally published on Dec 21, 2018 on OpenEBS's Medium account





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu