

Last week we saw the culmination of an enormous amount of work by ourselves — and by partners such as IBM and many other users of OpenEBS — culminating in releases across the open source projects we primarily support, OpenEBS and Litmus, and the launch of our commercial offering which we call MDAP.

You can learn more about progress in each area:
- Our new MDAP offering: https://mayadata.io/mdap
- OpenEBS 0.7 — a blog by our chief architect Kiran Mova: https://blog.openebs.io/openebs-0-7-release-pushes-cstor-storage-engine-to-field-trials-1c41e6ad8c91
- Litmus and OpenEBS.ci — a blog by our founder and COO Uma: https://medium.com/mayadata/chaos-engineering-of-stateful-applications-simplified-with-mayaonline-899c5e2b0c0a
- Our joint offering with IBM — a web site with some resources here:
https://www.ibm.com/us-en/marketplace/openebs-cloud-native-storage
TL;DR: https://www.ibm.com/us-en/marketplace/openebs-cloud-native-storage/resources
.png?width=2400&name=Untitled%20design%20(11).png) OpenEBS on IBM Cloud Private
OpenEBS on IBM Cloud Private
A primary topic at the booth last week was “use” cases as in — how the heck are people using OpenEBS? Perhaps the most common “use” case we have encountered has been adding resilience to underlying storage services from AWS and others often while using less expensive attached disks on these services.
You can read a how-to blog here on running OpenEBS on AWS in this way on the OpenEBS blog here: blog.openEBS.io
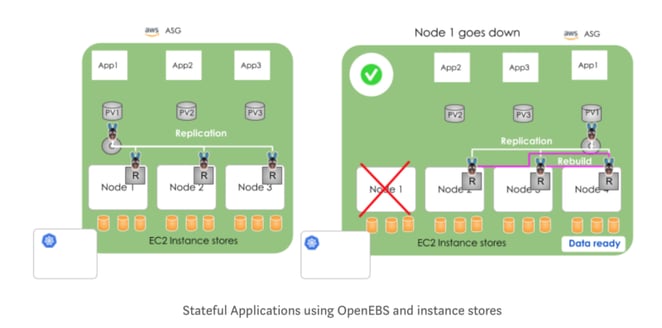
We also had a chat with some users who have started running OpenEBS with NoSql. There seem to be two main reasons these users are using OpenEBS with NoSql — which already has data resilience features built in:
- Cloud independence: the first is to add another additional level of abstraction so that when cloud environments are moved there is no impact on engineers. We heard for example from a large governmental user that they had a mandate to be cloud independent, which is why they have moved to Kubernetes and are investigating the use of the open service broker as a way to further abstract cloud-specific calls.
- Simplified Local Storage Management for Local PV and storage like OpenEBS using NDM: As OpenEBS depends on Kubernetes as the storage substrate we are always looking at ways to improve Kubernetes itself. To be clear, we are already benefiting tremendously by the upstream work done by the broader community. We also seek to do our part through projects such as node disk manager (NDM) which can enable Kubernetes to treat disks and underlying storage services and so forth as Kubernetes objects. NDM can be used for automating the provisioning and management of local PVs uniformly across different Kubernetes platforms. Beginning with OpenEBS 0.7 it is easy to use OpenEBS for capabilities such as NDM. You can read more about the usage of NDM within OpenEBS in Kiran’s blog here: https://blog.openebs.io/openebs-0-7-release-pushes-cstor-storage-engine-to-field-trials-1c41e6ad8c91
And you can also read about the April beta release of Local Volumes as a capability within Kubernetes here: https://kubernetes.io/blog/2018/04/13/local-persistent-volumes-beta/
We wrote about these and other “use” cases on the jointly created IBM subsite for OpenEBS here: https://www.ibm.com/us-en/marketplace/openebs-cloud-native-storage
In a sense, with OpenEBS 0.7 we are releasing two storage engines — one is enabling Local PV and the other — still in Alpha — is our cStor. cStor is also open source, and unlike Jiva, which is written in Go, cStor is written in — you guessed it — C.
cStor is rapidly accumulating production hours and is already shown to improve upon our existing Jiva in a few ways including better read performance (performance is yet to be optimized by the way) and an end to end data integrity. As cStor reaches beta in 0.8, you’ll see it used to dramatically improve snapshots and clones and related use cases as well.
Well, that’s a quick recap of last week. It was perhaps our most important week as we started to tie together our technologies into a solution, MDAP, that we think is unequaled at least in the breadth of vision, and we are just getting started. We continue to progress towards our vision of data agility — where Kubernetes and related technologies and services including of course OpenEBS are used to dramatically accelerate the building and operating of environments that include stateful workloads in a way that is free from vendor and cloud lock-in.
Please provide any feedback below or via @epowell101. Thanks for reading!
This article was first published on Sep 6, 2018 on MayaData's Medium Account.





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu