

One of the most exciting things — at least to me — in evolutionary biology is the concept of parallel evolution — for instance, the Aloe and Agave plants.
They may appear to be interchangeable in your local nursery as drought resistant “succulents” and yet prove to be barely related at all — their evolution diverged at the time of the dinosaurs. They evolved to have similar features because the ecosystems in which they competed had the same requirements.

In this blog, I’ll focus on the similarities and differences of the features and approaches.
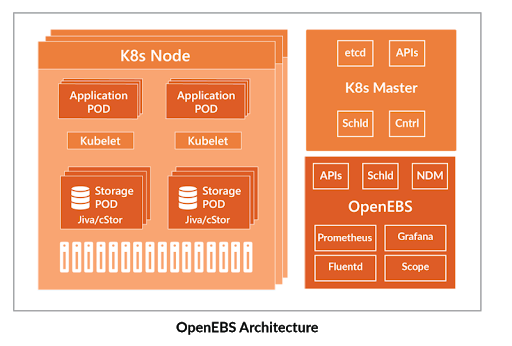
vSAN integrates into vSphere and is surrounded by various tools with different names, while in the case of OpenEBS, the orchestrator is Kubernetes, and the surrounding tooling is called the MayaData Agility Platform or “MDAP.”
Fundamental architecture:
Both vSAN and OpenEBS leverage the existing orchestrator for quite a bit of functionality. In the case of vSAN, the capabilities of vSphere such as HA and DRS are used to provide HA capabilities; also much of the management of vSphere is leveraged to allow easy use of vSAN for VMware administrators.
Similarly, OpenEBS also relies on Kubernetes wherever possible including for HA and similar capabilities. The OpenEBS team is also extending Kubernetes via the Node-Disk-Manager (NDM) project and otherwise to improve the ability of Kubernetes to act as a storage substrate, much in the way that the vSAN team has pushed capabilities into vSphere that enhance vSphere’s storage capabilities.
There are a couple of fundamental differences. However, VMware makes the point that there is no VM that comprises the local controller for vSAN. In this way, they are differentiated from other virtual storage appliances which of course have to run on top of vSphere using their APIs as opposed to building capabilities into vSphere itself. You can see VMware makes this point at about 4:23 in the following video: https://www.youtube.com/watch?v=87GpZ4yc0iM
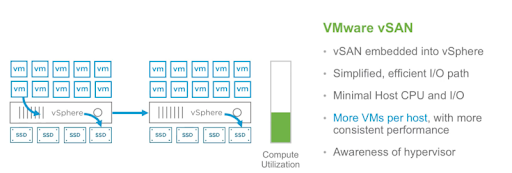
vSAN embedded into vSphere
Similarly, while OpenEBS leverages Kubernetes where possible the OpenEBS software runs as separate containers which we call controllers and replicas. While there are downsides to the approach of not being embedded into the orchestrator or scheduler — there are also benefits such as:
- Mobility — the ability to move OpenEBS — the controllers and the replicas — across environments.
- Independence — vSAN of course only runs on vSphere — as it is embedded in vSphere — whereas OpenEBS runs anywhere that Kubernetes can run.
- The consistency of tooling — VMware has the resources to build specialized tools that integrate with vSphere management, while in the case of OpenEBS, whatever tools that are being used to manage Kubernetes and workloads on Kubernetes are used. Additionally, MayaData offers complementary tooling as discussed below.
Granularity:
Both vSAN and OpenEBS emphasize granularity. In the case of vSAN — the granularity in many, but not all cases, is at the level of the VM whereas with OpenEBS it is at the level of a particular workload.
Additionally, OpenEBS is designed to give teams control of their environments so that a team can control their workload irrespective of where the workload runs. Any compatible Kubernetes deployment will work whereas of course, vSAN needs the right flavor of vSphere running — a limitation that VMware is working to address with their partnership with AWS and with the usage of vSphere and vSAN by countless managed service providers.
Note that the per workload and team granularity of OpenEBS means that each deployment can be more easily upgraded and that new versions can be adopted without the entire underlying Kubernetes being upgraded, and of course, there are other operational benefits to having a truly cloud-native architecture. The tight coupling of vSAN to vSphere and ESX means that upgrades are a more comprehensive affair that increases operational costs and risks.
Data protection:
Fundamentally, what OpenEBS and vSAN do is they protect data — so data protection is crucial. In the case of OpenEBS, data is synchronously replicated to multiple locations which we call replicas. These replicas scheduled themselves with the help of information that the OpenEBS control plane (which we call Maya) provides to Kubernetes so that one replica is local to the workload they are serving whenever possible. OpenEBS also handles the case of a failure of a replica via background rebalancing. All of this is done in a way that can be controlled by Kubernetes itself so that, for example, your background replication or other tasks can be deprioritized versus compute or networking or other tasks on a given host.
The above description could apply in many ways to vSAN as well. Like OpenEBS, vSAN typically creates replicas and then schedules them intelligently.
However, vSAN also offers cross host RAID 5 and RAID 6 or erasure encoding. The benefit of this approach is that it saves space versus replicas.
While we have had some partners and users suggest that OpenEBS go in this direction, thus far we have chosen not to do so for some reasons. As always, your feedback is welcome. Those reasons include:
- Size of workloads — whereas vSAN is providing storage on a per virtual server basis, OpenEBS provides storage on a per container basis. Generally speaking, those workloads are much smaller in a modern architecture than in a more traditional n-tier application. This may change over time however as Kubernetes increasingly becomes the default solution for orchestration, even for legacy workloads that are “lifted and shifted” onto containers.
- Simplicity — while RAID may save 20–30% of capacity, the trade-off in perceived complexity is considerable. With OpenEBS, with the help of WeaveScope and MayaOnline and other systems, users can “see” their data and, equally as importantly, Kubernetes itself can be used for scheduling.
- Mobility — once again OpenEBS is built to be easily mobile to any location. While it is, of course, possible to replicate data that has been stored across many hosts it can be more difficult to manage and to implement.
It is also interesting to note that two additional areas of similarity are the extensions beyond the core storage, vSAN or OpenEBS. Both VMware and MayaData’s MDAP surround these storage systems with:
- Active testing — in the case of OpenEBS it is Litmus, an open source project for chaos engineering and end to end testing that is integrated into MayaOnline, a free management solution. In the case of vSAN and VMware, there are a couple of options including an embedded IOmeter tool that can be invoked from the GUI. It appears that currently, Litmus is much more extensible — it is open source after all — whereas the embedded active testing available in vSAN has more packaged tests available via the GUI that are as of yet integrated into MayaOnline. You can read more about Litmus here: https://openebs.io/litmus and you can read much more about vSAN’s active testing in this knowledge-based article from March of 2018 here: https://kb.vmware.com/s/article/2147074
- Visualization and control — in the case of OpenEBS, visualization and control are provided both from MayaOnline and from our integrated support for Prometheus for those that want to do it themselves. In the case of VMware, there is a vSAN observer that displays monitoring metrics. While overall VMware has more tooling than OpenEBS and MayaData, solutions like MayaOnline with WeaveWorks compare favorably thanks to the use of new interfaces and approaches. Judge for yourself here, VMware’s vSAN observer:
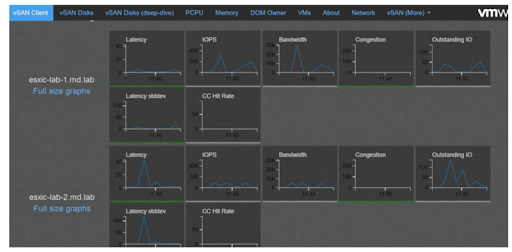
vSAN observer
Compare this to the visualization and control from MayaOnline:
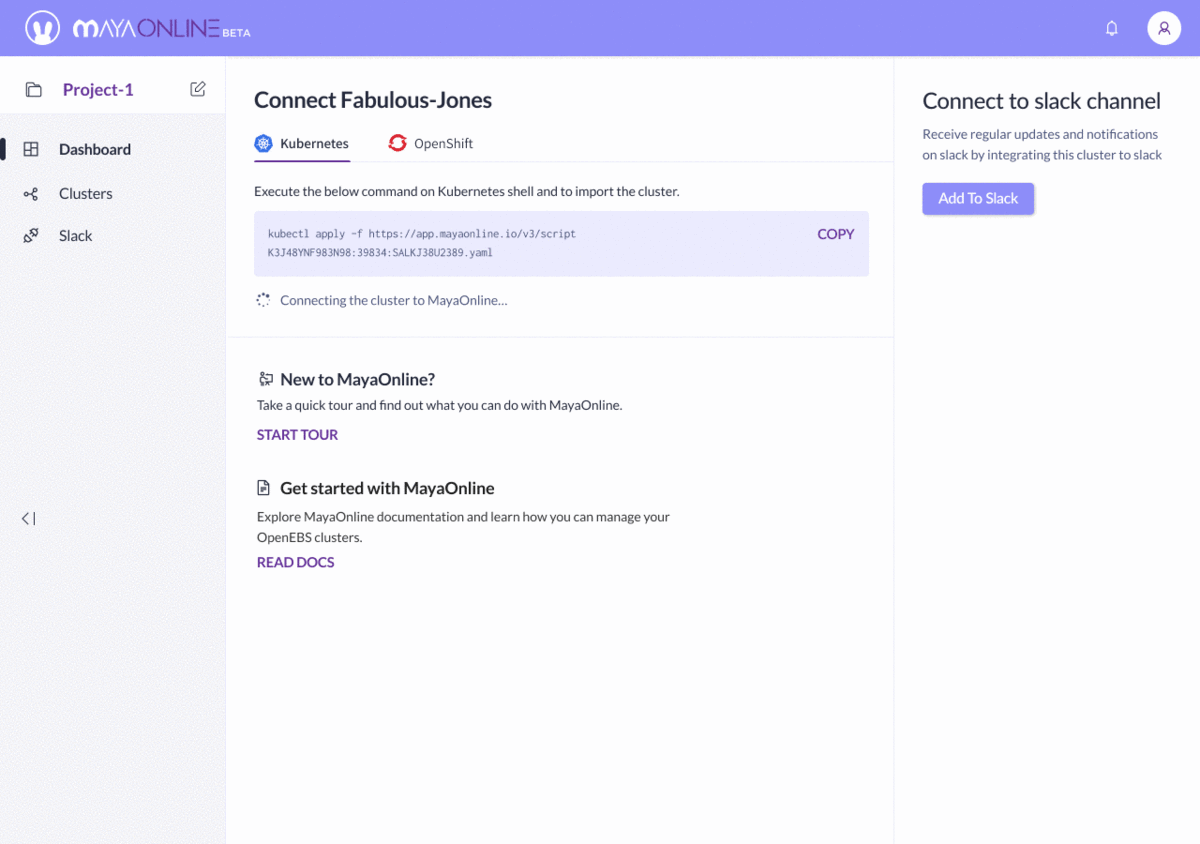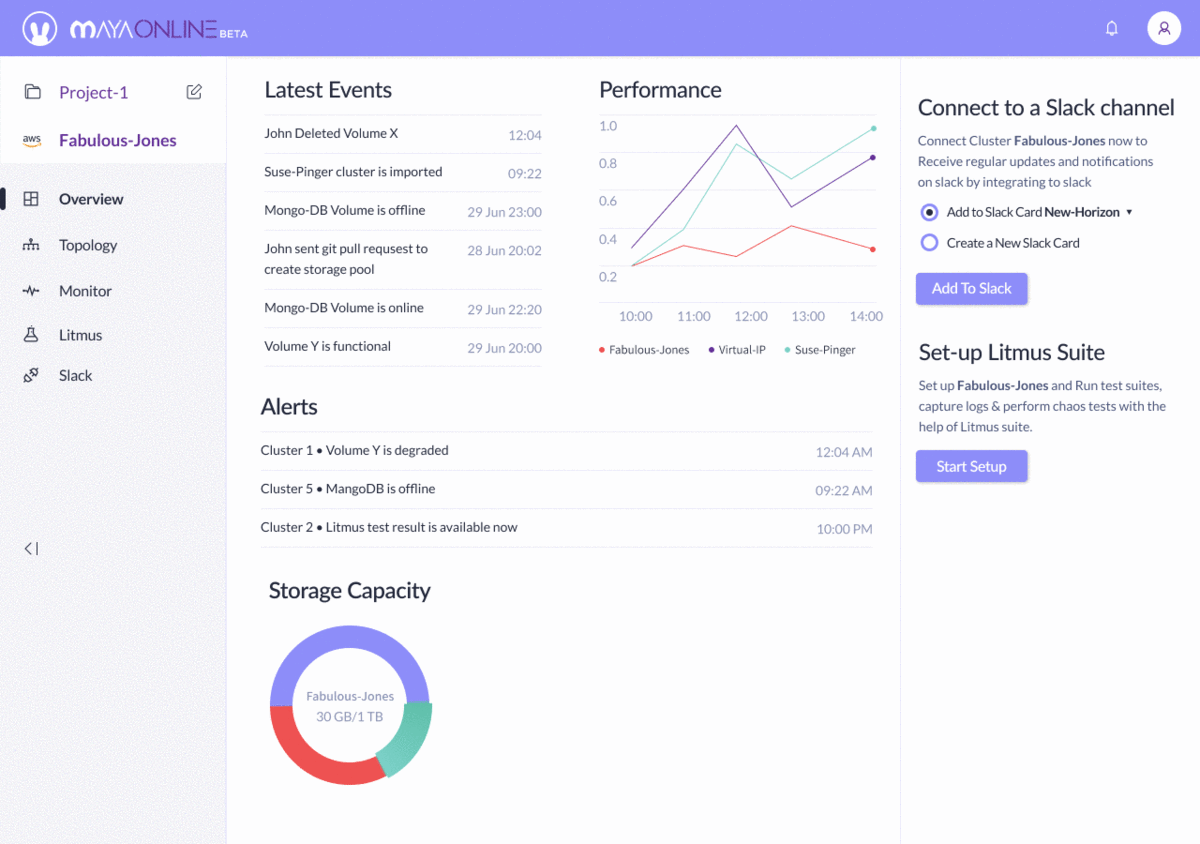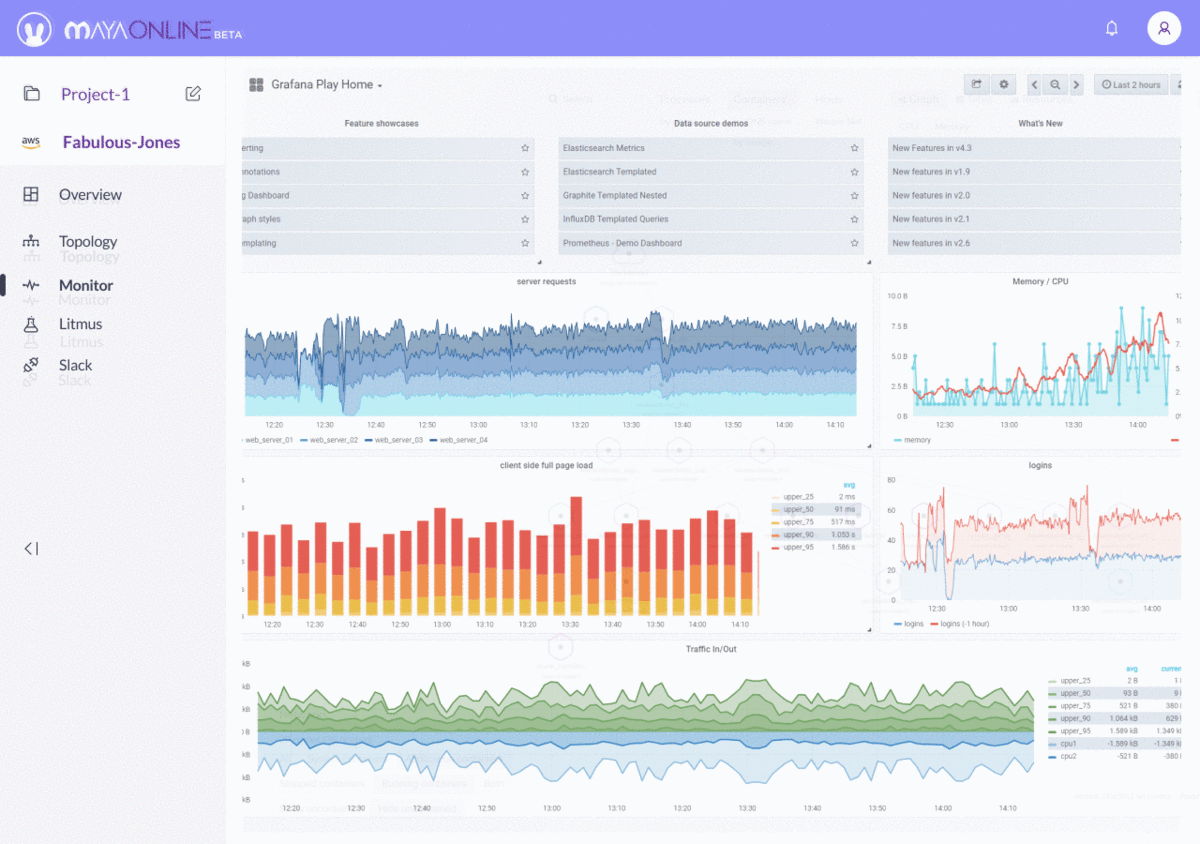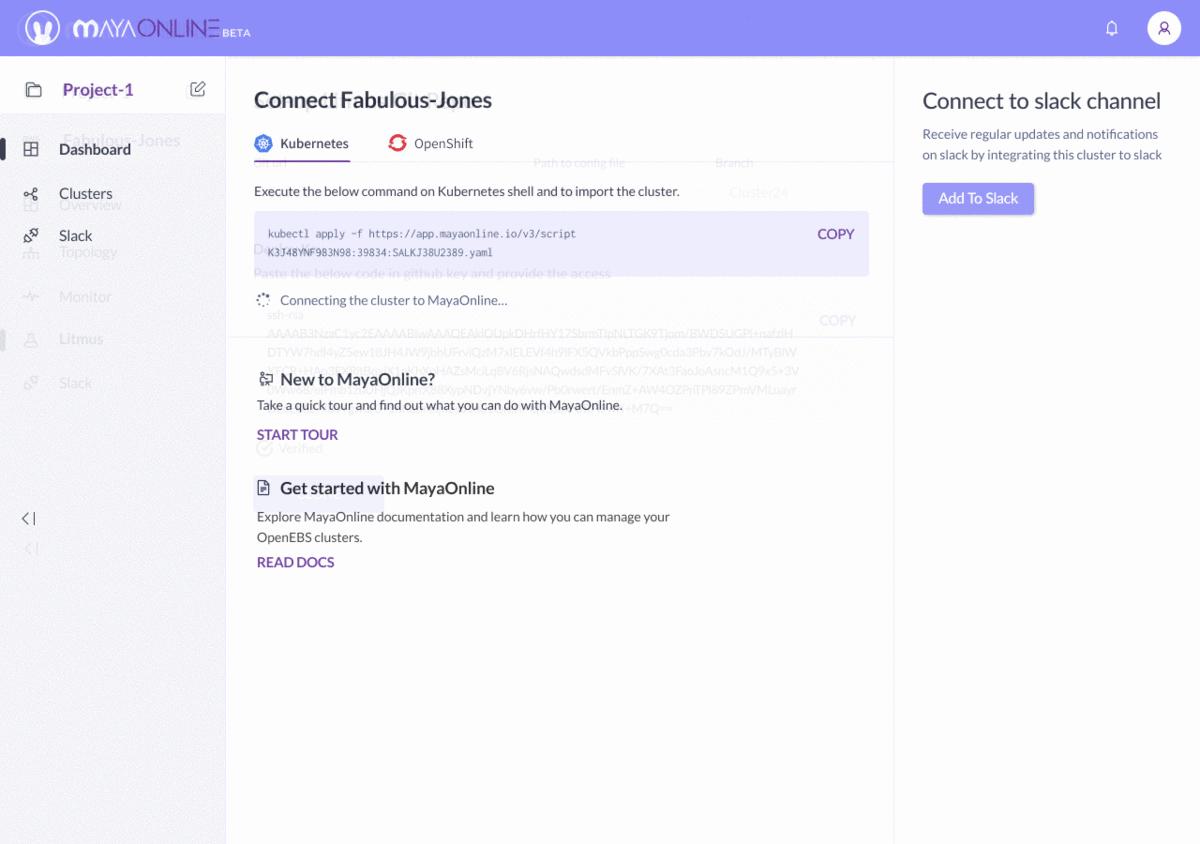
Visualization and control from MayaOnline:
While VMware’s solutions are more refined, they are not open source and may not use the newest approaches such as the graph database foundation of MayaOnline’s WeaveScope.
Conclusion:
Well, those are some highlights. There are other differences such as networking — vSAN requires the use of multicasting for example whereas OpenEBS must be careful to embrace existing Kubernetes networking approaches.
And perhaps the most important difference has to do with the overall design of the technology and the company behind it — in the case of OpenEBS we have an open source, self-adoption approach and so we are particularly focused on that self-adoption. This means that every team and workload can adopt OpenEBS without a reference to the underlying IaaS. It makes sense given our Data Agility mission and so forth (sorry for the sales pitch :)).
Conversely, VMware already is the default underlying orchestrator or IAAS-like layer in the enterprise, and they are seeking to increase their stickiness as opposed to fighting lock-in. What is more they are successfully fighting to capture share versus other storage vendors, so their approach of embedding vSAN into ESX and vSphere makes a lot of sense to them?
Also, it is worth reiterating that this blog isn’t intended to suggest that OpenEBS is at the level of maturity of vSAN as of yet. OpenEBS as of the time of this writing does have millions of Docker pulls and thousands or low tens of thousands of users — however, it is also pre 1.0, and commercial support is not yet generally available. While countless users run OpenEBS in production, we have a limited number of commercial users that are running OpenEBS with the help of MDAP.
What did you think of this blog? What questions did it raise? Are there areas that you would like us to investigate more deeply? Please provide feedback below or via twitter or catch us on Slack or otherwise. Thanks for reading!
This article was first published on Sep 24th, 2018 on MayaData's Medium Account





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu