

Prometheus has become one of the favorite tools for monitoring metrics of applications and infrastructure in the cloud-native space, especially when using Kubernetes. After all, Prometheus was the second project adopted by the CNCF after Kubernetes itself and in August of 2018, it was the second project to graduate from CNCF as well.
 Using OpenEBS as local storage for OpenEBS
Using OpenEBS as local storage for OpenEBSGiven this lineage, setting up Prometheus on Kubernetes is quite straightforward. You can read much more on how to get going on Prometheus, and also on how it compares to alternatives such as Graphite or InfluxDB on their documentation.
One of the challenges with Prometheus is how to set up and manage the storage for it. The default behavior of Prometheus is to simply have each node store data locally. However, this, of course, exposes the user to the loss of data stored locally when the local node goes down.
Storage for Prometheus: Local and Remote
Prometheus 2.4 documentation categorizes the storage for Prometheus into two types. Local storage and Remote storage. When using local storage, data monitoring data is written in TSDB format, and when using Remote storage, the data is written through storage adaptors, and Prometheus does not control the format in which the data is stored. Here is a quick infographic about Local and Remote storage usage for Prometheus.

- No replicated data.
- The data is limited to a single node. If the Prometheus server crashes or needs to be restarted for any reason, the service has to wait till it comes up on the same node.
- Not scalable in terms of adding more capacity or performance dynamically.
By using OpenEBS volumes as the local storage for Prometheus on Kubernetes clusters, each of the above drawbacks is addressed.
By way of introduction, OpenEBS is the easiest to use and most widely adopted open source container attached storage for Kubernetes. OpenEBS provides per application storage controller, and the storage is scalable per application. With these features and the synchronous replication capability, OpenEBS is well suited for using it as local storage for Prometheus. You can read much more about OpenEBS on https://docs.openebs.io/. It should take very little time to deploy and begin to use OpenEBS once you have a Kubernetes environment. Also, it may be worth noting that at MayaData in addition to sponsoring OpenEBS we also use Prometheus extensively and also WeaveCortex for our own support and our stateful workloads management application, MayaOnline.
The following (mentioned here) is no longer true when using OpenEBS as local storage
“If your local storage becomes corrupted for whatever reason, your best bet is to shut down Prometheus and remove the entire storage directory. However, you can also try removing individual block directories to resolve the problem. This means losing a time window of around two hours’ worth of data per block directory. Again, Prometheus’s local storage is not meant for durable long-term storage.”
Use OpenEBS volume as Prometheus TSDB for durability and scalability
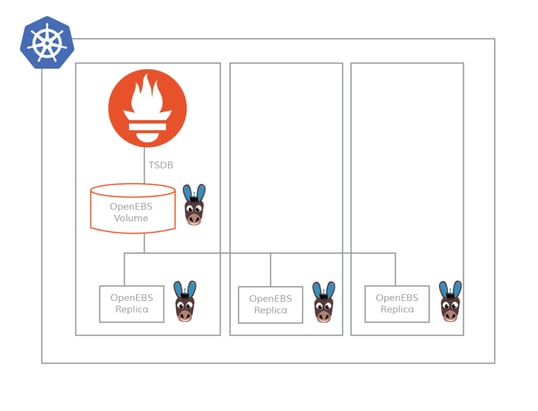
OpenEBS volumes are replicated synchronously, in that way, data is protected and is always made available against either a node outage or a disk outage. Replica and quorum policies are independently controlled so that, for example, OpenEBS can be configured to acknowledge a write when N replicas respond, where N is <= replica count. OpenEBS can configure Kubernetes in such a way that a Prometheus pod is always scheduled in one of the three nodes that the OpenEBS replica resides. To make the data even more highly available, the OpenEBS replicas can reside in different Availability Zones of Kubernetes which in general (if in the cloud) are mapped to physical AZs of the cloud provider.
Scalability of storage
The fact that capacity cannot be added easily as needed is one of the top limitations of using local storage for Prometheus. OpenEBS helps to address this issue; capacity can be added on-demand and on-the-fly to OpenEBS volumes. So, your Prometheus local storage never runs out of storage space with OpenEBS.
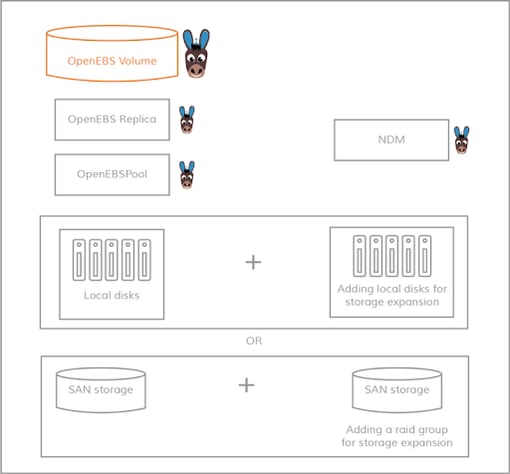 On the fly storage expansion with OpenEBS
On the fly storage expansion with OpenEBSLocal disks are grouped into storage pools, and OpenEBS volumes are carved out from these storage pools. Because of the pooling concept, you can start with small size for the storage volume and expand dynamically on demand without any service disruption i.e., on-the-fly. Disk failures are protected against an optional RAID configuration among the disks. Even an entire pool failure (can happen when a disk fails on a stripe group for example or when storage infrastructure fails) is non-fatal in OpenEBS as the rebuilding of the data happens from other replicas. So you have both local redundancy and cross-host redundancy by using OpenEBS.
What about performance? WAL support
Because OpenEBS is a pluggable, containerized architecture it can easily use different storage engines that write data to disk or underlying cloud volumes; the two primary storage engines are Jiva and cStor. Write cache support is available in the cStor storage engine. With WAL support, the write performance of Prometheus increases significantly.
How to configure OpenEBS as storage for Prometheus?
Just build the storage class and update your Prometheus YAML. Your Prometheus is up and running with highly available TSDB storage with OpenEBS volumes automatically created and configured.
Pay attention below to the storage class parameters in the storage class. “openebs-prometheus-sc”
| --- # prometheus-deployment apiVersion: extensions/v1beta1 kind: Deployment metadata: name: openebs-prometheus namespace: openebs spec: replicas: 1 . . . volumeMounts: # prometheus config file stored in the given mountpath - name: prometheus-server-volume mountPath: /etc/prometheus/conf # metrics collected by prometheus will be stored at the given mountpath. - name: cstor-prometheus-storage-volume mountPath: /prometheus volumes: # Prometheus Config file will be stored in this volume - name: prometheus-server-volume configMap: name: openebs-prometheus-config # All the time series stored in this volume in form of .db file. - name: cstor-prometheus-storage-volume persistentVolumeClaim: claimName: cstor-prometheus-storage-volume-claim --- #PersistentVolumeClaim for prometheus kind: PersistentVolumeClaim apiVersion: v1 metadata: name: cstor-prometheus-storage-volume-claim namespace: openebs spec: storageClassName: openebs-prometheus-sc accessModes: - ReadWriteOnce resources: requests: storage: 300G |
| #Use the following YAMLs to create a cStor Storage Pool. # and associated storage class. --- apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: openebs-prometheus-sc annotations: openebs.io/cas-type: cstor cas.openebs.io/config: | - name: StoragePoolClaim value: "cstor-disk" |
| #(Optional) Below 3 lines required only if to schedule the target pods deployed on the labeled nodes - name: TargetNodeSelector value: |- node: appnode provisioner: openebs.io/provisioner-iscsi --- apiVersion: openebs.io/v1alpha1 kind: StoragePoolClaim metadata: name: prometheus-pool spec: name: prometheus-pool type: disk maxPools: 3 poolSpec: poolType: striped # NOTE - Appropriate disks need to be fetched using `kubectl get disks` disks: diskList: # For Eg: the below disk is from Node1 AZ1 - disk-184d99015253054c48c4aa3f17d137b1 - disk-2f6bced7ba9b2be230ca5138fd0b07f1 # For Eg: the below disk is from Node2 AZ2 - disk-806d3e77dd2e38f188fdaf9c46020bdc - disk-8b6fb58d0c4e0ff3ed74a5183556424d # For Eg: the below disk is from Node3 AZ3 - disk-bad1863742ce905e67978d082a721d61 - disk-d172a48ad8b0fb536b9984609b7ee653 --- |
Summary:
Using OpenEBS as storage for Prometheus on Kubernetes clusters is an easy and viable solution for production-grade deployments. Try using OpenEBS and see if it lives up to the expectation of being the easiest-to-use cloud-native storage project in Kubernetes ecosystem. Join our slack channel if you need help or to share your success story.
This article was first published on Oct 2, 2018 on OpenEBS's Medium Account





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu