

“Litmus is a chaos engineering tool for Kubernetes. Litmus provides easy-to-use, ready made pipeline jobs that can be used to build a pipeline to help harden the applications that use Cassandra. Litmus helps in validating the functionality of Cassandra, OpenEBS, and Kubernetes itself.”

In this post, I will detail some of the Litmus jobs that are related to Cassandra. But first, let’s start with a bit of recap of Cassandra, OpenEBS, and Litmus itself.
Apache Cassandra is an open-source, NoSQL, highly scalable, high-performance distributed database management system designed to handle an enormous amount of structured data across commodity servers.
OpenEBS is an open-source CNCF Sandbox project for container-attached and container-native storage on Kubernetes. OpenEBS adopts the Container Attached Storage (CAS) approach, where each workload is provided with a dedicated storage controller.
Why use OpenEBS for Cassandra HA?
There are several notable benefits to using OpenEBS as the underlying storage for Cassandra statefulset:
- OpenEBS enforces the Kubernetes scheduler to run a Cassandra pod on the same node where data exists using node labels. This allows users to schedule the OpenEBS storage target to reside on the same node where the application pod is scheduled to honor HA.
- Large size PVs can be provisioned for Cassandra instances. OpenEBS supports volumes up to several petabytes in size.
- OpenEBS volumes are thin provisioned. The capacity of the volumes can be scaled on the fly by adding disks, without any service disruption.
- Each persistent volume has a dedicated storage controller that increases the agility and granularity of storage operations of the stateful application.
- Cassandra backups can be taken at the storage level and stored in S3. Using these backup/restore capabilities of OpenEBS, Cassandra instances can be seamlessly moved across Kubernetes clusters.
- Node Disk Manager in OpenEBS enables disk management in a Kubernetes way. Using OpenEBS, nodes in the Kubernetes cluster can be horizontally scaled without having to worry about managing persistent storage needs of stateful applications.
Chaos Engineering practices are quickly becoming a standard component of any CI/CD pipeline to ensure faster and reliable software development. This approach identifies possible failures before they become outages. Practicing Chaos Engineering in DevOps pipelines can increase the confidence in the system and enable application developers to make their code concrete.
Litmus is an Open-source Chaos engineering framework designed for validating behavior by inserting chaos into the applications running in the Kubernetes environment. It acts as preventive medicine for “diseases” that can occur in the production environment.
Though Litmus has been designed to be easily extendable and work with different persistent storage solutions, OpenEBS is the primary consumer of these tests. As a result, the majority of chaos functions are directed against the OpenEBS storage resources (target pod, replica pod, storage pools, etc.) and their corresponding state validations. For more information about Litmus, visit https://litmuschaos.io/
Litmus experiments are broadly categorized into four types:
- K8S infrastructure setup books
- Deployers for providers such as OpenEBS.
- Stateful applications deployment books
- Chaos insertion books
Here, we will specifically focus on the Litmus deployers and chaos experiments currently available to build a CI/CD pipeline that can harden Cassandra's application running on OpenEBS and Kubernetes.
Ideally, developers should concentrate on implementing test cases for the business logic involved in the application pods. Pipelines for hardening the rest of the components of the stack, such as Cassandra deployment, OpenEBS implementation, and Kubernetes/OpenShift implementation, can be built through Litmus books. Later in this post, we provide a sample implementation and example litmus books for reference.
Stages of Cassandra HA Pipeline
The Pipeline has been constructed through various GitLab stages such as
- CLUSTER-SETUP
- OPENEBS-SETUP
- FUNCTIONAL
- CHAOS
- CLEANUP
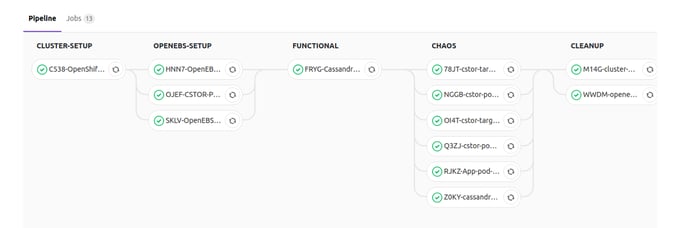
The jobs in the above pipeline continue to evolve across releases.
Litmus Experiment for Deploying Cassandra HA
Litmus is based on ansible playbooks that typically create Kubernetes jobs to execute the desired test. Users can get started with Litmus by following this procedure.
Now, let me illustrate the usage of a few Litmus experiments.
Cassandra HA Deployer
Here is the litmus experiment for deploying Cassandra Statefulset in the Kubernetes environment.
In the above litmus experiment, set the parameters according to requirements before executing it. The job can be created by running the following simple kubectl command:
kubectl create -f cassandra_litmus.ymlLitmus Experiment for Pumping Traffic
This litmus experiment writes data into Cassandra instances using the tool `cassandra-stress`.
Chaos Job-Cassandra Pod Failure
The intention of this litmus experiment is to force a failure in one of the Cassandra pods and analyze the system’s behavior.
Make sure to update the environmental variables with the required test parameters before creating the job.
Contributing to Cassandra Chaos Chart
Litmus has introduced a new chaos operator and the infrastructure to run chaos in production against stateful applications such as Cassandra. If anyone in the Cassandra community is interested in contributing to the helm chart of Cassandra chaos, take a look at the issue
Summary
Implementing CI/CD pipelines for applications based on Cassandra, OpenEBS, and Kubernetes using Litmus is very simple, as illustrated in this discussion.
If you would like to contribute to Litmus, feel free to join our community slack channel slack.openebs.io and visit the #litmus channel.
Important Links
Litmus website: https://litmuschaos.io/
Litmus docs: https://docs.litmuschaos.io/
Litmus repo: https://github.com/litmuschaos/litmus
Issue for creating Cassandra chaos chart: https://github.com/litmuschaos/chaos-charts/issues/7
This article was first published on May 22, 2019 on MayaData's Medium Account





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu