

MDAP — Journey of data agility on Kubernetes from MayaData
In this post, we will discuss what’s next — at least from our perspective — in the overall space of container attached or Kubernetes native storage services. While there have been many discussions recently about OpenEBS joining the CNCF (Evan Powell penned an article for the CNCF.io blog updating the container attached storage space

MDAP — Journey of data agility on Kubernetes from MayaData
We are of course talking about what's coming in OpenEBS 1.0), I want to dig a little deeper into three areas of progress that together might be called the second chapter of container attached storage:
- Data mobility — What are we doing to free users from cloud and storage lock-in and how can the community help?
- Pluggable storage engines FTW — Two new storage engines are hitting the OpenEBS community; LocalPV is now in beta and a rust based storage engine is in alpha.
- Chaos for assurance — Our OpenSource chaos engineering project Litmus has been enhanced with operators to run more easily and is fundamental to our vision for an adaptive, multi-cloud data layer.
We are seeing more and more word of mouth by users in and around the OpenEBS community. And that’s crucial because word of mouth powers projects like OpenEBS that are committed to using Kubernetes itself as a data platform. Please do stay in touch and spread the word about this approach.
Early access to data mobility — Announcing DMaaS Beta'

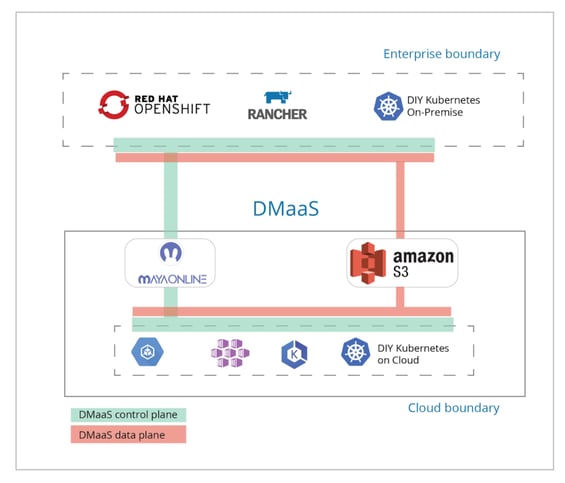
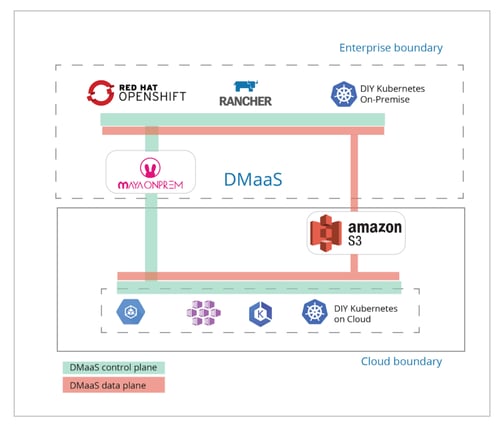
Data Migration as a Service, or DMaaS, helps users to easily move their workloads from one cluster to another cluster or from one namespace to another within the same cluster. Common use cases include rolling upgrades of your underlying Kubernetes or of the workloads on top, such as Kafka. We also see users leveraging DMaaS to shift workloads onto different Kubernetes environments as well, including that often-discussed multi-cloud use case. Just like OpenEBS has gained traction and attention as the simplest storage and storage services for your Kubernetes, whether on-premise or in the cloud, our design philosophy for DMaaS is simplicity first. We want DMaaS to fade into the background as a primitive that just works.
How Does DMaaS Work?
DMaaS leverages the inherent capabilities of OpenEBS and other capabilities to form a complete SaaS, or on-premises software product. So, DMaaS is now available in our initial free-to-use MayaOnline and in MayaOnPrem as well. The workflow is relatively simple. First, the source and destination clusters need to be connected to MayaOnline or MayaOnPrem. Then configure and schedule the application backup or migration from the source Kubernetes cluster to an intermediate location which, in this case, is the commonly used AWS S3. Next, conduct a restoration to the destination cluster when desired. DMaaS uses underlying Velero/Restik technology to manage data transfers as well as our own session control and underlying storage capabilities.
DMaaS support will soon be extended to all applications that consume storage using the generic PV interface, including other OpenEBS storage engines and eveb non-OpenEBS engines as well. For the time being, DMaaS only works with the open source OpenEBS cStor storage engine — leveraging the COW based snapshotting capabilities to allocate resources efficiently.
The diagrams shown below provide a simple illustration of how DMaaS works for both our SaaS solution MayaOnline, as well as the OnPremise solution MayaOnPrem.
DMaaS using MayaOnline
DMaaS using MayaOnPrem
Use Cases of DMaaS
Here are some common use cases where DMaaS is beneficial.
- Simple backup and restoring of data for stateful applications
- Scheduled or continuous backup for Disaster Recovery
- Moving data or applications across Kubernetes clusters during large-scale Kubernetes upgrades and the upgrades of stateful workloads such as Kafka
- The use of throw-away clusters for security or other purposes
- Moving applications running on Kubernetes with a certain cloud provider to a different cloud provider, or on-premise
- Moving on-premise applications to another data center or a cloud provider
DMaaS Roadmap
We are working on two extensions that will be available soon to our users.
- The backup and restore provider support will be extended to two more cloud providers, Google Cloud Storage and DigitalOcean Spaces. This gives DMaaS users even more freedom to choose their preferred cloud provider.
- Support backup and restore on a generic PV, including LocalPV, using application consistent hooks that the applications themselves provide. With this feature, DMaaS works for any storage provider underneath and aids in onboarding the applications to OpenEBS storage, such as OpenEBS cStor, OpenEBS Jiva, or OpenEBS LocalPV.
We also recently announced a new open source project “KUBEMOVE” that serves to build data mobility interfaces in the open. With KUBEMOVE, cloud providers will be able to build a control plane similar to the one shown above with either MayaOnline or MayaOnPrem. The data can be transferred directly to the destination clusters without the need of intermediate storage such as S3, Google buckets, or DigitalOcean spaces. Storage and application vendors can write to a KUBEMOVE data plane for providing dynamic data mobilizers. Together with the community, KUBEMOVE will become the vehicle for moving any workload across any provider running any storage backend.
Local PV — Dynamic provisioner for local disks
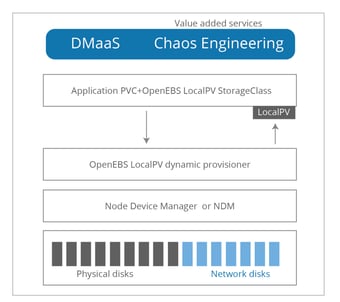
Our survey results and research data show that LocalPV is already being widely used. By using OpenEBS LocalPV, the benefits of DMaaS and chaos engineering toolset Litmus are extended to applications using local disks on Kubernetes. There are only a few differences between the generic LocalPV that we see in the Kubernetes documentation and the OpenEBS LocalPV:
- OpenEBS LocalPV is integrated with OpenEBS NDM and has a dynamic provisioner. NDM consolidates the disks into Kubernetes CRs so that they are managed in a Kubernetes native may. LocalPV dynamic provisioner enables the use of local disks like any other storage. For example, users can create a PVC to request a local disk with a storage class pointing to the type of disk and size, etc. The management logic behind the choice of local disk being used is managed by OpenEBS dynamic provisioner in conjunction with OpenEBS NDM.
- Because LocalPVs are managed by NDM, the disk metrics are available on MayaOnline/MayaOnPrem. Chaos experiments and their results can be correlated for easier analysis and debugging. A DMaaS for LocalPV based application is coming soon on MayaOnline/MayaOnPrem.
Kubernetes native chaos engineering — Announcing chaos operator and chaos charts hub

In 2018, we introduced Litmus as a toolset to run chaos on Kubernetes. Litmus was adopted as a toolset to build and run CI pipelines with workload specific chaos books readily available. One of the requirements for our data agility vision is to be able to validate and harden the applications, both before and during production. Another requirement is that the Litmus toolset should be easy to use and be ready to use in a Kubernetes native way. With these requirements in mind, we are now announcing the availability of the chaos operator of Kubernetes.
Developers can use chaos operator to introduce chaos into their application as an extension to their unit testing or integration testing. Application hooks and helm charts are provided to make the chaos experience easier. Introducing chaos into an application is very simple:
- Install Litmus operator into a namespace.
- Enable chaos engineering for your application through an annotation (litmuschaos.io/chaosenable=”true”).
- Download chaos charts for your application from the litmus helm repo.
- Run chaos using the downloaded charts.
We have launched a new website (https://litmuschaos.io) to provide more information and educate/serve the community around chaos experiments. We welcome PRs into our Github repositories under https://github.com/litmuschaos
Chaos Charts
Litmus chaos charts are designed as helm charts that are specific to an application or infrastructure. We believe this chart model will encourage community participation in developing application or database specific chaos experiments and make it easier for users to manage them.
https://litmuschaos.github.io/chaos-charts/
For DevOps architects and SREs, Litmus operator and chaos charts will help in coordinating the introduction of chaos in an organized fashion. Selected chaos can be scheduled into production systems and users can easily view the results and correlate them with historic results and the associated state of the resources on the clusters. When a Kubernetes cluster is connected to MayaOnline/MayaOnPrem, the chaos experiment results and associated metrics are automatically exported and the correlation reports are made available to periodically determine the resiliency of the system.
Summary
MayaData continues to make great strides in delivering the technology to help DevOps teams and SREs become more agile and autonomous when dealing with stateful applications on Kubernetes. MayaData is introducing DMaaS for cross-cloud data management, Litmus chaos operator for chaos assurance, and two new data engines for higher performance (OpenEBS LocalPV and Rust based high-performance data engine). These relevant tools will improve data agility for any team or organization developing applications in Cloud Native space.
Come see us at booth SE41 in KubeCon Barcelona. We’ll be presenting great demos around DMaaS, LocalPV, Litmus, and many more tools.
Other useful links
This article was first published on May 19th, 2019 on MayaData's Medium Account





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu