

This article is part of a #Concepts series on Kubernetes and Litmus. Here, we present an overview of why and how the Litmus project employs chaos techniques to test the resiliency of OpenEBS storage solutions.
In this extremely insightful article, Evan Powell outlines various possible failures that could occur in a Kubernetes cluster running stateful workloads and the possible means to mitigate them. These methods also advocate for Chaos Engineering as a means to gauge system behavior, blast radius, and recovery times. While there are some incredible chaos tools in the Kubernetes ecosystem, both opensource (chaoskube, pumba, chaostoolkit etc.,) and even free solutions (gremlin-free) can help induce specific types of failures on containers, pods, virtual machines and cloud instances. A need was identified to tie the act of chaos itself with automated orchestration (steady state condition checks) and analysis (data availability & integrity, application and storage deployments’ health etc.,).
Litmus was developed in order to (amongst other needs) facilitate a Kubernetes-native and persistent storage, i.e., stateful workload-focused approach to chaos, with the ability to self-determine the success of a controlled chaos experiment based on pre-defined exit criteria. In other words, a framework to construct and host a ready set of “deployable tests” that use chaos engineering principles as the underlying business-logic. In order to achieve this, Litmus internally makes use of the aforementioned opensource chaos tools, combined with the power of kubectl, while also employing certain home-grown chaos techniques where necessary.
 Though Litmus has been designed to be easily extendable and work with different persistent storage solutions, the OpenEBS community is the primary consumer of these tests. As a result, the majority of the utils/modules are chaos functions directed against the OpenEBS storage (persistent volume) resources (target pod, replica pod, storage pools etc.,) and their corresponding state checks. There are, however, app-specific and general infrastructure chaos tests too.
Though Litmus has been designed to be easily extendable and work with different persistent storage solutions, the OpenEBS community is the primary consumer of these tests. As a result, the majority of the utils/modules are chaos functions directed against the OpenEBS storage (persistent volume) resources (target pod, replica pod, storage pools etc.,) and their corresponding state checks. There are, however, app-specific and general infrastructure chaos tests too.The following sections will briefly discuss the approaches and patterns used in the design of the different litmus chaos tests. The objective here is to introduce the larger community to methods being followed in this project and receive valuable feedback against them! The step-by-step illustration on running these tests, with details on impact/behavior with respect to different OpenEBS storage engines, will be covered in separate blog posts in the #HowDoI series.
The Litmus Job Template
Note: To set the context (though it may already be known), a majority of the litmus tests are essentially ansible playbooks being executed from within a runner pod, which in turn is managed by the Kubernetes job controller.
One of the requirements of the “deployable” litmus test or chaos experiment is that the control variables (typically, chaos params — considering that different applications, storage engines, PV component versions, and deployment models are evaluated against a particular chaos sequence) and independent variables (PV, application and K8s deployment params) should be defined in the test artifact, which, in this case, is a Kubernetes job specification. This is achieved by specifying them as pod/container environment (ENV) variables. In most cases, the final object (cluster resource) of chaos is derived from the application or persistent volume claim info passed in the job.

Sample Litmus Chaos Test Variables/Tunables
Test Execution Workflow
The standard chaos test execution workflow is described in the schematic diagram shown below.
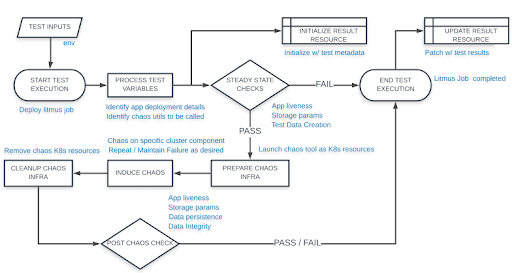
Litmus Chaos Test Execution Workflow
Container Crash
Litmus makes use of a Pumba daemonset to set up the chaos infrastructure, as this is necessary for the target and pumba containers to co-exist on a node so the latter can execute the Kill operation on the target. These pods are configured to run in --dry mode and have the host’s /var/run/docker.sock mounted as a volume, thereby allowing the test to launch custom chaos commands using the pumba-cli through kubectl exec operations.
Pumba “kills” a container by terminating the main process on the target container, and multiple termination signals (SIGKILL, SIGTERM, SIGSTOP)are supported. The object to be killed is either the app or PV target/replica/pool containers or their sidecars.
A sample chaos util (essentially, a task file that is imported/called in the main chaos test playbook) for performing a container kill can be viewed here.
Forced Pod Reschedule
Pod deletion, which is managed by higher level kubernetes controllers such as deployments and statefulsets, causes the pod to be rescheduled on a suitable node (same or different) in the cluster. Continuity of end application I/O and the time taken for reschedule/bring-up are the crucial post checks performed in these tests.
Litmus uses a chaoskube deployment (setup with RBAC) configured in a default --dry-run mode, allowing the test to run a custom pod failure chaos command using the chaoskube-cli through kubectl exec operations. This is done by providing appropriate label and namespace filters to point to the desired target pods.
Most of the chaos tests confirm the success of chaos induction (which itself “can” fail) by observing an increment in the resourceVersion of the target deployments (component under test) as part of the post-chaos checks.
A sample chaos util for performing a forced pod reschedule using chaoskube can be viewed here.
Network Delay and Packet loss to Specific Storage Resources
Litmus uses the Pumba daemonset (which internally makes use of tc and netem tools on the target containers) and tc directly in some cases to generate egress delays and percentage packet loss on the specified targets for the desired duration. Pumba also has the capability to induce network delays using random distribution models (uniform, normal, Pareto, Paretonormal) and loss models (Bernoulli, Markov, Gilbert-Elliott).
These capabilities are used to simulate flaky iSCSI storage targets, lousy data-replication channels, and test data reconstruction post temporary component loss (such as storage replicas and pools).
Sample chaos utils for inducing network delays and packet loss can be viewed here and here, respectively.
Forced Reschedule via Taint-Based Evictions
Under certain specific node conditions/states, Kubernetes automatically taints the node with what is commonly referred to as “eviction taints.” These have a “NoExecute” taint effect. This means the pods scheduled and running on these nodes are immediately evicted and rescheduled onto other suitable nodes on the cluster. Amongst these taints, Kubernetes automatically adds a default toleration period (tolerationSeconds) of 300s for node.kubernetes.io/unreachable & node.kubernetes.io/not-ready to account for transient conditions. For other taints, such as node.kubernetes.io/memory-pressure, node.kubernetes.io/disk-pressure, etc.., the pods are evicted immediately (unless specifically tolerated in the deployment spec. Visit kubernetes docs for more details).
This scenario holds relevance in the case of stateful workloads, where an en-masse movement of the application and storage resources (which may include control plane components) can have potential data availability considerations. In other words, it is an effective HA test, not dissimilar to a graceful node loss.
Litmus uses kubectl to simulate such node conditions by manually applying the taint on desired nodes (typically, the one which hosts the application and storage target pods) while monitoring end-application I/O. A sample chaos util for eviction by taints can be viewed here. Litmus simulates graceful node loss via another mechanism: Cordon and Drain (this also triggers reschedule of all the node’s pods), which is typically used in cluster maintenance workflows. This util is available here.
Simulated Daemon Service Crashes
Loss of node services (kubelet, docker) is one of the most common reasons for failed/non-starting pods and inaccessible application/storage services on the cluster. Litmus uses a privileged daemonset that mounts the host’s root filesystem paths in order to execute systemctl commands on the desired node (again, typically the node running application and storage target pods).
In case of managed (GKE) or cloud-hosted (KOPS based AWS, for ex.) kubernetes clusters, these crucial daemon services often have corresponding health check/monitoring services that detect anomalies and attempt a restart to restore node health. The litmus chaos utils disable these monitoring services temporarily for the duration of the chaos to ensure consistent chaos rather than flaky state changes (this, it can be argued, is a case for a separate test!). After the chaos duration has elapsed, all affected services are restored, with post checks confirming cluster health.
These scenarios cause the ungraceful/forced reschedule workflows in Kubernetes to kick-in. They have significant implications on stateful workloads, with disk/volume unmount-detach and reattach-remount times in focus. As with the eviction by taint and drain scenarios, Litmus monitors end-application I/O and data integrity as part of the chaos experiment.
Sample utils for service chaos on GKE and AWS clusters can be viewed here and here, respectively.
Resource Exhaustion on Kubernetes Nodes
While we discussed simulating node conditions via eviction taints, it is also necessary to actually induce resource exhaustion such as CPU burn, Memory Hog, and Filled Disks to gauge real-time behavior. Litmus uses simple docker containers that run (a) a python program to keep appending large data to a growing string to consume system memory, and (b) a forkbomb used to cause process multiplication resulting in CPU burn.
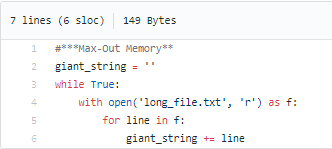
(a) system memory consumption
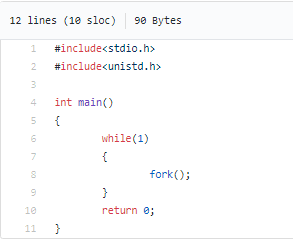
(b) CPU burn via forkbomb
A node-action daemonset that mounts the host’s /var/run is used to execute docker commands that run the above containers with Litmus monitoring node status and end-application I/O. The sample chaos util for resource exhaustion can be found here. Disk/Capacity fill utils, available in Litmus currently, are implemented within the storage volume and storage pool layers using fio tool.
Kubernetes Node (instance) Failures
Litmus supports instance termination on AWS (KOPS based Kubernetes clusters) and Packet (Bare-metal cluster using kubeadm). Work is in progress to extend the similar capabilities to other platforms as well. The different impact is noticed when node failures are performed across platforms. For example, in the case of AWS, another instance with the same root disk is automatically brought up as the nodes are by default a part of the KOPS auto-scaling instance group. With Packet, however, the node remains shut down and can be subsequently powered-on. These behaviors expose different workflows of the underlying storage solution.
For AWS, Litmus uses chaostoolkit templates that are executed in a Kubernetes job, which in turns runs a custom container using chaostoolkit binary and is equipped with the desired libraries. The AWS access keys and instance details are passed as test inputs from the Litmus test job. The util is capable of random instance selection in a given Availability Zone, as well as termination of a specific instance.
For Packet, Litmus uses the Ansible Packet module to power-off and power-on the node instance, with the packet API keys, project id, node name and chaos duration passed as test inputs.
The AWS and Packet node failure chaos utils can be found here and here.
Disk Failures
Litmus currently supports disk failure chaos utils for Kubernetes clusters built on an AWS cloud. Work is in progress to extend this to other platforms. The AWS CLI and Boto Python SDK are used to force detach and reattach the EBS volumes used as the disk sources for the storage pools. As with other chaos tests, Litmus monitors the end-application I/O and data integrity over the course of the experiment.
A Sample EBS disk failure util can be found here.
Conclusion
At this point in Litmus’ journey, improving the automated analysis capabilities, increasing the chaos function coverage across components, creating greater support for common stateful applications, and enhancing the stability of existing chaos tests are the top priorities. However, as happy members of the chaos engineering community, we are always on the lookout for updates and new entrants in the ecosystem and any other ways we can contribute! We hope this article has been helpful in gaining a better understanding of how Litmus does chaos. As mentioned earlier, we always look forward to your feedback & comments!!
This article was first published on Mar 20, 2019 on OpenEBS's Medium Account





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu