

OpenEBS 0.8.1 is now available starting today. Despite being tagged as a minor release, it provides significant stability improvements and a few important features. The OpenEBS community is constantly growing and we are receiving more feedback that we use in developing future releases. As such, most of the issues fixed in this release are in response to feedback received from the community. In this article, I will discuss some important highlights of the 0.8.1 release. For more details on the actual bugs fixed, see the release notes.

OpenEBS 0.8.1
Upgrade recommendation:
We are recommending that users of OpenEBS with cStor with Fedora 29 upgrade to 0.8.1, as it contains an important fix that can increase the stability of the environment. This includes avoiding possible node reboots by addressing underlying iSCSI and Kubernetes bugs. We are available to help throughout the community, so feel free to contact us if we can be of assistance.
Highlights of the 0.8.1 Release
Stability Fixes

iSCSI discovery bug leading to Kubernetes node reboots.
Some community users reported that the Kubernetes cluster occasionally becomes unstable when OpenEBS is in use. We worked with the community and debugged their issues to find the root cause. After deeper analysis, we found that Kubelet continues to increase in memory usage and finally results in that particular node going for a reboot, therefore causing the cluster to becoming unstable. An issue has been reported already in Kubernetes on Kubelet, and in our case, the same situation is being triggered from a different set of components, namely open-iSCSI and Fedora Kernel.
Here are some additional details:
- We discovered a bug in Ferora 29’s Kernel. The kernel does not respond to a socket read request if the request size is less than the watermark (in cStor target’s case, the water mark is set to 48) if the data becomes available after the read request is made. This works without issue if the data is already available when the request arrives at the kernel.
- Kubelet executes an iSCSI client command for discovery of the target. During this target discovery connection, the requested size to the kernel is 16 bytes and could result in the above mentioned situation if you are on Fedora 29. If the iSCSI client or initiator does not receive the response to the discovery request, it times out after 30 seconds and the connection is retried. After 5 retries, the iSCSI client hits a bug where it returns an infinite amount of data to Kubelet, which ends up reading all of the returned data. Kubelet then consumes the entire available memory and creates an out-of-memory situation, causing the node to reboot. We have created an open issue at open-iscsi for this bug as well.
In summary, when using Fedora 29 and open-iscsi, Kubelet experiences an out-of-memory issue if the iSCSI target’s TCP watermark is set to any number greater than 16. It was set to 48 by cStor’s iSCSI target. In 0.8.1, we set the watermark level to 1 and avoided the above bugs or issues (in Fedora, open-iscsi and kubelet)
All users running cStor with Fedora 29 are advised to upgrade to 0.8.1 release.
Documentation improvements
Our docs also received significant improvements. Simplified instructions and getting-started steps are provided to new users, and more troubleshooting scenarios are covered for advanced users. We have also certified cStor 0.8.1 for use with many stateful applications like GitLab, ElasticSearch, Minio, and Prometheus with the latest Helm charts and user documentation updated accordingly.
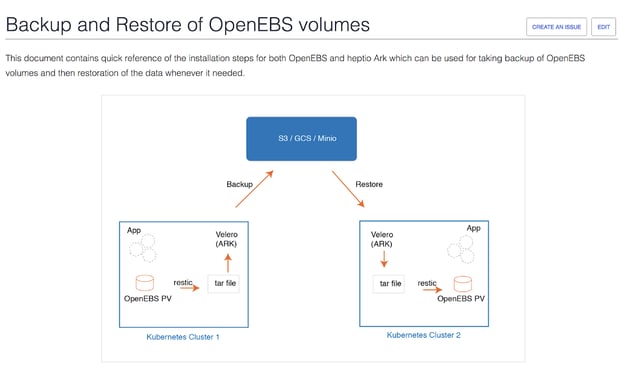
User guides for backup and restore and RWM support are also important parts of this new documentation.
Improved MayaOnline Capabilities
MayaOnline is always adding more features. You can now debug your OpenEBS-powered Kubernetes cluster even more easily. With the recently added logs feature, OpenEBS volume and pool pod logs are now automatically uploaded and available to you on MayaOnline. You can run a pod describe of any Kubernetes resources in the topology view. This requires only two clicks to get to any Kubernetes resource-describe.
Summary:
As stated before, we recommend all cStor users upgrade to 0.8.1. We always welcome your feedback, so if you would like to see a new feature or need to report a problem, write a GitHub issue at https://github.com/openebs/openebs/issues.
Join our slack community at https://slack.openebs.io
Enjoy using the 0.8.1 code! :)
. . .
Other Notable Additions
Liveness Check for cStorPool Pods
Sometimes when using network disks such as cloud provider disks or iSCSI disks from local SAN, it is common to experience intermittent disconnection of locally mounted disks. In such scenarios, cStorPool could move into a suspended state and require a restart of the cStorPool instance pod on that node. A liveness check probe has been added in 0.8.1 to help fix this issue. In the event of network disks undergoing a network connection flip, the disks get disconnected, cStorPool instance becomes unresponsive, liveness check probe restarts the pod and disk connections are re-established.
Because cStor volumes are replicated into three cStorPool instances, losing a cStorPool instance temporarily because of a restart causes volumes to be resilvered from the other pools.
Ephemeral Disk Support
In 0.8.0, cStor does not provide high availability of the data if volumes are set up for replication across local disks of cloud providers such as AWS instance stores or GCP local SSDs. The local SSDs on cloud providers do not retain the data when the VMs are rebooted because a completely new VM is provisioned with newly formatted local disks. This scenario was also discussed in another blog post and in the 0.8.0 docs.
Ephemeral disk support is also added for cStorPools in 0.8.1. Now, users can use AWS instance stores or any other ephemeral local SSDs for setting up a highly available Kubernetes native cloud storage across zones for their stateful needs. When a Kubernetes node is lost, a new node arises with the same label and the same number of disks. OpenEBS detects this new node and a new cStorPool instance is also created. After the pool instance is set up, cStor rebuilds the volume replicas into the new cStorPool instance from the other volume replicas. During this entire process, the volume replica quorum needs to be maintained. For more details on this feature, see the docs section.
Support to Extend cStorPools onto New Nodes
cStorPools expansion feature is another good addition in this release. In 0.8.0, the pools, once set up, could not be expanded to new nodes. In 0.8.1, support is added to expand StoragePoolClaim configuration to include more nodes. For example, if you have a StoragePoolClaim config with disks from 3 nodes, and if you are want to add a new cStorPool instance, you can add the disk CRs from the new node to spc-config.yaml and mark the max pools as 4. Once you apply the new spc-config.yaml, the pool configuration will be increased to 4 cStorPool instances.
cStor targetNodeSelector Policy
Setting node selectors to targets were limited exclusively to Jiva in 0.8.0. In this release, this policy is extended to cstor as well. With this feature, you can limit the cStorController pod scheduling to one or a set of nodes in the cluster, which gives flexibility to the administrator in managing the resources across nodes.
Jiva Replicas not Loading when Data is Fragmented
When Jiva volumes are deeply fragmented, the number of file extends increases to a large number. In such a situation, Jiva replicas were not able to load within a specified time limit, and re-connection was also resulting in the same issue. The 0.8.1 release fixes this issue and Jiva replicas load without issue, even when they are highly fragmented.
This article was first published on Feb 25, 2019 on OpenEBS's Medium Account





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu