

My heartfelt gratitude to hundreds of contributors and thousands of users and friends of OpenEBS who have contributed to OpenEBS becoming a CNCF Sandbox Project.
 https://www.cncf.io/sandbox-projects/
https://www.cncf.io/sandbox-projects/
For those of you who have just heard of OpenEBS or are curious about the current state of OpenEBS, I put together this quick blog that Looks back to where we started and how far we have come. (I am pretty sure the GOT fans will get this reference). I then talk about the current release 0.9 and what is to come in 1.0.
The OpenEBS vision has been pretty clear since the start: provide an Open Source Storage Solution that enables Enterprises and Solution Architects to reap the Agility benefits promised by Container Native Architectures. We decided a few years ago that delivering data agility could best be done by using the tools that deliver agility in development and operations already — cloud native architectures, including containers and Kubernetes. Specifically we decided to move Stateful Workloads and the logic that delivers storage services to protect and manage them into a microservices based architecture deployed via containers. We also set out to enable agility by fighting the lock-in of data into vendor and cloud specific storage silos that lock users into specialized systems and services that themselves require special skills to run and scale.
Over the last couple of years the notion of containerizing stateful workloads and managing them via Kubernetes has become increasingly accepted. We now see a great breadth of deployments of different workloads on different flavors of Kubernetes — you can read more about how the pattern of cloud native or what we call Container Attached Storage is being adopted on the CNCF blog we helped author here: A Year Later — Updating Container Attached Storage.
Quick point that you may have already gathered: OpenEBS is completely Kubernetes native and if you know how to manage your applications in Kubernetes, you already know how to use OpenEBS.
So, OpenEBS started out to build a Storage Solution that has:
- Stable Date Engines, can be run on any underlying Kubernetes Platform. And it has got to be multiple storage engines, so administrators can compose or pick the right one for the right workload. For instance, an OpenEBS PV for Mongo can be using a completely different data engine compared to a PV for PostgreSQL or Jenkins.
- Standard Specs to manage the Data Engines, so that administrators can use the existing Kubernetes tooling infrastructure to manage storage as well. Kubernetes Custom Resources and operators are used to manage everything with regards to OpenEBS.
- Security controls that enable running on platforms like OpenShift, SuSE CAAS or in Kubernetes Clusters with strict Pod Security Policy.
- Scalable architecture that can deliver the required performance to the Application, without adding much of an overhead over the underlying storage medium.
And above all, it has to be simple and easy to use.
It feels great for OpenEBS to be approaching 1.0!! We are extremely humbled at the amount of love in terms of both support and scrutiny that we have received over the last couple of years as we went through with building each block by block completely in the Open Source. OpenEBS has clearly established itself as the most simple to use and cost effective storage solution that is available out there to use with Kubernetes — and yet we know there is much more to do, especially as there seems to be a risk of higher level commands such as those covering data mobility being pulled back from Kubernetes into their own systems by proprietary vendors. More on that in a later blog and/or set of GitHub issues :) .
In the following sections, I go through in a bit more detail the current state of the main aspects of OpenEBS — Stability, Standard Spec (aka Storage Policies), Security Controls and Scalable architecture; followed by a quick summary of the current release (0.9) and what we are working on currently for v1.0.
Data Engines: The data engines are the containers responsible for interfacing with the underlying storage devices or cloud volumes such as host filesystem, rotational drives, SSDs and NVMe devices. The data engines provide volumes with required capabilities like high availability, snapshots, clones, etc. Depending on the capabilities required, users can select the right data engine like cStor ( a CoW based) or Jiva or even Local PVs for a given volume.
We define a data engine as stable if it meets the following criteria:
- Resilient against node, network or storage device errors. No data loss!
- Ease of management ( including Day 2 Operations).
- Users are running the data engine in production for more than 6 months and have gone through two or more OpenEBS version upgrades.
The current state of the 3 data engines supported by OpenEBS are as follows:
- Jiva (stable) — The first and basic data engine that was supported by OpenEBS and has been deployed the longest in production by users. We have fixed several issues that came up with regards to cluster upgrades, node migrations, storage expansion and so forth. Ideal for cases where only replication of data is required. For backup and restore, Velero/Restic is used. Very easy to use, lightweight.
- cStor (beta) — The most feature rich data engine that has the support for extremely efficient snapshots and clones. Highly recommended for cases where the nodes have storage devices attached. The current release contains Velero OpenEBS plugins that help with optimizing the backup/restore process. While already used in production by some of our users, we consider this as beta — until all day 2 operations are easily performed.
- OpenEBS Local PV (alpha) — An extension to Kubernetes Local PV, with the plan to ease the management of disks by using the OpenEBS Node Storage Device Manager (NDM). The current OpenEBS 0.9 release contains the initial version of the OpenEBS Local PV Dynamic Provisioner. While we have tested OpenEBS Local PV extensively however per the criteria above it remains alpha as the newest engine. From an IO engine perspective, it is as stable as it can get. :-)
Additional details and how each of the Data engines operate are provided in this Presentation
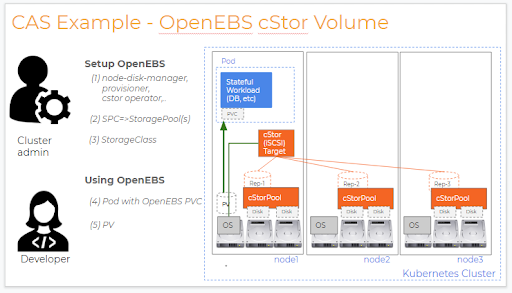
Standard Specifications or API: Standardization is achieved by architecting OpenEBS as a set of microservices using Kubernetes Custom Resources and Operator patterns. The same set of tooling used to manage the applications — like Helm, Prometheus, and Grafana — can also be used to manage OpenEBS itself. The configuration of OpenEBS is completely controlled via YAMLs (Custom Resources) and volumes are provisioned via the Kubernetes Dynamic Provisioners, Storage Classes and Persistent Volume Claims.
The components of OpenEBS that act on the user requests (via CRs) and generate / launch the Kubernetes Objects — like Deployments, Services and Persistent Volumes are collectively called as the Storage Management or Control Plane. The interactions to the Storage Management Plane can achieved via `kubectl`.
The administrators can customize the OpenEBS parameters by modifying the YAMLs. Some of the configuration that are possible are:
- Setting up Taints and Tolerations to decide the nodes where the Storage Pods need to be deployed.
- Setting up the Node Selectors or Anti-Affinity parameters to select the correct nodes for launching the Volume (Data Engine) pods.
For further details check: https://docs.openebs.io.
Another cool feature that has become a favorite of advanced OpenEBS users is that, as Kubernetes introduces new features that have to be passed on to the Dynamically generated Volume (Data Engine) Pods, users can directly patch the pods and also update the Volume Template YAMLs at run time. To learn more about this feature, hit us up on slack: https://slack.openebs.io
In this regard, as we move towards 1.0, we would like to improve the documentation and governance around maintaining multiple versions of the API.
Security Controls: Storage is a cluster add-on service. It needs to access the storage devices — either as hostpath or as block devices that are attached to the nodes. Since OpenEBS is completely Kubernetes native, access rights and privileges required by the individual components are completely transparent and can be controlled by the RBAC configuration by Kubernetes Cluster Administrators. One of the interesting feedback we received as Enterprises started to adopt OpenEBS was that — the IT Teams want to retain the control on the storage and shield the specifics of the node details or scheduling details from application developers.
OpenEBS can now be configured easily to run in:
- Security Enhanced Linux Platforms (selinux=on) like RHEL, CentOS or OpenShift. We talk in more detail about this here.
- OpenEBS can be used on clusters where the default setting is to not grant access to the hostpaths for Developer namespaces. To support this use case, we now support an option to run the Jiva Volumes Pods (that require access to hostpath) to be deployed in OpenEBS Namespace using a StoragePolicy — DeployInOpenEBSNamespace. The StoragePolicies in OpenEBS are configured via StorageClasses.
- OpenEBS can be used on clusters enabled with Pod Security Policies. The PSP for OpenEBS has been contributed by a user and can be found here.
Scale and Performance: OpenEBS is architected to horizontally scalable with nodes — Persistent Volumes spreading out pretty evenly across the nodes or a subset of nodes designated for Storage. However the data of any given Persistent Volume is always fixed to a specific set of nodes, eliminating the need for expensive metadata lookups to find the data blocks as the number nodes get higher. What I like even better is, that the replica tells the controller that it has the data effectively inversing the responsibility from volume target/controller having to know where data is located to replicas telling I have the data.
Another aspect of OpenEBS Volumes when it comes to performance is that each Volume is completely isolated and doesn’t get impacted by work/load on other Volumes. For example, a node rebuild will not degrade ALL volumes in the cluster.
As OpenEBS is completely developed in user space and run as Kubernetes Pods, administrators get completely control on the resources like CPU/RAM that should be allocated to Storage. There won’t be cases of kernels hogging all the resources. Administrators also can tune for example the number of threads allocated and parallel IOs supported per Volume — tuning will have impact depending on the type of workloads (Sequential / Random).
Of course, then we have workloads that require low latency, and need to work to be deployed on nodes with limited storage available, for example a couple of NVMe devices. OpenEBS Local PVs provide the functionality to make use of the Local Storage and help with dynamic provisioning of Local PVs. OpenEBS Local PVs offer an excellent choice for cases like NuoDB where replication is inherently taken by NuoDB itself and the expectation is only to get a persistent storage with node affinity configured for the storage pods. A default storage class called — `openebs-hostpath` is available in the current release. Check it out and let us know what you think.
We are seeing OpenEBS users progress from running CI/CD workloads in staging to now running critical databases in production on OpenEBS Volumes. If you are interested in performance, we have a OpenEBS user currently exploring and sharing the benchmarking numbers on several different platforms. Join the discussion on our slack — https://slack.openebs.io.
— -
While I covered earlier some of the items introduced recently in 0.9, here is a summary of some significant changes:
- Introduction of Dynamically provisioned OpenEBS Local PVs for making use of the storage available on the nodes itself for running NewSQL kind workloads. Refer to this blog to get started with OpenEBS Local PVs.
- Enhanced the cStor Replica distribution logic for MongoDB or Cassandra Statefulsets to provide storage high availability and reducing the performance overhead
- Backup and Restore processes for cStor Volumes using OpenEBS Velero Plugin that can perform incremental snapshot backup and restore.
- Enhance the Deployment and Placement of the Jiva Volume Pods to facilitate working in environments with strict Pod Security Policies and for Kubernetes clusters that tend to see a lot of pod evictions or node drains.
- Introduced Web Admission Hook that will help with validation and avoiding misconfigurations.
- Developed an upgrade framework using the CAS Templates that will help developing operator based upgrades from earlier releases to the current release. We are excited to use this framework for upgrading from 0.8.2 to 0.9
- Enhanced the Prometheus exporters to support generating cStor Volume Replica metrics.
- As always many other user reported issues made into this release. To learn more checkout the release notes.
Each OpenEBS release goes through Litmus — GitLab Pipelines that verify new functionality, backward compatibility and also acceptance from users through pre-release build testing. Please reach out to us if you would like to be included in the pre-release notifications.
I am very excited about the following active contributions that are filling in the gaps for 1.0
- BDD tests that developers can execute as part of the feature development. This is an extension to the Sanity tests are executed in Travis CI and Litmus Tests in GitLab CI.
- Updating the Design, Contributor and Governance related details with the help of CNCF guidelines.
- Freezing on the cStor Specs based on the feedback received from users on how to make it more user friendly and easy to manage. The NDM Disk Specification has also changed to BlockDevice spec as per the feedback received in making it generic to Storage Devices.
- Additional enhancements automatic the cStor Day 2 operations with regards to scaling up the capacity of cStor Pool by increasing the size of the underlying disks, scaling up and down the number of cStor Pools in a given cluster.
- Support for integrating the OpenEBS Local PV into the BlockDevices discovered and managed by NDM.
- Support for ARM builds.
For contributing to the above feature or learning more about them, you can reach out to us on the #contributors channel or check out the milestones.
I am very excited to be at KubeCon Europe and to meet in person some of the hundreds of contributors and many thousands of users of OpenEBS who have all made it possible for OpenEBS to be recently accepted as a CNCF Sandbox Project. Thank you Again!
MayaData will be speaking about OpenEBS at the KubeCon events in Barcelona in the Cloud Native Storage Day and Open Data Autonomy Mini Summit on May 20th, and also at booth SE41 until Thursday in KubeCon Expo Hall.
This article was first published on May 16, 2019 on OpenEBS's Medium Account





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu