

Congratulations and thanks to each one of you from the OpenEBS community for reaching this significant milestone!
In this blog, I will touch upon what I have learned from users about Open Source CAS solutions like OpenEBS at KubeCon EU 19, followed by a quick note on the major changes in 1.0 and what is in the immediate roadmap.
Being an active member of the OpenEBS Slack channel and from the usage statistics, I was cognizant of the vibrant user community. For instance, a recent usage report generated by MayaData since 0.8 was released, OpenEBS is running on — 340 different flavors of Operating Systems, 90 different flavors of Kubernetes and across 75 different countries.
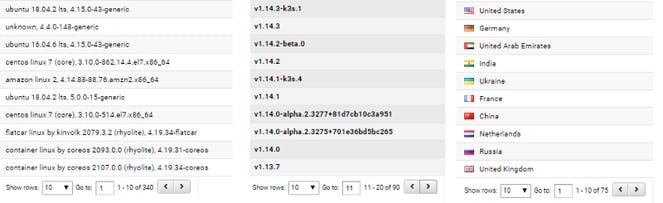
KubeCon EU 19, was by far the most interesting for me — to interact with some of the above users who are already running OpenEBS in production or in the process of evaluation. For those of you, curious about the kind of views expressed from users and the partner community about OpenEBS and Kubernetes Storage at large, here are some interesting ones:
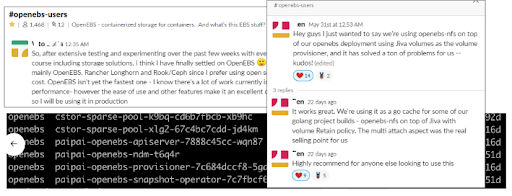
Feedback from Users running OpenEBS in production. The choice to adopt OpenEBS was made after evaluating and comparing other available solutions as can be seen from several stories shared by the users:
This growing adoption is attributed to the following:
- The major one being the architectural superiority of using Kubernetes to build highly portable distributed systems — and not locking all the applications into a single point of failure — by making them write into storage system run by some other group or provider. OpenEBS helps to build a storage solution where each application gets its own storage controllers. This is a perfect validation of the Container Attached Storage Category, which is explained in more detail at a CNCF Blog.
- Containerized distributed applications are much smarter than their legacy server-based counterparts and these new containerized applications don’t have the same dependency on the storage system as before. What applications need are ala-carte of Storage Solutions that OpenEBS offers as Storage Engines. Depending on the application needs, cluster administrators can decide what components of OpenEBS are really deployed. For example — does the cluster need to only have Local PVs or a full-fledged storage solution like cStor.
- Of course the fact the OpenEBS itself is completely developed in user space and just runs on any platform easily. No kernel taints required. Yes, currently with 1.0 — there is a performance hit, but there are enough use cases where the current performance is good enough.
Words just can’t express the joy of hearing directly from users on how OpenEBS has helped them. It is just amazing to see the diversity of users as well; from universities to financial corporations, startups to enterprises, fresher to seasoned SREs.
Personally, the most humbling moment for me at the KubeCon EU 2019, was when an end-user approached me just to thank for the efforts we have put into OpenEBS. He works at a University as a SysAdmin and he mentioned that using OpenEBS — he is able to spin up a self-contained Kubernetes Cluster with host storage that can be used by the stateful applications. This has helped in the number of support calls he receives from the University IT department when rolling out Stateful Applications that needed some hand-holding to provide the PVs.
A similar sentiment is being expressed by large enterprises where the Infra team is supposed to roll out services to 100s of there application teams, in a more agile and uniform way than before. Some of the enterprises run Big Data pipelines at mammoth scale and have found OpenEBS to contains the right set of abstractions that can be extended and used.
Feedback from the growing community and partner ecosystem that comprises of individual contributors, home users, enterprise solution architects, technology enthusiasts to hardware vendors included:
- Solution Architects, DevOps, SREs >> I have put together a few scripts to make backups and restores with the Velero plugin for cStor volumes a little easier, since there are some parameters to remember and some additional steps required for both backups and restores other than using the basic Velero commands. I created a tool for velero openebs — with a few notes in a comment, in case anyone is interested
- Storage Solution Engineers >> Hey, I know OpenEBS was not meant for this — but I think I made some changes can now serve Volumes from Kubernetes Cluster to Virtual Machines. A custom SDS, if you will, that is developed using OpenEBS.
- Storage Vendors >> We are a storage devices company and OpenEBS can be used to run in an optimized way and help us shift storage boxes.
- Kubernetes Managed Service Providers >> It will be cool to have OpenEBS available via the Operator Hub/Marketplace.
Clearly, these days the discussions at KubeCon EU are not around What or Why OpenEBS? but around When a specific feature is going to be made available. While the top requests with regards to missing features were around CSI support, automation of the operations like — disk provisioning and capacity expansion and performance improvements — they were really not blocking users from running OpenEBS in production. There are lots of users out there, that have found the current performance offered by the OpenEBS Data Engines was good enough for their use cases, and they have gone ahead and implemented playbooks and tools for performing maintenance and monitoring operations.
Post KubeCon, having known and also met in person some of these early adopters that are running OpenEBS in production with a set of home-grown solutions, we felt a sense of responsibility to release 1.0 at the earliest and promise to provide long term support on the current feature set. As we progress with implementing additional functionality around operators, CSI, supporting the latest from Kubernetes Storage, and so forth we are also making a commitment that the current version will be supported.
Hence, for 1.0 — we changed our gears a bit to focus on helping address the feedback received on the existing feature sets for all the three data engines now supported by OpenEBS and deployed in production- Jiva, cStor Data Engines and Local PV.
Some significant changes in 1.0 are as follows:
Enhanced Lifecycle Management of Block Devices. The component of OpenEBS — NDM — Node Disk Manager or Node (Storage) Device Manager as we call it now, has been enhanced to support Block Device Claim (BDC). A new NDM Operator has been introduced in 1.0, that helps to request and reserve a Block Device before using that for either creating Local PV or cStor Pool. NDM is also being used independently of OpenEBS Storage Engines, and the ability to claim a Block Device — similar to PVC — enables the sharing of the block devices without stepping on each other.
Block Device(BD) is a new CR — which is a preferred way to represent a storage device than a Disk CR ( which was used in earlier releases.) Disk CR are also present — to allow for backward compatibility. The cStor Data engines and Local PVs that typically use block devices have been enhanced to use BDC/BD in place of Disk.
When a BDC is deleted, the BD is released. And before it can be claimed by another BDC, the NDM takes care of deleting the data that has been written from the previous consumer. The cleaner utility used is derived from the Kubernetes Local PV cleaner jobs.
Enhance the OpenEBS Local PV to be used with Block Devices. In the previous release, we introduced Local PVs that can be used with a hostpath, in this release, we have added support to create a Local PV directly on a Block Device (discovered by NDM). The Block Device can either be a raw block device (Example: GPD) — in which case it will be formatted (Example: Local SSDs on GKE) with the requested filesystem type or already mounted block device.
Also included in this release are:
- Bug fixes reported around the cStor and Jiva data engines that surface after running OpenEBS on nodes that experience frequent reboots.
- Additional debugging tools for cStor and Jiva engines, jivactl being the significant one that will help with clearing up of older snapshots. This tool has to be used to clear older snapshots to avoid hitting a cap limit of 255 snapshots in older releases.
- Added few more Prometheus monitoring metrics
- Added several e2e tests and included more applications into the OpenEBS CI pipeline maintained by MayaData at openebs.ci
For detailed changes summary, please check the OpenEBS 1.0 Changelog.
Please refer to the OpenEBS Documentation to get started.
OpenEBS 1.0 — ships with multiple Data Engines to choose from depending on your application needs:
- OpenEBS Jiva PVs — can be used if your kubernetes nodes don’t have the capability to add raw block devices, but have extra capacity available on the host filesystem. This is the first and the longest running in production with lots of Kubernetes tunables available like — to customize the location where data is saved, the specific nodes on which data needs to be replicated — within or across availability zones, setup the volumes for thin provisioning, and so forth.
- OpenEBS cStor PVs — is the preferred option when your nodes have raw block devices. cStor Data Engine continues to be a preferred solution for use cases that require instant snapshot and clone of volumes.
- OpenEBS Local PVs — best suited for applications that can do their own replication and require high performance. OpenEBS Local PVs can work with either hostpath or with block devices that are already attached to the nodes.
There are a lot of options available to customize from the type of block devices that can be used for OpenEBS volumes to customizing the resources allocated to the Storage Pods.
OpenEBS has turned a new leaf in its journey by releasing version 1.0. Thank you for all the support and love that you have shown along this journey. We are forever more committed to learn from you and help you realize the Data Agility that Cloud Native promises to offer.
Our immediate focus is on getting OpenEBS ready for CSI and enhancing the OpenEBS Operators — for managing the Day 2 operations like dealing with Kubernetes upgrades, ASG, expansion of cStor Pool capacity or migrating them to new nodes and so forth. Development on these items is being tracked in the Kubernetes style at Product Planning Sheet.
Thanks to CNCF, we have the following mailing lists to connect apart from the Slack.
- For OpenEBS project updates — subscribe to https://lists.cncf.io/g/cncf-openebs-announcements
- For interacting with other openebs users, you can either join the Slack, raise issues on Github or send an email to https://lists.cncf.io/g/cncf-openebs-users
As always, I am eager to learn from you. Please hit me up on twitter (@kiranmova), slack or on here in the comments.
Thanks to Murat Karslioglu. Public domain.
This article was first published on Jun 25, 2018 on OpenEBS's Medium Account





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu