

Versioning Open Source software has its own thrills. Often, it is a reminder of progress made by the community over a while, in realizing an idea seeded in the (recent) past, but continuously evolving as participation and thereby, insights grow. Having said that, the journey involved in the incremental conversion of an “idea” into working, production-ready code, and then building on it never ceases. The 1.0 release of the LitmusChaos project, a milestone as it is, is also just another monthly release by the LitmusChaos community. The main objective of this release is to make the chaos charts (experiment and engine CRDs) more user-friendly and meaningful, apart from the regular focus on adding newer chaos experiments, improving the stability of framework components, enriching the documentation & adopting more project, community best-practices.
.png?width=628&name=Happy%20Makarsankranti!%20(6).png)
What we mean by increasing the user-friendliness of the charts, or rather the experiments, is that they are more explicit and helpful in terms of scope (blast radius), intent (what exactly can we do/check), installation (call out issues before execution) and usage trends (which type of chaos is most common?). Let’s take a look at how this is being achieved along with other noteworthy inclusions in this release.
Scope Of a Chaos Experiment
One of the ways to interpret the scope of chaos experiments has been about whether it would impact “other” applications. This is referred to as the “blast radius” of the experiment. While some experiments affect only the application deployment under test (and indirectly, other apps/pods in the application stack that “depend” on the availability of the AUT), there are some experiments that can bring down several apps due to the inherent nature of the chaos inflicted. The latter typically involves fault injection into infrastructure/cluster components such as nodes, disks, etc., and are deemed to have a higher blast radius.
Another popular interpretation, especially amongst DevOps admins, is around the minimal “permissions” (read RBAC, i.e., role-based-access-control) with which an experiment is executed, i.e., whether it is namespace-scoped or cluster-scoped, what are the Kubernetes resources that shall be accessed by the experiment and what are the actions performed against these? More often than not, the infrastructure chaos experiments need “wider” permissions to perform better health checks (more on this in the next section) and are mapped to ClusterRoles over namespaced Roles (though the resources accessed might not be as many). There are also implications for the execution flow of such experiments. For example, annotation checks against specific apps do not make much sense in case of infra chaos experiments!
In this release, the chaos CR specifications have been refined to indicate the above details. The .spec.definition.scope & .spec.definition.permissions in chaosExperiment CR make clear what kind of role the chaosServiceAccount should be bound to in order to successfully execute the experiment. Note that, though the earlier releases did bring in the concept of permissions, in this release, the minimal-required permissions and its scope have been delineated!
...
metadata:
name: pod-cpu-hog
version: 0.1.2
spec:
definition:
scope: Namespaced
permissions:
- apiGroups:
- ""
- "batch"
- "litmuschaos.io"
resources:
- "jobs"
- "pods"
- "chaosengines"
- "chaosexperiments"
- "chaosresults"
verbs:
- "create"
- "list"
- "get"
- "patch"
- "delete"
...
On the other hand, the ChaosEngine CR now consists of a property .spec.chaosType that indicates the blast-radius of the experiment. The values are also used to determine the workflow of the experiments. This information is also conveyed to the user on the ChartHub using an icon on the experiment cards.
...
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: nginx-chaos
namespace: default
spec:
# It can be app/infra
chaosType: 'infra'
...

Pre-Post Chaos Health Check
The previous section touched upon laying out the scope of the experiment. One of the factors associated with the permissions, or in some ways, the one that determines it, is the checks performed before and after injection of chaos. When the blast radius is higher, the user needs to know the state of important applications which may be spread across different namespaces. Often the selection of the infra component is made based on a primary application deployment using it, but the health checks might have to be done for several others. In this release, the ChaosEngine provides an additional tunable called .spec.auxiliaryAppInfo, which allows for defining a comma-separated list of the namespace:application-labels key-value pairs apart from the standard .spec.appinfo (in which the primary app details are mentioned). This information is used by the experiments to perform health checks against each app deployment mentioned, thereby verifying the overall impact of the chaos injected.
...
spec:
chaosType: 'infra'
auxiliaryAppInfo: 'mysql:percona,proxy:nginx'
appinfo:
appns: default
applabel: 'app=nginx'
appkind: deployment
...
Schema Validation for Chaos CRDs
One of our initial observations (and of course feedback) was about how a lot of “experiment failures” were a result of malformed/incomplete structures or invalid values provided in the user fields of the chaos CRs. While the previous release saw some amount of validation added in the executor/runner code to identify these, it still involved spawning the runner pods before identifying the issues. In this release, the CRDs have been updated to adhere to the OpenAPIV3 schema standards, which allow the definition of a strict structural schema with validation (including pattern matching, required values, min/max item counts, etc.,) for the values. This helps in pre-empting failures related to schema definitions by calling out the errors right at the time of the creation of the custom resource in the cluster. The detailed schema can be viewed here.
Example validation for ChaosEngine with pattern matching for spec items:
validation failure list:
spec.appinfo.appkind in body should match '^(deployment|statefulset|daemonset)$'
spec.jobCleanUpPolicy in body should match '^(delete|retain)$'
Example validation for ChaosExperiment with malformed configmap/secret spec:
validation failure list:
spec.definition.secrets in body must be of type array: "null"
spec.definition.configmaps.mountPath in body must be of type string: "null"
spec.definition.configmaps.name in body must be of type string: "null"
Additions to Generic (Kubernetes) Chaos Experiment Suite
Following the trend in the 0.9 release, the generic Kubernetes chart continues to be consolidated with more chaos scenarios. This release introduces the following chaos experiments:
Pod CPU Hog
While the generic suite consists of a node (infra) level CPU hog experiment, we added a container/pod level CPU stress as it is common for application containers to experience sporadic CPU spikes during periods of high activity, especially when there are fewer replicas and (horizontal pod) autoscale functionalities are not set up (as with some self-managed clusters). This can impact the overall application stack, cause slowness/unresponsive conditions. This experiment takes a CPU_CORES env variable and consumes/utilizes the cores upwards of 80% (provided it is available; else, the utilization ends up being balanced across the chaos processes injected).
experiments:
- name: pod-cpu-hog
spec:
components:
- name: TARGET_CONTAINER
value: 'nginx'
- name: CPU_CORES
#number of cpu cores to be consumed
#verify the resources the app has been launched with
value: "1"
- name: TOTAL_CHAOS_DURATION
value: "90"Pod Network Corruption
This experiment adds to the pod network chaos suite (network delay/latency, network packet loss). It uses Pumba (which in turn uses tc’s netem utility) to inject random noise into a chosen percentage of network packets, with a higher percentage leading to similar behavior as network loss, i.e., inaccessibility.
experiments:
- name: pod-network-corruption
spec:
components:
- name: ANSIBLE_STDOUT_CALLBACK
value: default
- name: TARGET_CONTAINER
value: "nginx"
- name: NETWORK_INTERFACE
value: eth0
# in percentage
- name: NETWORK_PACKET_CORRUPTION_PERCENTAGE
value: ‘50’Node Drain
An infra chaos experiment, it simulates graceful shutdown/loss of a Kubernetes node by evicting all the scheduled pods. Node drain is a very common action performed during cluster maintenance. It is an intentional admin operation that is expected to occur multiple times over the lifetime of a Kubernetes cluster. Eviction of application replicas can sometimes lead to unstable behavior/downtime if deployment sanity (application cluster quorum, pod disruption budget, etc.) is not maintained. This experiment is a prime use-case for the specification of auxiliaryAppInfo in the ChaosEngine.
experiments:
- name: node-drain
spec:
components:
# set node name
- name: APP_NODE
value: 'node-1'Introducing CoreDNS Chaos Experiments
The creation of application-specific or application-aware chaos experiments is one of the core objectives of the Litmus project. After Kafka, we picked CoreDNS as the next app for which to create chaos experiments. A major part of countless production clusters, CoreDNS is a graduated CNCF project that serves as the cluster DNS and resides in the Kube-system namespace. One of the inspirations in picking up this application was the fact that as an infra piece that is critical to service resolution, it is imperative to ensure that it is sufficiently replicated, has the right resource requests/limits set, and can survive DNS query bursts. A classic case of DNS chaos can be found here. While these configuration parameters vary across setups and use-cases, it is important to hypothesize about the impact certain scenarios can cause and test them out. In this release, we have introduced a simple, yet important pod failure chaos scenario that can test the stability of the cluster DNS server, when implemented under the right load, duration, and kill count.

A sample nginx test app with an external liveness client that continuously queries (with a low wait threshold) the nginx app form the (pre & post chaos) health check infrastructure while the DNS replicas are killed randomly. As with Kafka, more experiments will be added to the CoreDNS chart in upcoming releases.
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-coredns
namespace: kube-system
spec:
appinfo:
appns: kube-system
applabel: 'k8s-app=kube-dns'
appkind: deployment
# It can be infra only
chaosType: 'infra'
components:
runner:
image: "litmuschaos/chaos-executor:1.0.0"
type: "go"
chaosServiceAccount: coredns-sa
monitoring: false
# It can be delete/retain
jobCleanUpPolicy: delete
experiments:
- name: coredns-pod-delete
spec:
components:
# set chaos duration (in sec) as desired
- name: TOTAL_CHAOS_DURATION
value: '30'
# set chaos interval (in sec) as desired
- name: CHAOS_INTERVAL
value: '10'
- name: APP_NAMESPACE
value: 'kube-system'
# provide application labels
- name: APP_LABEL
value: 'k8s-app=kube-dns'
# provide application kind
- name: APP_KIND
value: 'deployment'
- name: CHAOS_NAMESPACE
value: 'kube-system'
Stabilizing the LitmusChaos Framework Components
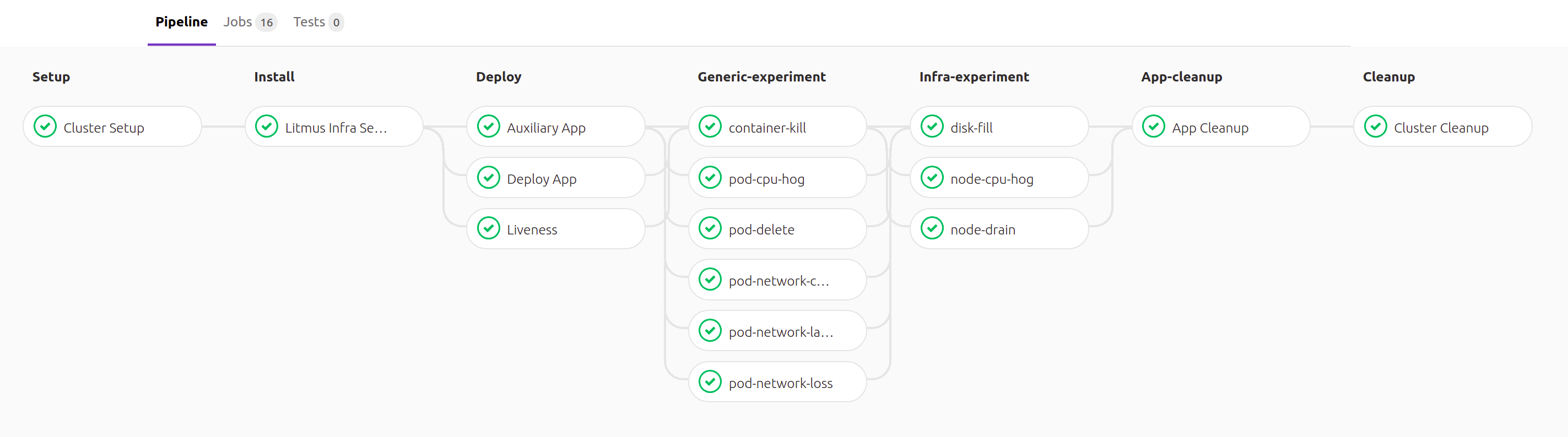
As part of the stabilization efforts, the Go Chaos Runner has been upgraded to Beta after undergoing significant refactor to achieve compliance with the BetterCodeHub quality standards. Besides, this release also introduces Gitlab pipelines for the build, deploy and e2e test of the Chaos experiments. As it continues to pick up in quantity of BDD tests, the deploy pipeline today runs an automated e2e/smoke-test suite that verifies the experiment artifacts and business logic by validating whether the chaos injection has occurred successfully. The experiment litmus (play) books, too, were audited for missing failure paths and cleanup routines.
Increased Experiment Context on the Chart Hub
With this release, the ChartHub features increased information about the chaos experiments in terms of litmusbook source code link, maturity, platform support, and documentation links on the respective experiment page. Another exciting enhancement introduced in this release is to capture usage trends on the experiments (via GoogleAnalytics), with a total live experiment run counter displaying near-real-time statistics of experiment CR installation/runs. With this, we can now discern the nature and scope of chaos practices, thereby helping us come up with more relevant chaos experiments in the future. It is also helpful for users to learn about the general trends prevalent in this area.

Documentation Improvements
The docs enhancement for this release comes in the form of short video tutorials for each experiment to reduce the entry barrier for those getting started with the practice of Chaos Engineering. Also included are sample RBAC manifests featuring the minimum required permissions for the execution of the respective experiments.
Ex: https://asciinema.org/a/MOPQfmzA5NxgBs8DkMGROXpQw (embed video)
Project & Community Initiatives
Group PR Reviews
Some of the teething issues we were facing as a community when new contributors came in were (a) the variance in coding practices (mainly in case of experiments), naming conventions, directory/folder structures adopted, etc., which were leading to considerable to-and-fro in PR reviews, and (b) the skewed ratio of the volume of PRs coming in v/s the number of actual reviewers. Some PRs were smaller, some much larger, but all of the critical/important to the project and, therefore, equally worthy of complete attention. One of the approaches we have adopted to mitigate these issues is doing Group PR Reviews (esp. for functional changes and also on-demand). Typically the reviewers go through the PR individually before synching up for a show-and-tell session by the PR author during which further review comments are shared or resolved, thereby getting onto the same page quicker. It also provides an opportunity for interested contributors to join in and develop a holistic perspective of the project and eventually aid with reviews. While this approach is subject to scaling issues (in fact, enough has been documented about its merits and demerits), we would like to use it in conjunction with other established practices such as the creation of style guides & improved developer documentation. For now, though, feel free to call out for group-review over the Litmus Slack Channel if you desire!
Monthly Community Sync Up
The Litmus Community has now decided to sync up once every month, on the third Wednesday at 8.30 AM PST/10.00 PM IST to review the release gone by, discuss roadmap items, present/demonstrate features the contributors have been working on… and just to meet and greet! The notes from previous meetings are now maintained here. Feel free to add your topic of interest in the agenda to have it discussed.
Conclusion
The theme over the past couple of releases has been to strike a balance between stabilization of the framework/experiments and creation of new charts: basically, polish the stone. We look forward to more adoption and contributions in the year 2020 to help grow Litmus as the de-facto chaos engineering framework for Kubernetes. Some of the planned items for the subsequent releases include:
- Support stop/abort of chaos experiment execution
- Improved logs and events to describe the sequence of chaos execution
- Improved quality & test coverage of chaos components
- More pod/container level generic resource chaos experiments
Once again, special thanks to Laura Henning (@laumiH) for the network chaos PRs & doc reviews!





MayaData launching ChaosNative for LitmusChaos and more
Evan Powell
Evan Powell
New Kubera Release + Project Features
Paul Burt
Paul Burt
KubeCon EU 2020 - Virtual, Storage chatter round-up
Kiran Mova
Kiran Mova