

This article is part of a #ProjectUpdates series on Litmus. In this blog post, we will share the latest developments in the project, which was announced & open-sourced during the KubeCon Europe 2018.

The objective of the Litmus project is to help evaluate stateful workloads on Kubernetes via storage & infrastructure focused end-to-end (e2e) tests that use chaos engineering tools & principles, amongst other aids, with the test cases executed as Kubernetes jobs. Over the last 10 months, there have been several improvements to the framework based on community feedback alongside an increase in the test library. The focus areas & improvements through this period, ongoing efforts & upcoming features have been summarised in the subsequent sections.
Increased application & use-case coverage
While the initial focus of Litmus centered around creating a K8s native approach to e2e (via test containers deployed as jobs) & facilitating a simpler interface for users to define & generate tests via English-like sentences (using godog), subsequent feedback from the extremely vibrant & involved OpenEBS community highlighted the need for users to be able to pick test cases, i.e., deployable test jobs from an existing test library to enable quick turnaround time for stateful workload evaluation. As a result, the existing ansible-based utils were extended.
Litmus now includes support for multiple popular stateful applications (Percona MySQL, MongoDB, Apache Cassandra, MongoDB, Minio, Crunchy PostgreSQL, NuoDB, Prometheus etc..,) whilst covering common app lifecycle scenarios such as deployment, load, reschedule, scale-up, upgrade & de-provision. Also included are test jobs to verify the resiliency of these workloads against intermittent and permanent failures to persistent storage & cluster infrastructure, with these failures induced via chaos tools.
Refactoring Litmus into a more “microservice-oriented” model
One of the principles in the microservices world involves compartmentalization of an application service into several pieces to enable greater flexibility & control in administration. When the Litmus project was started, the entire workflow of the test: right from application deployment, through test business logic to clean up was embedded into a single job. While this continues to be a viable model in some circumstances, managing multiple user inputs/permutations at each stage of the workflow meant handling this in a single job would make the test a complex “monolith” & affect debuggability.
Continuous Integration (CI) pipelines
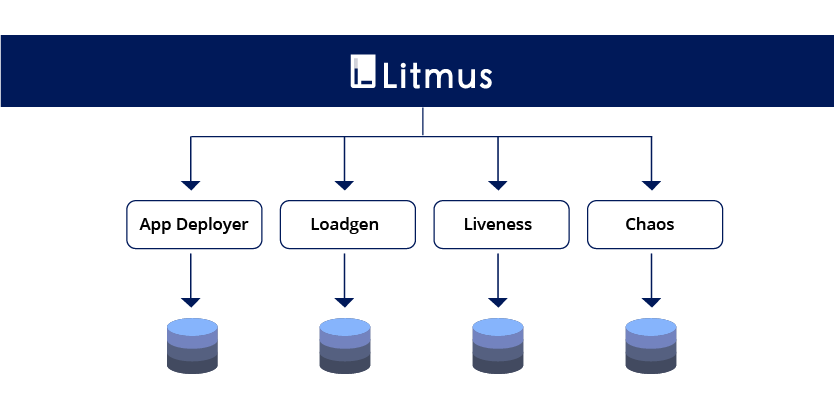
Another consideration was Litmus tests being used to drive Continuous Integration (CI) pipelines that aim to simulate user environments, where applications are typically soaked over a period of time undergoing various day-1/day-2-n ops while being resilient to component failures. This resulted in the creation of different categories of Litmus jobs (henceforth interchangeably referred to as Litmusbooks), which can be combined in a specific order to achieve an “e2e test” or “Litmus experiment”.
App Deployers/De-provisioners: Litmusbooks that take various parameters such as namespace, type, labels, liveness (IO) probes etc., to deploy or clean up the aforementioned applications.
Load generators: Generates both synthetic (fio, sysbench, dd) & app-specific (TPC-C, YCSB) IO load on the applications using custom containers simulating client behavior.
External liveness monitors: Monitors accessibility to an application server. While the standard K8s liveness/IO probes perform pod restarts to restore app server health, these external monitors test the seamless continuity of “end-applications” during the course of an app-lifecycle operation or chaos.
App/Storage lifecycle “operators”: Performs standard functional operations such as app/storage scale, backup/restore, reschedule, app/storage upgrades etc.., (should not be mistaken for actual “kubernetes operators”)
Chaos inducers: Litmusbooks that induce failures on specified targets on the cluster, including application replicas, storage & cluster infrastructure (network, nodes, disks, memory, CPU)
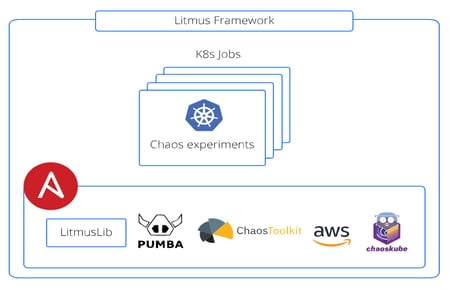
Litmus Frameworks
Typically, the lifecycle functionality & chaos litmusbooks include steps for post-test health checks on the application and persistent storage components, including data integrity validation. All the above requirements necessitated the creation of multiple “test facilitator containers”(maintained here) that implement python-based application clients and integrate other popular opensource chaos tools such as pumba, chaostoolkit & chaoskube.
For more details on chaos engineering using Litmus, read this article.
Litmus e2e test result visualization
One of the important enablers for the adoption of any given test (suite) into a CI framework is the result mechanism to determine success/failure. During the said period, Litmus moved over from extracting results from test container logs to storing this information in a Kubernetes static custom resource (“litmusresult”, which is updated by the test code at the beginning & end of test execution via a JSON merge patch operation), with the resource name dynamically generated based on user tags. This resource also holds other test metadata such as appType, testType, testStatus etc., apart from the actual verdict (result). CI jobs that implement/run the litmusbooks can be configured to derive job status from these CRs.
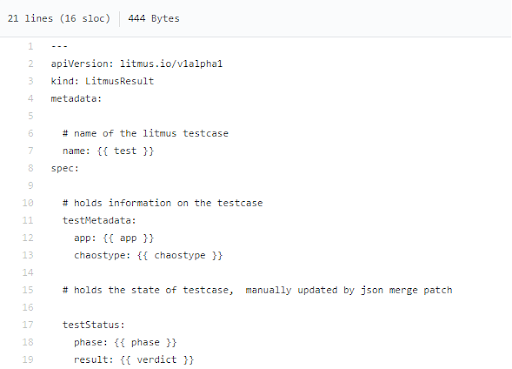
A jinja template describing the result CR structure
Other notable enhancements
The project also saw some other organic changes which have resulted in its faster adoption into CI systems & increased efficiency of the tests. They have been briefly described below:
Infra Setup Playbooks: Litmus now provides multiple ansible playbooks to aid quick and easy creation of Kubernetes clusters on different popular cloud platforms (GCP, AWS, GKE, AKS, EKS, Packet Cloud, On-premise vSphere VMs, OpenShift-on-AWS, OpenShift-on-vSphere) with minimal config inputs & also litmusbooks to setup the OpenEBS control plane on a K8s cluster.
Simplifying Litmus Setup: The litmus pre-requisites are taken care of by a simple interactive bash script that sets up the RBAC, CRDs & config file updates.
K8s-Specific Enhancements: These include small changes to make the litmusbooks more robust, such as:-
- Usage of generateName API in the litmus jobs to ensure repeated execution doesn’t cause failures
- Maximum Usage of labels & JSONPATH expressions in the kubectl commands used in the test code instead of bash utilities to guard against K8s cluster version & storage resource changes.
- Increased use of pod ENV variables (user-specific & downward API) to control test inputs in a K8s-native way rather than pass them in a test-code specific form (ansible extra-vars)
Increased Modularization of Test Code: Most of the test code is reused across the litmusbooks, due to which reusable tasks are managed as separate utils. These are further classified as common, chaos & app/storage lifecyclemodules, with well-defined interfaces.
Litmus CI: The Litmus (and test-tools) project now consists of its own Travis-based CI which builds respective runner images post-Ansible/Python lint/syntax check operations.
Optimized Test Images: The litmus runner (go, ansible) as well the test facilitators images have been optimized with respect to the number of layers, size and binary versions used.
Case Study: OpenEBS CI Powered By Litmus
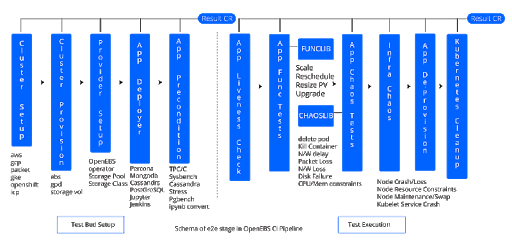
The Continuous Integration framework for the OpenEBS project, i.e., the various components such as Maya, Node-Disk-Manager (control plane), Jiva, cStor (data plane) is built using Gitlab, with the e2e tests executed via Litmusbooks & supported by an Elasticsearch-Fluentd-Kibana (EFK) based logging framework. Post the build phase (where the above-mentioned components are built and images pushed to respective repositories) multiple gitlab e2e pipelines based on the Kubernetes cluster version are triggered, each of which includes the following litmus-powered stages to:
- Create K8s cluster on the bare metal cloud platform Packet
- Deploy the OpenEBS control plane
- Deploy stateful applications
- Run the app & storage lifecycle ops
- Induce application, OpenEBS persistent storage & cluster infrastructure Chaos
- De-provision the applications & OpenEBS control plane
- Delete the K8s cluster resources
The gitlab runner scripts follow a defined pattern that involves the litmusbook preconditioning (user inputs), followed by litmusbook execution & monitoring of result custom resources, from which the success of gitlab job (and hence the stage) is derived.
openebs.ci provides a dashboard view of the build status for various commits to the openebs control plane and data plane projects, with detailed visibility into individual stage/job status & respective logs on Kibana. It also provides a real-time view of long-running production workloads using OpenEBS PVs which are maintained over multiple OpenEBS releases, with an option to induce random chaos on application/storage components & view the behavior. Litmus chaos modules are called internally to achieve this.
More details on the composition & functioning of this CI framework is available in this blog post.
Ongoing Efforts & Upcoming Features In Litmus
At this point, the Litmus contributions are mainly focused towards increasing the application & storage life cycle tests, more specifically, Day-2 operations of standard stateful applications, while continuing to increase the stability of the current tests.
Some of the near-term improvements & enhancements include:
- Publish documentation for the Litmus project
- Improvement of the Litmus Result CR to hold real-time status with increased metadata on failures, including the ability to capture application state.
- Development of additional infrastructure & application-specific chaos utils
Conclusion
The improvements made to the Litmus project have been possible only due to the amazing support from the community both in terms of feedback, as well as contributions. So, a huge thank you & looking forward to more of the same!!
This article was first published on Mar 25, 2019 on OpenEBS's Medium Account





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu