

My Kubernetes was just upgraded — what happened to my data?
What if I’m using ephemeral disks and thin provisioning to save money?

Developers and DevOps administrators like Kubernetes for how it has simplified the tasks in their daily lives. This has changed the way applications are designed, developed and managed. However, the churn of features and capabilities of Kubernetes continues to be high, and frequent upgrades to the platform are not uncommon. Kubernetes development releases are coming out on a quarterly basis, and production upgrades are seen about every 4 to 6 months. Also, if you are running on a Kubernetes service you typically are not 100% in control of when and how those upgrades are performed. The infrastructure software that runs on Kubernetes need to be cognitive of these upgrades so that application developers and Kubernetes administrators do not need to do any hand holding during such upgrades.
OpenEBS is an infrastructure software component for stateful applications running on Kubernetes that provides persistent storage volumes and associated data management capabilities. OpenEBS as cloud native or “container attached” storage has seen increased adoption since the release (last year) of the cStor storage engine, largely thanks to its support for enterprise-grade snapshots and clones, as well as improvements to cross availability zone awareness, etc. OpenEBS is designed in such a way that the administrators manage the storage operations in a Kubernetes native way using kubectl commands.
In this post, I would like to drive home three main points:
- Introduction to cStor pools and considerations for DevOps architects
- How cStor volumes and pools work during Kubernetes upgrades?
- Some dos and don’ts about cStor volumes and pools during Kubernetes upgrades
Introduction to cStor Pools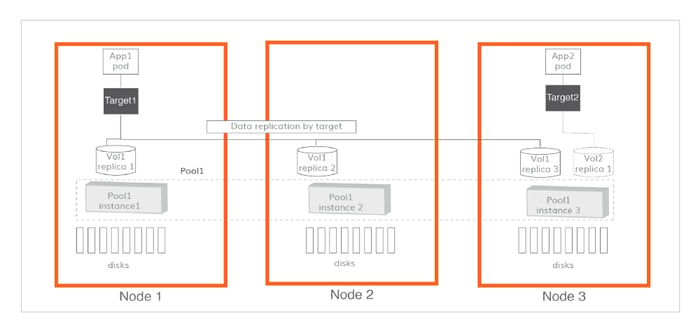
A cStor-Pool (Shown in the above figure as Pool1) is a set of pool instances on each participating node, where a pool instance is formed over a set of disks. The cStor target places data replicas on each of the pool instances, and synchronously replicates the volume data onto those replicas. The target manages the quorum logic and rebuilds the data among replicas when they become unavailable/available. For example, if a node disappears or is rescheduled, the workload will not notice as OpenEBS will continue serving the data.
Each cStor pool instance provides enterprise-grade data protection features such as data consistency, copy-on-write snapshots, RAID resiliency of disks, self-healing of data, and thin provisioning of data. The pools can be scaled within the node by adding more disks on demand or as the used capacity crosses a preset threshold such as 80%. This thin provisioning capability of cStor Pool instances typically leads to a savings of about 50% when pools are setup over cloud provider disks such as EBS, GPD, etc. and helps to limit operational overhead.
Node NOT_READY and node reboot is common in Kubernetes, and OpenEBS storage requires volume quorum.
At the beginning of this post, I talked about Kubernetes platform upgrades that are happening more frequently than one would imagine. A common phenomenon during upgrades is the reboot of the worker nodes. CPU and memory pressures are another commonly observed reason for the worker node to go into the “NOT_READY” state. In many cases a mass upgrade of a Kubernetes environment will cause all volume replicas hosted in the cStor pool instance to go offline, which will cause the cStor volumes to operate in an online state, but in degraded mode.
This scenario when more than one or all worker nodes are offline is when “Volume replica quorum” is especially important. A volume is considered to be online (or healthy) when the replicas are in quorum. In a three-replica setup, cStor target needs two volume replicas to be available and fully synced for the volume to be in quorum. cStor marks the volume as read-only when the replicas are not in quorum. This is needed to maintain data consistency and avoid potential data loss. Simultaneous or unmanaged node reboots can cause cStor volumes to lose quorum and cause temporary data unavailability. Again, this makes sense as the worker nodes themselves are out of commission.
Node Reboot Considerations
DevOps architects and Kubernetes administrators need to be watchful of this situation when Kubernetes upgrades are occurring. Instigating a planned node reboot that leads some cStor volumes to lose quorum may not be desired. This is a specific case where container attached storage like OpenEBS has a far smaller “blast radius” than typical external scale out storage. In the case of OpenEBS, you will likely lose availability to your storage for a particular workload when you simultaneously reboot more than one node and cause volume replicas to lose quorum. However, in the case of shared scale out external storage, such a scenario will result in data unavailability for all of your workloads at once.
Nonetheless, when performing a Kubernetes reboot the question that is often asked is ”what is the blast radius right now?” In other words, what volumes will lose quorum if a particular node is rebooted or lost?
While you can figure this out directly via kubectl, it is not trivial, especially as your environment scales. This is one of the reasons we have enabled the topology view of the storage resources for use in MayaOnline. We contributed those views upstream to the WeaveScope project as well.
With the MayaOnline topology view of cStor Pool custom resources, you can see the status of its hosted volume replicas. Before a node is considered for a planned reboot, it is easy to quickly inspect the pool instance to determine if rebooting the node will cause some volumes to lose quorum.
If a volume replica is rebuilding on a given node, it is advised that you wait until the rebuild is finished and volume replica data is fully synced.
Here are some example screenshots where one pool instance’s replicas are healthy and the other pool instance’s replicas are not.
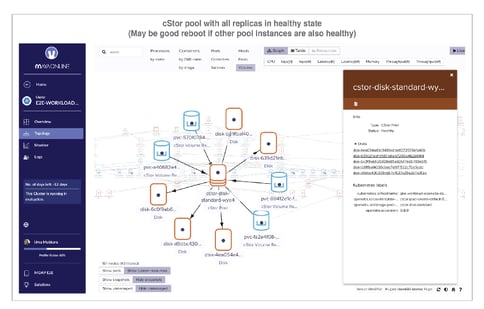
cStor pool with all replicas in healthy state
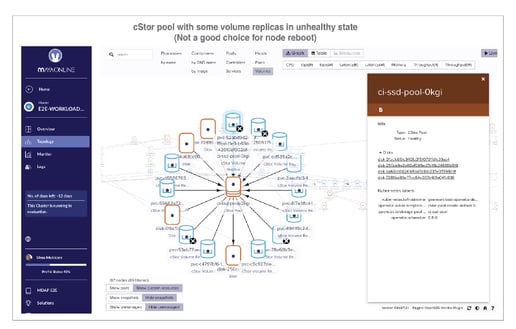
cStor pool with some volume replicas in unhealthy state
Ephemeral Disks Scenario
As hinted at above, node reboots are a distinct worry while using hosted Kubernetes services such as GKE, EKS and AKS. The default behaviour of these solutions upon reboot is that the nodes come back with completely new disks, and the total data written onto the original disks is lost. Perhaps not coincidentally, this behaviour serves as a powerful incentive to pay the cloud provider more money for their persistent storage options, even if doing so may increase your lock-in. On the other hand, if OpenEBS pools are hosted on these local disks, the reboot of a node causes the volume replicas on that pool instance to be completely rebuilt on your other volume replicas. So, your workload continues to easily access data and OpenEBS deals with the clean up behind the scenes; this pattern is fairly common on the OpenEBS community and benefits users by allowing them to use more performant and less-expensive SSDs. Please note that this auto rebuild functionality is currently supported for Jiva Pools but NOT for cStor Pools, which is one reason we have not made cStor the default storage engine for OpenEBS. The ephemeral disk/pool support for rebuilding in cStor is coming in 0.8.1 release. Until then, it is advised NOT to use cStor pools on ephemeral disks. And yes, 0.8.1 is almost available. If you have been following along in the community, for example OpenEBS.ci, you have seen test results increasingly turning green.
Conclusion:
The cStor pools feature in OpenEBS is helpful in managing the storage needs of cloud native applications in a Kubernetes native way. You may want to pay attention to planned node reboots to avoid temporary data unavailability during Kubernetes upgrades. Also, DO NOT use cStor pools on ephemeral disks until OpenEBS 0.8.1 release.
Thanks for reading!! If you are new to OpenEBS and need help getting started, engage in our wonderful slack community at slack.openebs.io. If you are already using OpenEBS, you may wish to connect your cluster to MayaOnline at mayaonline.io and get free visibility, analytics, and Elastic Search based logging for your persistent volumes, storage resources, and increasingly for stateful applications themselves.





Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu
Why OpenEBS 3.0 for Kubernetes and Storage?
Kiran Mova
Kiran Mova