

In this short post, I’d like to share an entrepreneur’s perspective on what achieving OpenEBS 1.0 means, first in terms of the evolution of use cases, and second in terms of progress on OpenEBS and MayaData itself.
Oxygen = New Use Cases such as Auto-Devops or ML
Here’s where the title of this blog post comes in to play— for a certain set of users and use cases OpenEBS is a no brainer.
I summarized a question from a large OpenEBS user recently on Twitter:
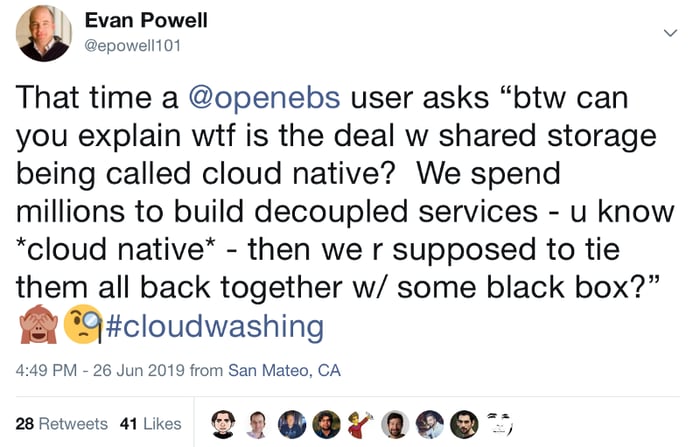
This user is a leader in an organization that runs Kubernetes and many other pieces of software to deliver capabilities to their internal users who build applications, machine learning models and so forth. So, they really do spend millions building distributed applications and really do not understand the thought process behind scale out storage.
This user’s users are themselves consuming OpenEBS, customizing it and deploying and managing it as needed. Since it is a Kubernetes native application, it fits right into their mental models and their tool chains.
Conversely, they are not talking to a storage engineering team. As a matter of fact, most of our users are led by Kubernetes operators and administrators and so called “devops” teams — not by a storage engineering silo. That’s not to say that these teams are not interested; when they hear about us they often want to know how we complement their existing storage infrastructure rather than replace it. It could be that engineers from these teams become stateful workload practice leads within enterprises, a pattern we are starting to see.
One common usage pattern we see is impermanent persistent storage. This is a trend we first saw a couple of years ago, and it definitely took me a second to wrap my head around since my background says that data is sacrosanct. Then users were telling us that they intended to use OpenEBS because it could be blown away easily? Hmm…
It turns out that there are a number of use cases for essentially scratch space, such as the up to date version of training data, that needs to be made easily available to pipelines then deleted after 24-36 hours. Of course, clones are a great use case for this and OpenEBS itself can be treated in a disposable manner.
Another common pattern is to deploy in a matter of seconds what used to take weeks, especially Kafka, where OpenEBS is used when the data is flushed periodically from memory to disk. This is similar to the uptake of OpenEBS behind Redis. This pattern of course owes everything to Kubernetes and containers themselves. Once again, I tweeted about this one; there are some large German users that gave us a friendly hard time about not knowing that they were users when we met them at KubeCon Barcelona.o
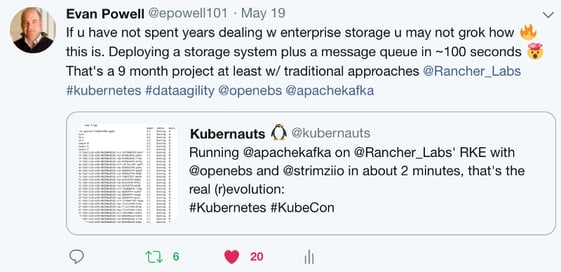
Now, the question sometimes is “what do you mean by OpenEBS?” After all, OpenEBS embraces the pluggability that is inherent to being written as microservices. When looking at OpenEBS, it is important to dig below and look at which storage engine is being used. In the case of Kafka, we are increasingly seeing the OpenEBS LocalPV storage engine — with the help of NDM included — as a common approach.
We continue to step forward each day on implementing a new storage engine, and some users are taking a look at Rust now. If you’re interested in this, please get in touch if you’d like to see 0% overhead OpenEBS at work, albeit at an alpha level. You will see a blog post coming soon from our CTO updating these efforts.
What’s new in OpenEBS 1.0, and so what?
The discussion above covers some of the insights related to users and their use cases that power the enthusiasm of the MayaData/OpenEBS team that is leading to more and more happy users.
Here, I want to avoid a rewrite and repost of Kiran’s excellent post that outlines what’s new in 1.0:
Read the article: OpenEBS announces the availability of version 1.0
However, I do want to stress just a few points:
- We named the release OpenEBS 1.0 in large part because we have had to acknowledge that there are many OpenEBS production users now….
- With that in mind, we wanted to push out a release that we could stand behind, including keeping our APIs consistent. We use Kubernetes as our API set, which helps to a large extent, although it also means some things will change because Kubernetes is changing.
- Just because OpenEBS is at 1.0 does not mean that magically all the code related to OpenEBS is at a generally available level of quality. Instead, we are picking up the approach of Kubernetes and many other projects by defining levels of mature per key components. Remember that unlike traditional storage systems, OpenEBS is not a monolith, so different components can mature at different times depending on a variety of factors. With this, we are working hard to remain transparent.
Regarding commercialization, we get asked more and more now about how we are growing this business.
Essentially, we write software to help a certain type of user succeed in delivering “data agility” to their organizations. That’s it! I understand that is very broad, but it remains our true north. It serves as part of a vision we share of what Kubernetes and containerization can enable. For us, OpenEBS is a means to an end, in other words, and we will do whatever it takes to help our users succeed at the jobs they do.
So, we’ve written other software in addition to OpenEBS to enable data agility — and all of that software plus our services together we actively support for our customers.
That thinking has led to offers such as the following:
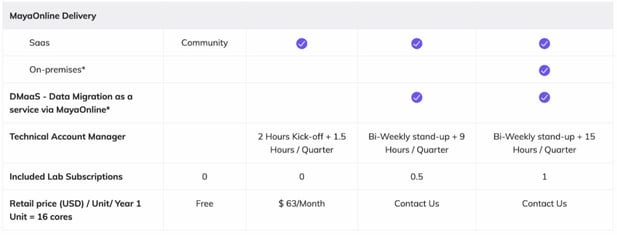
We are tied to the success of our users. The word of mouth based on our customer’s experiences must continue to build — we have come a long, long way since we open-sourced OpenEBS back in January 2017. To be successful, our users have to actually achieve data agility: demonstrable acceleration for themselves and their developers thanks to running stateful workloads on Kubernetes. And as they do, we are seeing a level of loyalty and, yes, commercial adoption, that is extremely promising.
Conclusion
Some years ago, I chatted with one of the early engineers on Kubernetes about storage for and on Kubernetes, and his comment was: “Meh, storage is just something you get as a service. At Google we….” These days, his perspective has evolved. Whereas Google has thrown hundreds of millions of dollars towards engineering talent, atomic clocks, and more at making storage essentially an infinitely scalable utility to their users of Borg, storage remains a largely unsolved problem for the rest of us.
Kubernetes reveals so many problems with the approaches of existing storage, from the difficulty traditional storage has dealing with the dynamism of containers to the extremely high user experience expectations set by cloud services that storage that takes hours or even weeks to provision cannot match, to the archaic underlying architectures. These issues that threaten to hold back the use of Kubernetes for stateful workloads, but can themselves be addressed by embracing Kubernetes itself as the substrate.
Today the approach of container attached storage has been broadly accepted. Now the broader technology industry is coming to appreciate the data agility that users are achieving thanks to this approach. As they are waking up to the opportunities, we and the broader cloud native community are accelerating and evolving in ways that remain beyond the ken of non-participants. This community cannot be easily replicated — the trust we’ve built in each other over many thousands of hours is a human thing that no amount of big company money and marketing can easily overshadow.
People FTW! Please do stay in touch, keep the feedback coming, and feel free to reach out if you’d like to join a company devoutly committed to helping enterprises leap ahead in their use of data in containerized and cloud native environments.
This article was first published on Jul 2nd, 2018 on MayaData's Medium Account





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu