

NuoDB is a container-native adaptive-scale distributed SQL database designed with distributed application deployment challenges in mind. The NuoDB database is ANSI SQL compliant and is seen in a new category called “NewSQL.” If you are not familiar, the difference provided by NewSQL solutions is explained in a 2016 research paper here.
Some other solutions in this category include Amazon Aurora, Google Spanner, TiDB, CockroachDB, Altibase, Apache Ignite, GridGain, Clustrix, VoltDB, MemSQL, NuoDB, HarperDB, and Trafodion.
NuoDB has a distributed object architecture that operates in the cloud, meaning that in order to scale-out the database, a new node can be added and the database runs faster. That’s why it represents the perfect example of a new-gen cloud-native architecture and a solution for the containerized applications running on Kubernetes.
.png?width=416&name=Untitled%20design%20(48).png)
NuoDB provides all of the properties of ACID-compliant transactions and standard relational SQL language support. It was designed from the start as a distributed system that scales the way a cloud-native service is expected to scale, providing continuous availability (CA) and resiliency with no single points of failure. Different from traditional shared-disk or shared-nothing architectures, NuoDB presents a new kind of peer-to-peer, on-demand independence that yields CA, low-latency, and a deployment model that is easy to manage. The chart below is a simple comparison and decision chart from the NuoDB website.
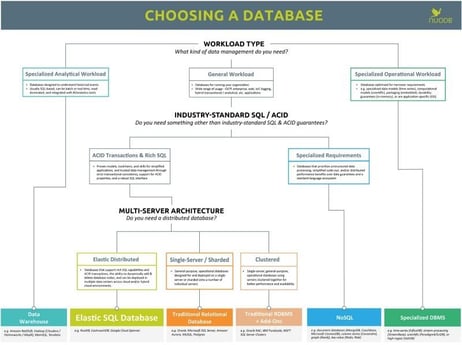
Quick Notes on the NuoDB Architecture
NewSQL systems are designed to operate in a distributed cluster of shared-nothing nodes, in which each node owns a subset of the data.
Although it appears as a single, logical SQL database to the application, it has two layers that retain strict transactional consistency. It can even be deployed across multiple availability zones (even on different clouds!), and is optimized for in-memory speeds, continuous availability, and adaptive scale-out that adjusts to the application needs.
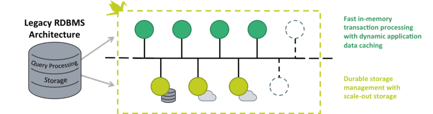
NuoDB Architecture: TEs (Top), SMs (Bottom)
Transaction Engines (TEs): The TE layer is used for (ACID) SQL and caching, made up of in-memory process nodes that coordinate with each other and the SM layer.
Storage Managers (SMs): The SM layer is used for storage and consists of process nodes that have both in-memory and on-disk storage components. SMs provide on-disk data durability guarantees, and multiple SMs can be used to increase data redundancy.
Both TE and SM node types can be easily added or removed to align with user needs.
Why Use OpenEBS for NuoDB?
Running applications on traditional virtualized systems or bare metal are different from running them on Kubernetes. NuoDB is a horizontally scalable database that offers scale up in performance on the fly from the underlying storage system. Container Attached Storage (CAS) solutions like OpenEBS are a perfect choice to run NuoDB on Kubernetes, both on-premise (such as OpenShift) and through the cloud because of the following benefits:
- Local disks or cloud disks are managed seamlessly and in the same way by OpenEBS.
- Persistent volumes (PVs) can be made available to NuoDB from a shared pool of disks. You can run multiple stateful databases out of the same physical disks present on the Kubernetes worker nodes, simplifying operations, increasing density, and decreasing costs.
- Large size PVs can be provisioned for NuoDB. OpenEBS supports volumes up to petabytes in size.
- You can increase the size of PVs as needed. With OpenEBS it is possible to start with small capacities and add disks as needed on the fly. Sometimes NuoDB instances are scaled up because of the capacity on the nodes. With OpenEBS persistent volumes, capacity can be thin provisioned, and disks can be added to OpenEBS on the fly without disruption.
- NuoDB backups can be taken at the storage level and stored in S3. Using the backup/restore capabilities of OpenEBS, NuoDB instances can be moved across clouds or Kubernetes clusters seamlessly. There is no vendor lock-in problem when OpenEBS is used as the underlying storage.
- Last, but not least — OpenEBS is 100% open source and in userspace.
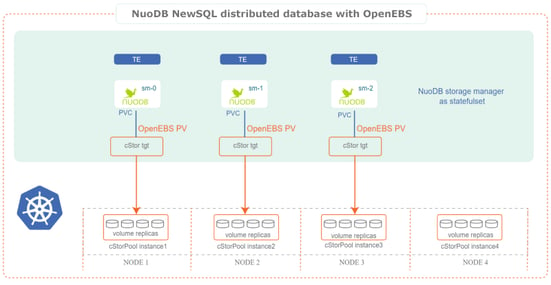
Let’s deploy our first NuoDB instance on our existing small, three-node OpenShift K8s cluster with OpenEBS.
Note: NuoDB Community Edition supports only 1 SM and 3 TE configurations. To increase the number of SMs and TEs, the Enterprise edition should be used instead.
Requirements
Software
- RHEL (master and node servers) 7.0 and above
- OpenShift 3.9 or above
- kubectl
- OpenEBS v0.8.1 or above
- NuoDB 3.4 Enterprise or Community Edition
Hardware
- 3 nodes (bare metal or cloud)
- 16 vCPUs
- 32GB RAM
How to Install NuoDB
If you don’t have an OpenShift cluster, you can follow my previous blog here to get both OpenShift and cloud-native storage OpenEBS up and running on Kubernetes.
The NuoDB CE OpenShift template is available with two options: using ephemeral storage or using persistent storage. With ephemeral storage, if the Admin Service pod or Storage Manager (SM) pod are stopped or deleted, the database will be removed with the pod as expected. That is where OpenEBS comes into play. When running NuoDB on OpenEBS, even if the pod is stopped or deleted, the DB state will be preserved and made available again on the automatic pod restart.
Disable Transparent Huge Pages (THP)
Additionally, on your OpenShift nodes run the command below to ensure Transparent Huge Pages (THP) is disabled. NuoDB will not run on a Linux machine with THP enabled.
| $ cat /sys/kernel/mm/transparent_hugepage/enabled |
If this returns |always| madvise never, THP is enabled and you must disable it by adding the transparent_hugepage=never kernel parameter option to the grub2 configuration file. Append or change the “transparent_hugepage=never” kernel parameter on the GRUB_CMDLINE_LINUX option in the /etc/default/grub file similar to the below:
| $ vi /etc/default/grub GRUB_TIMEOUT=5 GRUB_DEFAULT=saved GRUB_DISABLE_SUBMENU=true GRUB_TERMINAL_OUTPUT=”console” GRUB_CMDLINE_LINUX=”nomodeset crashkernel=auto rd.lvm.lv=vg_os/lv_root rd.lvm.lv=vg_os/lv_swap rhgb quiet transparent_hugepage=never” GRUB_DISABLE_RECOVERY=”true” |
Create a Project
Create a project named “nuodb” by clicking the OpenShift “Create Project” button. If desired, you can also add a template display name of “NuoDB on OpenEBS.”
Create an Image Pull Secret
If you want to use the official Red Hat Container Registry, then you need to create an image pull secret and import the image from the Red Hat Container Catalog (RHCC).
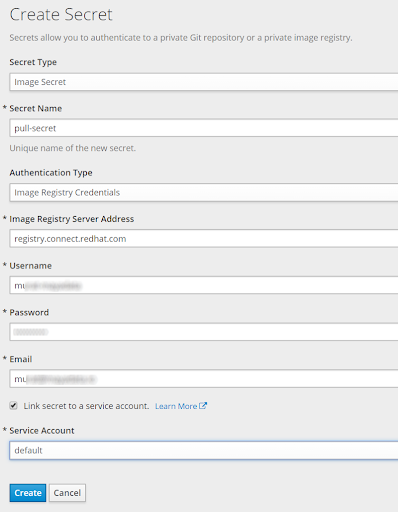
To create an image, use pull secret which allows the template to pull the NuoDB CE container image from the RHCC. From the OpenShift left bar menu, click “Resources,” then “Secrets,” and “Create Secret.”
Enter these values:
| Secret Type = Image Secret Secret Name = pull-secret Authentication Type = Image RegistryCredentials Image Registry Server Address = registry.connect.redhat.com Username = (your RH login)Password = (your RH password) Email = (your email address) Link secret to a service account = (check this box Service Account = Default |
This should look similar to the screenshot below:
You can find the RHCC instructions here if needed.
As an alternative, you can use the Docker registry images (not suggested for production).
Label the Nodes
Label at least three servers using the oc label command:
| $ oc label node nuodb.com/zone=nuodb |
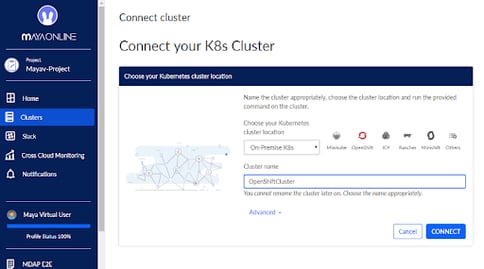
Connect to MayaOnline
Connecting the Kubernetes cluster to MayaOnline provides enhanced visibility of storage resources. MayaOnline has various support options for enterprise customers.
- Login to mayaonline.io.
- Go to “Clusters” and click on “Connect a new cluster.”
- Select “On-Premises K8s” and click on the OpenShift icon.
- Give your cluster a name.
- Click on the “Connect” button.
- Copy the command and run it on your OpenShift cluster.
Configure cStor Pool
After OpenEBS is installed, cStor pool must be configured. If cStor Pool is not already configured in your OpenEBS cluster, this can be done following the instructions here. A sample YAML named openebs-config.yaml used for configuring cStor Pool is provided in the Configuration details below. During cStor Pool creation, make sure that the maxPools parameter is set to >=3.
| #Use the following YAMLs to create a cStor Storage Pool. # and associated storage class. apiVersion: openebs.io/v1alpha1 kind: StoragePoolClaim metadata: name: cstor-disk spec: name: cstor-disk type: disk poolSpec: poolType: striped # NOTE - Appropriate disks need to be fetched using `kubectl get disks` # # `Disk` is a custom resource supported by OpenEBS with `node-disk-manager` # as the disk operator # Replace the following with actual disk CRs from your cluster `kubectl get disks` # Uncomment the below lines after updating the actual disk names. disks: diskList: # Replace the following with actual disk CRs from your cluster from `kubectl get disks` # - disk-184d99015253054c48c4aa3f17d137b1 # - disk-2f6bced7ba9b2be230ca5138fd0b07f1 # - disk-806d3e77dd2e38f188fdaf9c46020bdc # - disk-8b6fb58d0c4e0ff3ed74a5183556424d # - disk-bad1863742ce905e67978d082a721d61 # - disk-d172a48ad8b0fb536b9984609b7ee653 --- |
Create the Storage Class
You must configure a StorageClass to provision a cStor volume on a given cStor pool. StorageClass is the interface through which most of the OpenEBS storage policies are defined. I will be using a StorageClass to consume the cStor Pool that is created using external disks attached on the Nodes. Since NuoDB is a statefulset application, it requires only a single storage replica. Therefore, the cStor volume replicaCount is =1. A sample YAML named openebs-nuodb.yaml used to consume cStor pool with cStoveVolume Replica count as 1 is provided in the configuration details below.
| apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: openebs-nuodb annotations: openebs.io/cas-type: cstor cas.openebs.io/config: | - name: StoragePoolClaim value: "cstor-disk" - name: ReplicaCount value: "1" provisioner: openebs.io/provisioner-iscsi reclaimPolicy: Delete --- |
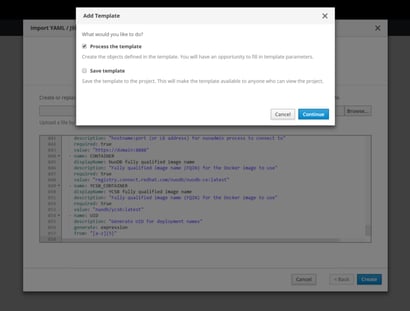
Import the NuoDB CE Template
Import the NuoDB CE template ce-template-persistent.yaml into OpenShift by navigating to the “Overview” Tab, clicking “Import YAML/JSON,” and running the import.
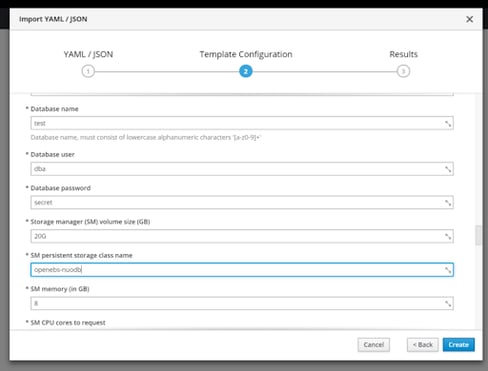
Follow the installation prompts and change the “SM persistent storage class name” and “Admin persistent storage class name” to openebs-nuodb.
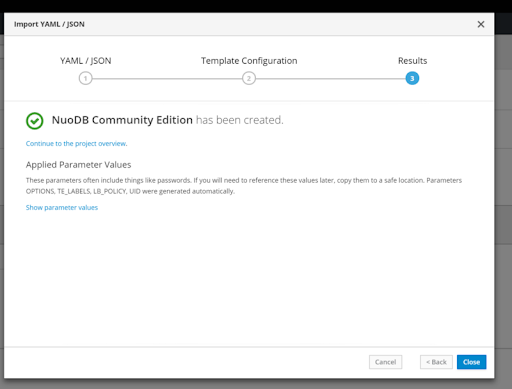
Click “Create,” and shortly after you will see one pod each for the Administrative Service (Admin), Storage Manager (SM), Transaction Engine (TE) and Insights processes started under the nuodb namespace with volumes provided by OpenEBS.
What’s Next?
If you would like to read more about the design considerations, running test loads with YCSB, monitoring Insights or volume metrics through MayaOnline, and inserting some chaos engineering with Litmus, you can find a detailed solution doc on MayaData’s website under the Resources section here.

Next, I plan to cover some 2nd-day operations for NuoDB using OpenEBS snapshots, clones, backup, recovery using MayaOnline functionalities such as topology and access logs. If you’d like to see or discuss anything not covered here, feel free to comment on my blog or contact me via Twitter @muratkarslioglu.
Originally published at containerized.me on March 14, 2019.





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu