

Up time, high availability, disaster recovery. Anyone that has been working in development or IT operations roles knows these terms. Maintaining these things is always touted as the most critical of critical tasks. Even with that in mind, we often slack in these areas. We don’t test our backups or run our applications with high availability in mind. One of the main factors that lead to these less than ideal deployments is that implementing a good high availability story, or testing our backups, adds time and/or complexity to our already busy day. All that being said, let’s take a look at a dead simple solution for one of those applications that many of us run: Jira.
The standard answer to making Jira highly available and provide a good disaster recovery story is to use Jira Data Center and follow this guide:
Jira Data Center Guide
That guide shows you how to cluster multiple instances of the application behind a load balancer, then use a shared file system and a shared database underneath. This blog is not about the application layer or even the database (though we do have some fantastic guides for deploying databases using OpenEBS in our documentation). This is going to focus on a simple way to create a replicated storage layer specifically for the file system. Jira stores information on disks such as issue attachments, import/export files, and logos. These are all important in keeping Jira working correctly.
Deploying Jira on Kubernetes using OpenEBS is as simple as installing OpenEBS on Kubernetes, define a storage pool, define a storage class, define your persistent volume claim, and deploy the Jira container. That’s it…and if you are already using OpenEBS it is even simpler. Now, as for the specifics of how to do those things, see this guide:
Once you have Jira deployed on your cluster, the easiest way to see your storage resources is through MayaOnline (hopefully you connected to MayaOnline while following the guide, if not the instructions are here. Here is an example of a Jira deployment as visualized through the MayaOnline topology pane:
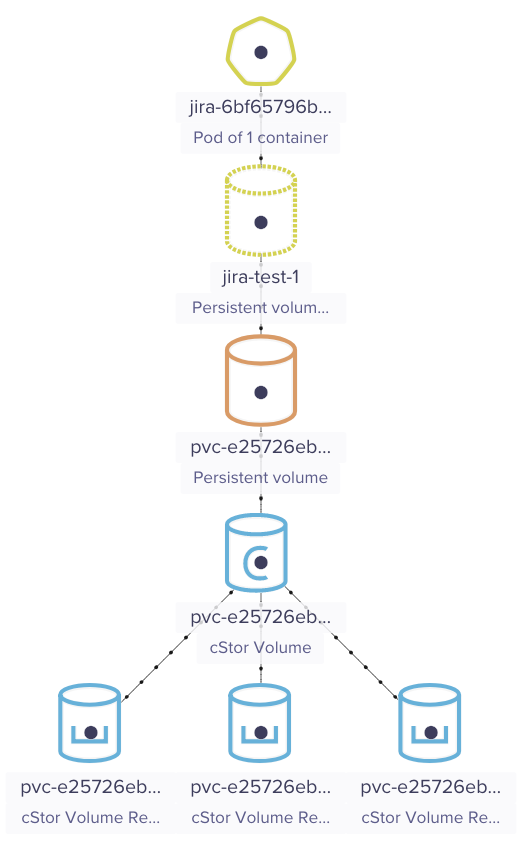 MayaOnline Topology
MayaOnline TopologyBy leveraging the power of replicas within OpenEBS we have quickly added fault tolerance to the storage attached to our Jira container. It was as simple as defining a replica count in the storage class. Since the replicas are spread across the cluster we no longer have to worry about the storage being a single point of failure. If one disk goes down, the controller will automatically route to one of the replicas with no intervention necessary.
As you can see OpenEBS has greatly simplified the process of making Jira more resilient in a containerized world. The ease of use of container attached storage makes tasks like these much simpler. It allows us to spend more time working on improving our applications or infrastructure, and less time worrying about its resiliency.
This article was first published on Apr 22, 2019 on OpenEBS's Medium Account





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu