


At MayaData, we use Litmus to practice chaos engineering for validating each commit of OpenEBS against a few Prometheus releases. We also extend the same testing to conduct real-world chaos engineering on our production clusters where Prometheus is being used for monitoring our GitLab production system.
In this article, I will describe how OpenEBS is used as persistent storage for Prometheus and discuss how we verify the stability of such a deployment. Before diving into the details, let’s talk about what Litmus is and why OpenEBS is used as TSDB for Prometheus.
What is Litmus?
LITMUS — An open source framework for chaos engineering based qualification of Kubernetes environments running stateful applications. For a good introduction to Litmus and how to get started with Litmus, see the Litmus docs (https://docs.litmuschaos.io/ )
Litmus books are broadly categorized into four types:
- K8s infrastructure books
- Stateful applications deployment books
- Stateful applications chaos books
- Deployers for providers such as OpenEBS.
Next, I will focus on what Litmus deployers and chaos jobs are available to help build a CI/CD pipeline to harden Prometheus applications on OpenEBS and Kubernetes.
Introduction to OpenEBS
OpenEBS is the leading open source Container Attached Storage software and has become a common part of many Kubernetes deployments since its first release in early 2017. OpenEBS has been accepted into the Cloud Native Computing Foundation as a Cloud Native Sandbox Project and is featured here: CNCF Sandbox Projects. You can read more about OpenEBS in the OpenEBS Docs
 OpenEBS architecture
OpenEBS architectureBecause OpenEBS is a pluggable, containerized architecture, it can easily use different storage engines that write data to a disk or underlying cloud volumes; the two primary storage engines are Jiva and cStor. With WAL support, the write performance of Prometheus increases significantly.
Why use OpenEBS Volume as Prometheus TSDB?
One of the challenges with Prometheus is determining how to set up and manage storage. The default behavior of Prometheus is to simply have each node store data locally. However, this of course exposes the user to potential data loss if the local node goes down.
Here are some issues with Prometheus storage:
- When using local storage, Prometheus stores time series in memory and on a local disk. Therefore, metrics are not persisted if its POD restarts.
- If we configure persistent volumeas local and that pod is rescheduled to any other Node of the cluster, it loses all previous data that has persisted on the previous node.
- When using Remote storage, read and write operations are quite slow.
By using OpenEBS volumes related to the local storage for Prometheus on Kubernetes clusters, each of the above drawbacks is directly addressed. OpenEBS volumes are replicated synchronously and data is protected and always made available against either a node outage or a disk outage.
Using OpenEBS as storage for Prometheus on Kubernetes clusters is an easy and viable solution for production-grade deployments.
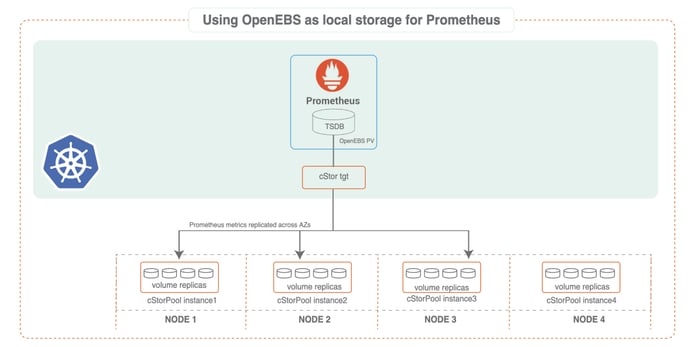
Elements of a Prometheus CI/CD pipeline
We have successfully implemented GitLab stages for Prometheus and system validation. Full implementation of such pipeline is shown below as an example.
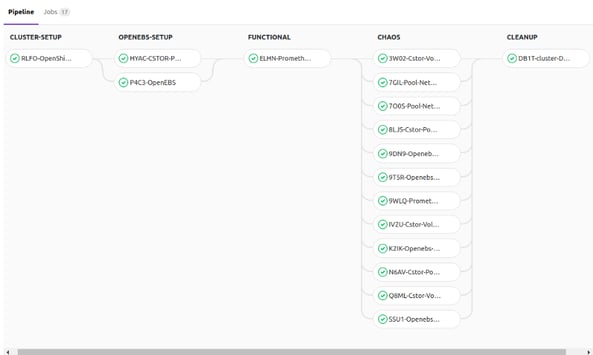
The figure above is a sample GitLab pipeline that is running OpenShift EE 3.10 and Prometheus:v2.3.0 with Litmus. Here are the following stages:
- CLUSTER-Setup
- OpenEBS-Setup
- FUNCTIONAL
- CHAOS
- CLEANUP
Litmus provides almost-ready books for every stage except FUNCTIONAL, where the Developers and DevOps admins should be spending time creating the tests for their applications. The rest of the stages are generic enough that Litmus can easily do the job for you with the tuning of the parameters.
Reference Implementation:
The Prometheus GitLab pipeline implementation for OpenShift EE platform and corresponding Litmus books are all available in the OpenEBS GitHub repository:
Example Litmus Jobs for Prometheus on OpenEBS
App Deployers
Litmus job for deploying Prometheus using OpenEBS volumes for storing metrics:
Loadgen
Litmus job for load generation in Prometheus using Avalanche load generator:
Liveness
Litmus job to check the liveness of Prometheus app:
Chaos Jobs — Storage
Litmus job for inducing OpenEBS cStor pool pod to delete and verify the application availability:
Summary:
Building CI/CD pipelines for stateful applications like Prometheus on OpenEBS and Kubernetes/OpenShift is quick and easy. Most of the pipeline is readily available through Litmus. Users can apply the readily available Litmus books to build Chaos Engineering into their GitLab pipelines with ease.
This article was first published on May 21, 2018 on MayaData's Medium Account.





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu