

Steps to prevent cascading failures.
This post is intended to share observations gathered from a couple of decades worth of experience in helping enterprises build resilient systems and presented based on feedback from Kubernetes and StackStorm users over the past 4-5 years. As such, mileage may vary; I myself am still learning and offer this as a way for us all to learn together, so feedback is not just welcome, it is absolutely requested.Here is what I have seen too often, and is the basis of all the principles I share below. For all of us, as we build these systems of systems with more dependencies and dynamic relationships than any one human could possible fully understand, we want to make sure that we don’t generate opaque cascading failures.
In short, Don’t Injure Yourself (DIY)

For starters, don’t make your automation so intelligent that it knows how to kill nodes that are not responding without also understanding why that node might be moving slowly. As I have seen before, it could be that your load peaked the day after Thanksgiving, and by pulling the slow nodes out of the queue you are simply shortening the time before all other nodes become overwhelmed. These are the things brownouts are made of.
So, how can you avoid being thrown off the end of your own automation treadmill?
Here are a few hard-learned principles that I draw upon:
- Shift down — tackle failure as close as possible to the failure source to limit the risk of injuring yourself with cascading failures.
- Build every layer — and every system, so that it is built to fail.
- Build every layer — do not think you have DR when you have HA; and don’t think you have HA just because you have one workload that spans several clusters.
- Infrastructure as code – related to #3. Always; no black boxes. The desired state is in the repo. Yes, the control loop at the center of Kubernetes will make simple decisions to trade off workloads and behaviors to the best of its ability. Grok that, and insist on everything by deploying this approach.
- Simplicity. Yes, this is the UNIX philosophy of do one thing and do it well. No, a human cannot grok the entire system in many cases , but they must be able to grok the behavior of each subsection.
Let’s look at a few FAILURE examples. Below, I have included the entire Google slide deck that contains the discussed images for you to use and review. They are even animated in this slide deck!
I’ll be working off this example of a Kubernetes environment. As you can see, we have two Kubernetes clusters, each of which have many pods. I show Pod A, B and C for each, but in reality, there would be many additional pods as well. We have some stateful workloads running across those clusters.
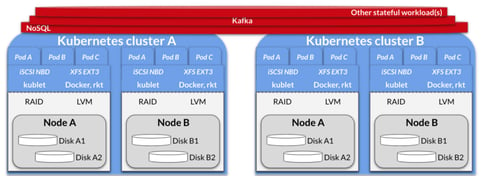
Now let’s assume you have similar environments on cloud A and data center B or similar. The idea is that we have multiple locations for similar multi-cluster Kubernetes.
It may be useful for these examples to keep in mind that the fundamental architecture of a Container Attached Storage solution like OpenEBS is to run within the clusters to provide storage to stateful workloads. Essentially, this is the piece that gives each workload its own file or block access (or s3 if you run Minio on top, for example) irrespective of the underlying cloud volumes, existing storage, disks or other hardware such as NVMe.
https://www.cncf.io/blog/2018/04/19/container-attached-storage-a-primer/

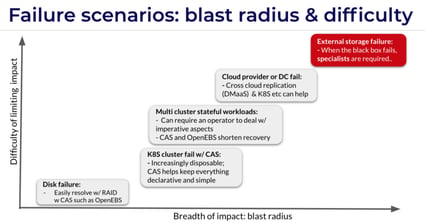
Failure Condition #1: Cloud Volume or Disk Dies
Starting at the bottom of that stack, what should you do when a disk dies or a cloud volume becomes unresponsive? This is shown in by the red “X” in the image below.
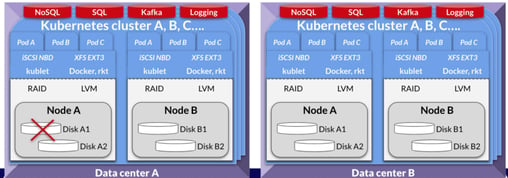
If you have NoSQL or some sort of scale-out SQL running, then presumably you do not need to do anything, right? I mean, you can just degrade the pod and even the cluster and it should still work, correct? Technically, that is correct, but what is the cost? What happens to your system when, for example, a ring is being rebuilt or the cache is being repopulated? How much cross-node traffic is needed?
Principle #1 is an adaption of shift left from DevOps — in this case, it is shift down. You fix the dying disk or the loss of the value at that level through a simple and easy to grok RAID. The RAID should be as simple as mirroring, so that you do not waste time rebuilding or resilvering disks. In other words, don’t use Raid 5 or 6 just to save space at the cost of complexity and longer rebuild times. This could easily degrade the POD and Cluster. You should absolutely build intelligence at the bottom of the stack to ensure you survive disk failure without creating a risk of cascading failure as a result of taxing the higher levels of the stack.
Failure Condition #2: A Lost POD that is Running a Stateful Workload
This is where HA is put to use. However, this is not the same as disaster recovery, which involves recovering an entire environment from the loss of a data center. Rather HA is intended to keep the application functioning properly with no downtime, and it should respond seamlessly to small hiccups such as pod outages.
Kubernetes, of course, helps here by ensuring that multiple replicas of the actual workload can be kept alive. However, Kubernetes is not necessarily proactive when it comes to keeping stateful workloads alive. This is where a properly deployed DB layer will be useful and provide a layer of HA for the application. This guarantees that reads and writes of state for the application are never interrupted. Typically, this is done by implementing a quick failover (quicker than Kubernetes might notice, without help) to a destination for writes and multiple read replicas. However, architectures amongst the dozens of DBs vary. You can read more about this subject in a recent blog I wrote on running your own DBaaS that also touches on picking the right DB from the start:
The TL;DR from above includes consideration about which operators you want to use for your DBs. Of course, DBs and other stateful workloads need some imperative flow to recover from failures such as Do X (log failure), Do Y (direct writes and/or reads to the active replicas), Do Z (clean up the old node), etc.
Having configured your DB in a HA manner with the help of an operator, you are now faced with a decision. But then, do you want a storage layer replica as well?
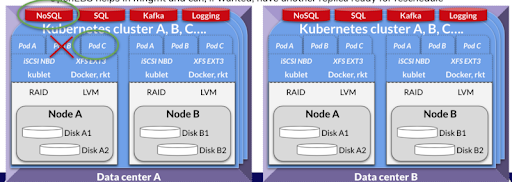
Typically, the answer we see amongst our users is no. However, if you have a container attached storage solution like OpenEBS, you can decide on a per-workload basis. Perhaps you have one workload in which you are concerned that the DB itself will crash, so you want to be able to immediately reschedule and redeploy the DB onto a new node with the help of Kubernetes. This way you can have the data on the node even if the DB had not been running previously on that node. Maybe you want the write ahead log to be double resilient and you want the actual data files, but you decide it is not worth the trade off, or vice-versa. I’m not sure what to call this double redundancy — maybe we can call it HA².
There are definite trade-offs in this case as you would now be asking the storage to do a write and/or synchronous replication to multiple locations before acknowledging the write. While this will become less expensive when NVMe is used as a protocol and a new class of persistent memory becomes prevalent, today it can drop your write IOPS by 30–40% depending on configurations of the DB and the storage itself among other factors. Please note that this is the kind of tuning we do with the help of partners like Datastax, NuoDB, and a number of local and global systems integrators. You can always ask around in the OpenEBS community and you will almost certainly find helpers. You also might find MayaOnline to be useful in seeing the trade-offs in real life; perhaps the help of traffic generated by Litmus (more on that below).
Failure Condition #3: What Happened to my DB?
Continuing on the prior example, if you want to be prepared for a scenario in which the DB itself disappears, then you really should have storage or some other method for keeping a copy of the state of the database. As mentioned, if you do synchronous replication or simply have the writes written in multiple places through solutions like OpenEBS, then you get every write (consistency!) but at the cost of latency and additional loading on your network. On the other hand, if your storage solution can quickly take incremental snapshots of your storage and move those snapshots somewhere else then you can commit the writes quickly, then take/move the snapshots of that data. This eliminates the latency tax, but at the cost of your recovery point objective. So, you should be prepared to lose writes with this scenario.

By the way, storage is not the only way to add a layer of resilience to your application in cases of DB failure. We often see cases in which the DB is somewhat isolated from the actual traffic by a cache layer (hello Redis!). This cache layer can take all the writes for a period of time. In this case, having a DB deployed onto a new node with all but the most recent X writes will work just fine.
Failure Condition #4: Disaster Strikes!
In this scenario, a hurricane shows up and floods your data center. One approach is to have every single byte written in a data center or cloud asynchronously replicated to a second cloud. Unfortunately this causes suboptimal performance in Cloud A and will not guarantee that Cloud B will function properly when the load switches over.

So what should you do? A common pattern we have noticed involves letting the individual teams responsible for each application determine what solution best fits their project. They must have an answer if they have an SLA that leads them towards true DR. However, in the end they can decide what they want to do. It could be that they are willing to work in a degraded mode for a period of time.
Here is where the ability to snapshot and move entire applications may be a good solution. We have seen OpenEBS itself being used in this way quite often with the help of Heptio’s Velero (Formerly Ark) plug-in. We are now adding capabilities to make the management of the entire workflow simpler so that each team has the necessary control to decide their approach while the broader organization can see their approaches in aggregate. This is the so-called DMaaS subproject, due for initial release in OpenEBS 0.9.
Another pattern that I heard about occurred at Netflix many years ago, and is now known as chaos engineering. At MayaData, we employ a flavor of chaos engineering in our CI/CD end to end pipelines . For instance, we publish every commit to the OpenEBS master on OpenEBS.ci and subject them to chaos engineering under a variety of stateful workloads and across a number of environments from OpenShift to managed Kubernetes services like AKS. We have open-sourced all of this, enabling tooling for stateful workloads called Litmus (https://openebs.io/litmus)
The point here is to apply chaos engineering to your HA and DR approaches so that you can actually see them work and fail. Everything fails occasionally , including the systems that are intended to help you survive failure. What’s important is understanding the blast radius and determining how hard or easy it is to continue operation and recover with time?
Whichever method you use, keep in mind that the granularity of control that containers, microservices and Kubernetes extended via container attached storage enables is of great benefit to you. It allows responsible teams to fully grok their component in this aspect of service resilience and minimizes the blast radius ideally down to the per team scope of control: typically the microservice itself. You can think of this approach as building in fire breaks to stop cascading failures.
I hope this blog is of use to those of you wrestling with ways to ensure resilience while running real (stateful) workloads on Kubernetes. The good news is that OpenEBS and other open source projects in and around Kubernetes are quickly accumulating thousands or tens of thousands of production hours and there are many experts that frequent such channels and are often ready and willing to help.
Some of this experience informs our docs in the OpenEBS community, including common patterns for workloads such as Minio, MySql, Cassandra, Elastic and many others: https://docs.openebs.io/docs/next/mysql.html
As mentioned, you can also see these and other workloads on display as each commit to master for OpenEBS is tested against them. You can even choose to inject chaos into the testing of these workloads on OpenEBS as it is developed and matured: https://openebs.ci/workload-dashboard
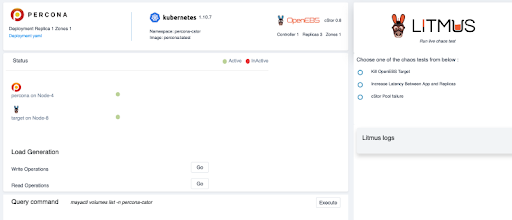
For example, here is the Percona dashboard that shows the ability to inject failures and to generate loads. And yes, that is live. Feel free to cause chaos on our dime!
Last but not least, I’ve tried to pull this blog together into a single picture. I’ve been guilty in the past of thinking that one solution is all that is needed, whether at the storage, the cache, the automation, the DB, or the message bus layer to ensure resilience and optimize trade-offs between resilience, cost, and performance. These days I fall back on the principles I discussed above.
As you can see , I’m not a big fan of trying to add resilience to our systems by bolting on an opaque and monolithic storage layer. This can cause unknown behavior in the midst of unexplained change, i.e. cascading failures. Rather, we recommend injecting just enough storage into your environment by extending Kubernetes itself, where appropriate, with the help of projects like OpenEBS. If you do have a pre-existing storage layer, no problem. You can make it more resilient and extend far greater granular control of storage services by running a solution like OpenEBS on top.
Whatever path you take, I really do think you will be best served by taking the necessary steps to avoid the risk of cascading failures. By solving issues as close to their occurrence as possible, allowing each team to choose their own approach, planning for failure of even the backup pieces, and by participating in transparent communities, you will be able to keep moving quickly without losing data.
As always, feedback is welcomed and encouraged.
Slides: https://docs.google.com/presentation/d/1HN25JftStju9-twyqjRowuZeQU0_WNbcQH7kO_v66aU/edit?usp=sharing
This article was first published on Feb 21, 2019 on OpenEBS's Medium Account.





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu