

Thanks for reading. Here I try to make 5 specific predictions that we can look back on in a year. Hopefully, along the ways, I leave some breadcrumbs that explain my thinking that could be of interest to the broader community. Feedback is welcome and needed.
5 Non Obvious Trends in Cloud Native Data for 2019
1. Kubernetes becomes the preferred solution for databases, ML and related storage and data management
The first couple of assertions may be fairly innocuous. One sign of the shift of database and ML workloads onto Kubernetes is the emergence of projects like KubeDirector and the recently announced Maestro from Mesosphere for the management of stateful workloads on Kubernetes as well as the continued growth of KubeFlow and other projects for ML on Kubernetes.KubeDirector is an interesting project that aims to eliminate a lot of the hard-coded components of many operators - replacing these with additional metadata fields. I see a few such projects emerging. An operator for stateful workloads that we see used some in the OpenEBS community is https://kubedb.com which supports several workloads such as Elastic and MySql. And just about every database has an operator or two from the project or related projects, with CrunchyDB https://github.com/CrunchyData/postgres-operator being a notable example that we see used quite a bit for running PostgreSQL.
I am pretty optimistic about Mesosphere’s ability to deliver an “universal operator” because they have the experience of running stateful workloads on Mesos and, well, because Florian’s blog announcing it makes a lot of sense. In other words, I have not played with it and have yet to see users on the OpenEBS community using it. Nonetheless, I definitely recommend keeping an eye on it.

Read more here: https://mesosphere.com/blog/announcing-maestro-a-declarative-no-code-approach-to-kubernetes-day-2-operators/
KubeFlow has fast become one of the most popular projects in our broader ecosystem, with almost as many watchers or stars on GitHub as our own OpenEBS (I couldn’t resist…and to be clear KubeFlow is more broadly adopted as far as I know, than OpenEBS so far) https://github.com/kubeflow/kubeflow. One awesome looking project that KubeFlow embraces for the deployment of models on to Kubernetes is called Seldon. Rather than try to explain Seldon I’ll just direct you to their site and to this image from their site:
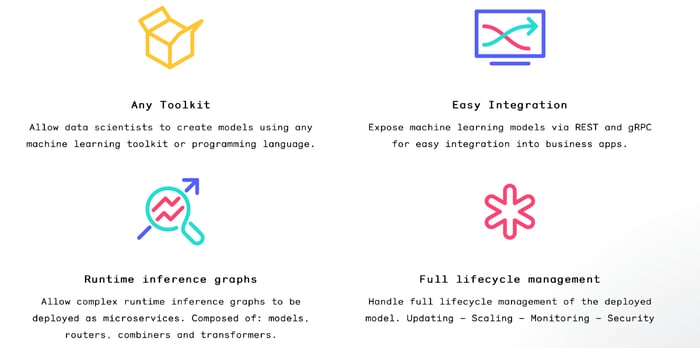 Seldon explained
Seldon explainedWith users like JD.com and Adobe starting to use OpenEBS in their analytics and ML pipelines, we are quickly learning more about these and similar projects. Which ones did I miss? Where would you suggest we proactively investigate?
Just as we are seeing operators and similar for DBs and ML - we also believe intelligence for the management of disks, local PVs, and related storage tasks that are similarly delivered via operator code patterns will emerge. We are already seeing this is in the takeoff of adoption of our open source OpenEBS. And I’m confident we will see the NDM project that is upstream in Kubernetes will see more outside contributors as it helps solve many standard disk layer issues in a Kubernetes native way.
At December’s KubeCon over 600 would be attendees to the cloud-native storage day were left on the waiting list - the idea of using Kubernetes itself as a substrate for stateful workload management is now well accepted or at least of interest to much of the Kubernetes community.
2. Progress in the world of NVMe disrupts existing NoSQL and storage systems
Just about every data stack these days has a key-value store embedded in it. You can think of there being two uses for these key-value stores - one for metadata about devices (and here the NDM project https://github.com/openebs/node-disk-manager should win out over time for storage projects and other users of underlying media that are built upon Kubernetes) and the other for location information about sectors on the disk. Yes, that’s a massive oversimplification. Anyway, just as the NDM Kubernetes project will disrupt higher level inventory, the on-disk KVs will disrupt the lower layer KVs. This is likely worthy of a blog or ten itself - however for now if you want to look into the future of NVMe and containerized more broadly I’d point you towards the talks given by our CTO Jeffry Molanus.
One of my favorite examples:
Follow Jeffry at @JeffryMolanus
And it is not just KVs that is getting built into the underlying hardware - effectively w/ NVMe over TCP (which was just ratified last month) you have a data fabric that is able to provide much lower latency and that better leverages multi-core environments. There is some thought that the fundamental architecture of systems will evolve or shift, with WD as an example arguing that infrastructure itself will be composable. So the silos between pieces of the infrastructure stack will erode, which brings us to…
3.Silos continue to erode - AppOps comes even more to the fore
This one might be a bit uncontroversial, however when you peel back the approach of many projects and storage vendors you’ll see that they don’t really get the new personas that are now driving most decisions. These developers and DevOps engineers are quite a bit different than traditional infrastructure silo specialists, such as storage engineers or network engineers or even data backup engineers that focus entirely on a particular technology.
Instead of selecting based on traditional bottoms up speeds and feeds metrics the new personas are selecting for a number of reasons that are perhaps best summarized by a recent talk from by Ryan Luckie at Cisco that he gave at the container native storage day at KubeCon:

Case Study: On-Prem Lab Environment by Ryan Luckie
You can see the entire talk here:
It may also be worth noting that the patterns of operations of complex workloads on Kubernetes is itself somewhat in flux. The meme “don’t give you developers access to Kubernetes” makes frequent appearances on Twitter. A good Twitter thread might be this one initiated by Dan Woods from Target where they run a lot of Kubernetes that includes this concept and much more including explaining why lots of smaller clusters is a good pattern:
https://twitter.com/danveloper/status/1078828177810735104
4. Operational patterns for cross-cloud emerge
Today we see many projects emerging that are enabling a level of cross-cloud management, including the nascent Crossplane. We’re seeing our DMaaS for API driven stateful workload migration, back-up, and rebalancing as an important part of this pattern as it emerges.
Meanwhile, the multicluster-SIG seems to be one of the most active SIGs within Kubernetes itself. You can follow the emergence of v2 of the Cluster Federation APIs and learn more about how to run Kubernetes to enable multi-cluster service discovery and resilience at their project page here
5. Rust takeoff continues
System software is important. And often annoying. We have seen many efforts over the years to replace or at least complement C and C++ with other languages and yet when it comes to reliability and performance and other attributes that are so important at the interface between hardware and software that system software provides - we come back home to C.
Witness our own cStor which is a refactored containerized storage controller written in C. In hindsight if we had waited a year or two we likely would have chosen Rust and, in fact, the skunk workers are working away on Rust at MayaData
Why? What’s so great about Rust? Bryan Cantril is far more qualified than I am to talk about the subject and he has done a number of times. I strongly recommend his talks.
Here is a summary slide from one excellent example - I picked this one in part because he highlights the shift of the cognitive load, which seems spot on to what I’ve witnessed:

So what? Why should the average user of distributed systems (i.e. you the reader) care at all about Rust? Well - a) it should lead to faster innovation at the systems layer and b) this is especially needed now as aspects of traditional operating system capabilities are reimplemented in the user space. And that is important because the boom in the number of cores - and the idea of running software like storage software as userspace containers - catches hold. And that, in turn, is important because userspace software is able to run anyway and is amenable to being orchestrated more easily by Kubernetes. In short - Rust will bring incredible power and performance to the ease of use and ubiquity of Kubernetes.
Conclusion
I hope the above 5 points were of interest. We seem to be quickly building our way towards El Dorado. Imagine distributed systems that are “easy” to operate, that are a common layer across clouds and hardware environments, that leverage key-value stores that are well understood to deliver massive performance from NVMe, and that are increasingly built upon a modern language that better delivers performance and safety than C and C++. Put all of that together and we seem likely to make it through to a world in which the new personas of full stack operators and developers have a fighting chance to make it all work together while accelerating enormously innovation.
We’ll be pitching in ourselves at MayaData, working hard to deliver data agility - the ability for today’s full stack operator personas to treat stateful workloads increasingly like stateless workloads. We need your help in the form of feedback, OpenEBS, and MayaOnline usage, and, yes, code. Happy New Year!
This article was first published on Jan 9th, 2018 on MayaData's Medium Account





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu