

Kubera for cloud-native back-ups on Kubernetes
As explained in a recent article on the New Stack, data protection requirements on Kubernetes of stateful workloads are fundamentally different from prior approaches to back-ups, disaster recovery, and cloud migration.

In this blog, we briefly explain how Kubera from MayaData addresses the details of data resilience by looking at the three cloud-native design principles which underline Kubera.
If you’d like to see Kubera deliver per application back-ups live - please join us in a webinar on August 6th when we will be joined by Cloudian, a leader in enterprise-class S3 compliant object storage.
https://go.mayadata.io/data-protection-for-kubernetes-webinar
Design principles
Kubera was designed to enable back-ups with a few common cloud-native principles in mind:
- Single slice and two pizza teams - as well as by the broader platform team
- Flexible - batteries included however not required
- Built to fail
Individual and small team usage
Kubera enables the individual or small team to protect their data. It does this by enabling per workload back-up policies. These policies are managed on your Kubera account. Backup policies include S3 compliant backup target configuration like AWS, GCP, MinIO or Cloudian HyperStore, S3 target specific region information, time interval, and retention count. Once started, they run based on the defined schedule. Backups generated by the backup policies can be used to restore the application and data within the organization on any cluster.
When using Kubera, the flow for data protection is generally from the workload - or application - to set up the schedule.
This per-application view is fundamental to Kubera. Many common workloads are preconfigured into Kubera - so that, for example, when you ask Kubera to log, visualize, back-up, and report upon a set of containers running MinIO, Kubera will notice that and apply a relevant set of defaults. Application Discovery is one of the key features of Kubera. Kubera can detect a growing number of stateful workloads and provide application-specific features.
The platform team can then use Kubera to have a more comprehensive view of back-ups and analytics by the application.
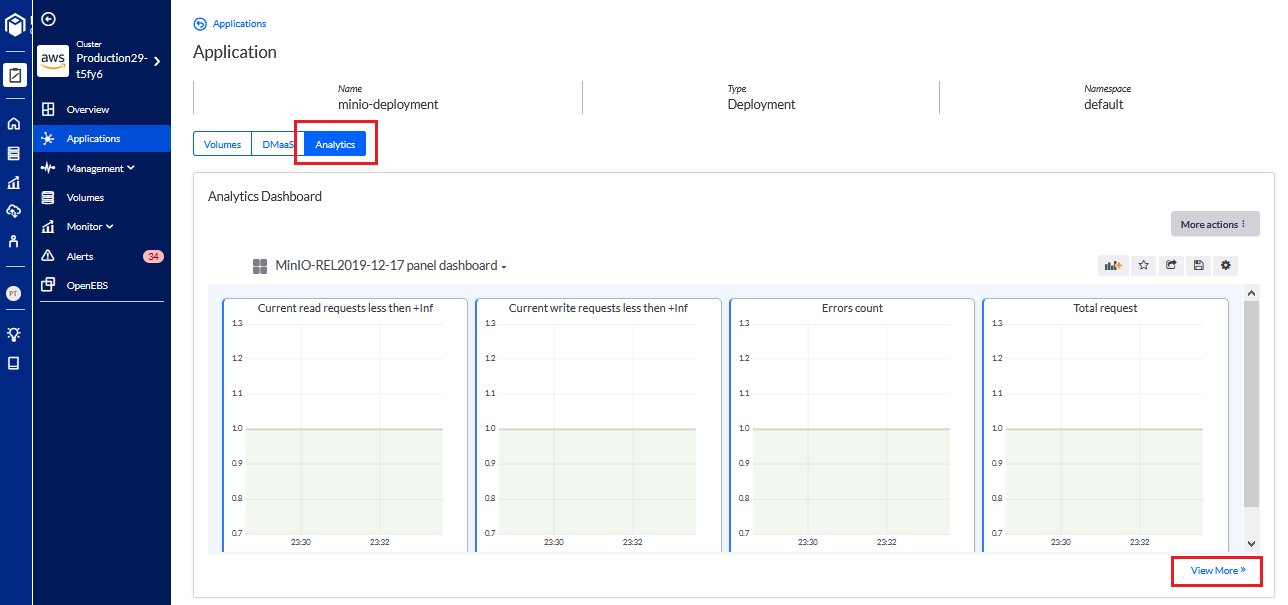
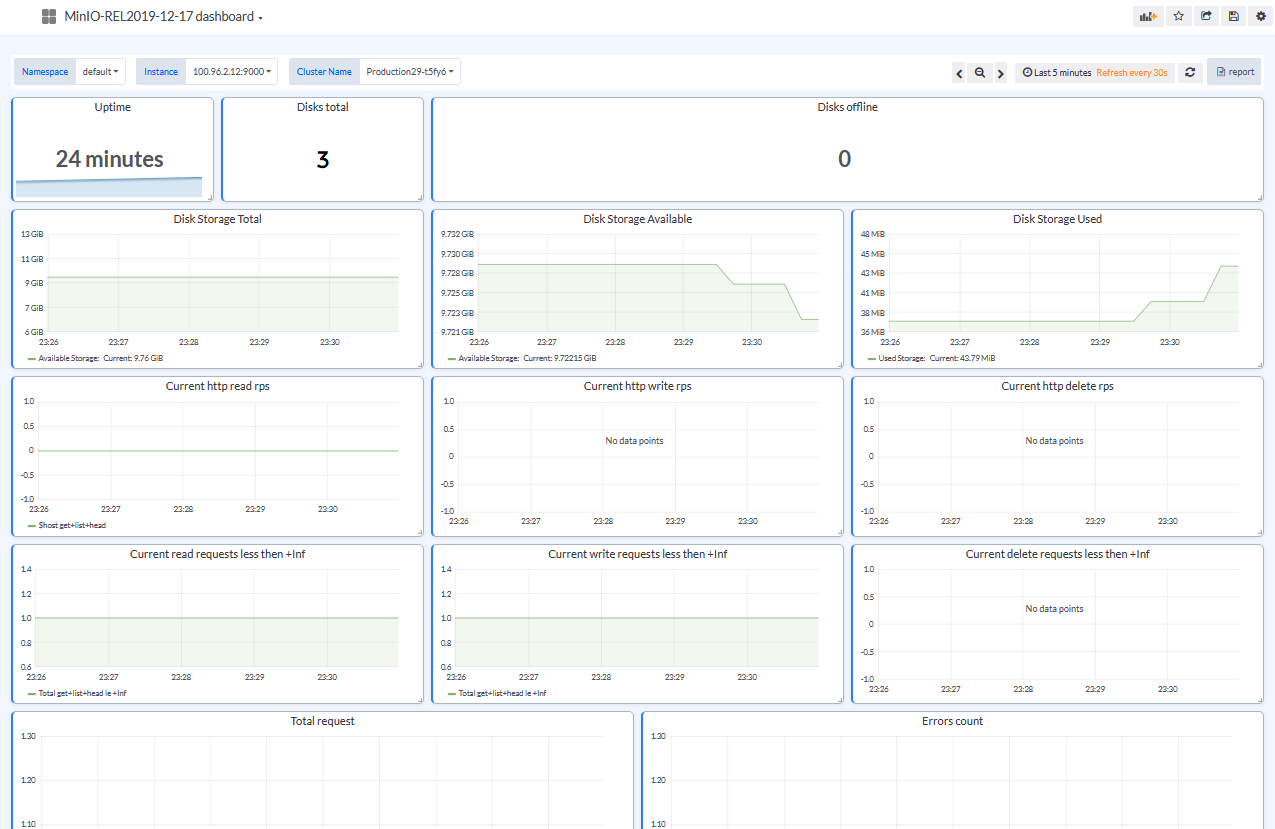
Flexibility - OpenEBS enabled but not required
OpenEBS is fairly well known for including an optional storage engine that is extremely efficient at snapshots and clones. This storage engine, cStor, is particularly well-suited for workloads for which many back-ups and cross-cloud replication are required. cStor is a Copy on Write (CoW) storage engine, meaning that snapshots are incremental and extremely space-efficient.
Many users of OpenEBS select cStor for workloads that require multi-level resiliency.
At the host level: At the host level, cStor can pool underlying disks or cloud volumes. This improves the ability of cStor to expand easily and also to protect against single disk failure.
At the availability zone level: Many users of cStor then select cStor to create 3 replicas. These replicas are created synchronously and are often distributed across availability zones. If the primary node is lost, the stateful workload can be rescheduled to another node where, typically, a replica will already be located. The workload can then be quickly served even as, in the background, cStor replaces the third replica.
At the cluster or data center level: For those cases in which a cluster is destroyed, cStor can be used with DMaaS to protect the data by backing it up to any S3 object storage. Often this S3 target can be a MinIO instance running on OpenEBS in another location - on another cluster. Increasingly we see enterprise solutions such as Cloudian HyperStore used within data centers. Cloudian’s resistance to ransomware attacks seems to be driving some of its popularity. Many other times, the S3 target is simply S3 itself. In all cases, the process of backing up and recovering the data can be automated via Kubera.
Now - let’s imagine that you are not using cStor because your workload does not require three-tier resiliency. Perhaps the workload itself is already resilient because it is Cassandra, Yugabyte, Kafka, or a similar workload. Therefore you do not need OpenEBS to deliver cross availability zone resilience and prefer OpenEBS not to create three replicas. In this case, you may choose to optimize the higher performance offered by the use of a flavor of OpenEBS LocalPV. Even in this case, Kubera can still provide the third level of resilience at the cluster or data center level. The approach taken in this case is to back-up one or more nodes of the Cassandra ring, for example, thereby in addition to protecting against the data center and cluster failure, also protecting against the loss of an entire Cassandra ring. Because OpenEBS cStor is not being used in the data path, Kubera must take somewhat less efficient back-ups using Restic. Nonetheless, scheduling and management are the same; just the cStor slider is not selected.
Built to fail
The last design principle that is important to highlight is the built to fail approach. One of the counter-intuitive aspects of cloud-native architectures is to improve resilience. Each component needs to assume that it will fail. OpenEBS is perhaps the most cloud-native in design amongst well known cloud-native storage software. Each component of OpenEBS is a microservice, and these components are loosely coupled. Here are a few aspects of being built for failure that differentiate OpenEBS and Kubera from other data protection approaches:
- Userspace only: OpenEBS cannot, for example, be dependent upon a particular operating system module. What happens if the underlying environment is lost and blown away, and OpenEBS is quickly redeployed and starts to recover data from a distant back-up? That redeployment would require manual intervention or extremely gifted scripting if OpenEBS were to require a special build of the underlying OS to begin work. The result would be extended downtime and even, in certain scenarios, data loss. OpenEBS requires Kubernetes. That’s it.
- Mobile metadata: Traditional shared everything storage systems like CEPH keep much of their metadata in a special-purpose database that must be kept resilient much so that etcd must be kept alive in a Kubernetes environment. OpenEBS is different in a couple of ways. First, some of the basic metadata, such as what disks are available, are stored via custom resource definitions in etcd itself. Secondly, metadata about each volume backing each workload are stored within the volume itself. This means that when a volume is reconstituted on a brand new cluster, it can “find itself” without needing to reconcile itself with a special-purpose metadata database that itself is a single point of failure.
- Tiny blast radius: Last but perhaps most importantly, OpenEBS partitions the problem of performance and resilience and management and more - the entire storage management problem - on a per workload basis. If the worst happens and OpenEBS itself fails, it only fails for a particular workload. This retains and protects the loose coupling of the workloads that it is serving. By comparison, a shared everything system can bring an entire environment down because it could make unavailable all stateful workloads concurrently.
Conclusion
In conclusion, Kubera reflects a few simple design principles that are not unique - they echo the design principles of cloud-native workloads. Cloud-native patterns have helped build the world’s largest computing environments, dramatically improving the productivity of engineering teams while reducing downtime and operational risk. The approaches to delivering data resilience taken by MayaData and Kubera preserve these benefits by delivering multi-tier data resilience.





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Deploy WordPress on AWS Using OpenEBS
Ranjith Raveendran
Ranjith Raveendran
Container Attached Storage (CAS) vs. Shared Storage: Which One to Choose?
Kiran Mova
Kiran Mova