

In large scale environments, storage is one of the hard things to manage, and it will be the most crucial component as it has DATA with it. OpenEBS, leading open source Cloud Native Storage, makes managing storage easier in Kubernetes environments. Mayadata, the company behind the OpenEBS project, has the vision of achieving data agility by transforming Kubernetes as a data plane. cStor is one of the storage engines of OpenEBS. This blog is for OpenEBS users, specifically cStor users who are well versed with cStor terms. It brings out the details in knowing the storage space consumed, matching numbers from different resources in various scenarios. Thanks to tklae for helping me with content in making this blog.

As you might be already aware, cStor comprises a cluster of pools on different nodes and volumes created on these pools. As part of this setup, cStor uses the following Custom Resources (CR): A StoragePoolClaim (SPC) represents a cluster of cStorPools (CSPs), whereas a CSP represents each pool in the cluster. Each CSP group a set of physical or virtual disks. A cStorVolume (CV) represents a Kubernetes dynamically provisioned Persistent Volume (PV) based on cStor and consists of one or more replicas represented by a cStorVolumeReplica (CVR).
Once the disks are added to the pool (CSP), they cannot be removed but can be replaced. So, it makes sense to monitor the available capacity or consumed storage at the pool level through CSP CR.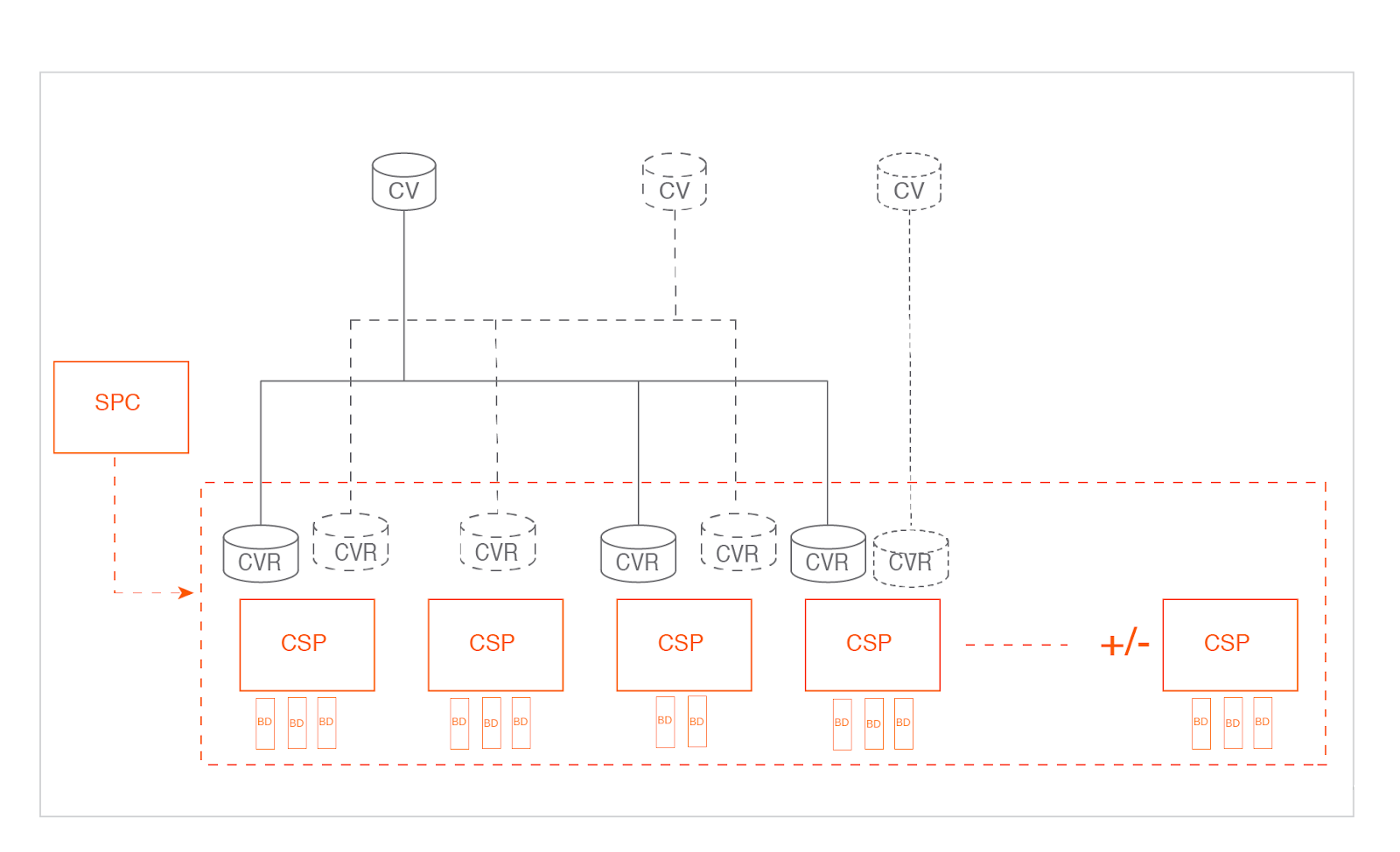
For example, SPC ‘cstor-disk-pool’ is a cluster of 2 pools, `kubectl get csp` sample output is as below:
NAME ALLOCATED FREE CAPACITY STATUS TYPE AGE
...
cstor-disk-pool-ge0f 1.40T 97.4G 1.49T Healthy striped 28d
cstor-disk-pool-r1pa 550G 978G 1.49T Healthy striped 28d
Below is a description of the fields:
`CAPACITY`: Usable capacity of the pool by considering RAID properties of the pool.
`ALLOCATED`: Storage space consumed on the pool.
`FREE`: Available capacity on the pool for further consumption, which is (`CAPACITY` - `ALLOCATED`).
The below link lists the statistics that are exported as Prometheus metrics for monitoring: monitor-pool and monitor-cStor-Volume. So, an accurate value of storage consumption and available capacity can be obtained by monitoring the status of CSP CRs.
Another way of calculating consumed space is by summing disk usage on the mount point of all volumes on the pool.
For example, there are two volumes on the first pool, and their mount points in their containers are /data and /logs. `du -sh` sample output from mount point of these volumes are:
$ du -sh /data
800G /data
$ du -sh /logs
800G /logs
There are scenarios where the consumed space calculated by summing up disk usage on a mount point is greater than the `Allocated` value in a CSP.
As you might have noticed in this example - consumed space calculated from mount points, i.e., ~1.60T (800G + 800G), is greater than `Allocated` on the first pool cstor-disk-pool-ge0f, i.e., 1.40T. This is possible due to compression, which is enabled by default on the cStor pools. This means data written into cStor volumes are compressed by default. So, in this example, 1.6TB of data had been written to the pool by consuming a space of 1.4T. Status on CVR provides information like Used and Allocated space on the replica from which the compression ratio can be calculated.
NAME USED ALLOCATED STATUS AGE
pvc-5e3cfa47-0195-442c-ad5f-cbeafe6d60d0-cstor-disk-pool-ge0f 800G 720G Healthy 28d
pvc-e33e6e17-df96-4601-a5b2-fb398c25cb39-cstor-disk-pool-ge0f 800G 680G Healthy 28d
pvc-a8c64536-a85c-4f31-9c48-5281cd9b5207-cstor-disk-pool-r1pa 350G 250G Healthy 28d
pvc-u7d54536-a85c-5g31-9c48-9384cd9b5657-cstor-disk-pool-r1pa 320G 300G Healthy 28d
Below is a description of the fields:
`USED`: Amount of data written by file system onto iSCSI disk
`ALLOCATED`: Amount of data written on the pool after compressing the data written on iSCSI disk
The above values include space consumption by snapshots taken on the replica.
`kubectl get cvr -l cstorpool.openebs.io/name=<poolname> -n openebs` provides the list of replicas on a particular pool.
There are also scenarios where consumed space calculated by summing disk usage on mount point is less than the `Allocated` value in CSP.
One such scenario is due to the snapshots of the cStor volumes. cStor provides referential based snapshots. So, when a snapshot is taken, space consumption will not increase on the pool. But, as write IOs happen on the volume, space consumption on the pool increases. In such cases, ‘du -sh’ on the mount point will be less than the `Allocated` value in CSP. From version 1.9 of OpenEBS, enabling the ‘REBUILD_ESTIMATES’ environment variable of a pool deployment populates the status of a CVR with information regarding snapshots of the replica. Sample output of CVR is as follows:
```
apiVersion: openebs.io/v1alpha1
kind: CStorVolumeReplica
metadata:
annotations:
...
finalizers:
- cstorvolumereplica.openebs.io/finalizer
generation: 6
labels:
cstorpool.openebs.io/name: cstor-disk-pool-ge0f
cstorvolume.openebs.io/name: pvc-5e3cfa47-0195-442c-ad5f-cbeafe6d60d0
...
name: pvc-5e3cfa47-0195-442c-ad5f-cbeafe6d60d0-cstor-disk-pool-ge0f
spec:
capacity: 150G
replicaid: C0968EFA368C815D9870637E60025106
targetIP: 10.0.0.225
...
status:
...
phase: Healthy
snapshots:
volume_snap1:
logicalReferenced: 424673280
…
```Below is description of fields under `status.snapshots.<snapName>`:
`logicalReferenced`: Used size in bytes of the replica when snapshot was taken
Another scenario is the deletion of files in the mount point. When files are deleted, `du -sh` shows that space is freed. For example, if the user deleted 100G of data on /data mount point, its `du -sh` would be:
$ du -sh /data
700G /data
Reduction in space won’t be reflected on CSP (or) CVR, as UNMAP is not supported in cStor volumes. However, this freed space on the mount point can be used for new writes on that volume by the application file system.
So, when the pool becomes full, in order to make free space, snapshots on a PVC or a PVC itself needs to be deleted. Space consumed by them will become available for other volumes, and the `Allocated` value in CSP goes down(It will take a few minutes to reflect in values). Till free space is made available on the pool either by adding new disks to the pool or by deleting snapshots / PVCs, IOs on the volume replica will error out. From 1.9 version of OpenEBS, if the pool becomes 85% full (this threshold is 100% in previous versions of OpenEBS), all the replicas on that pool will get into ReadOnly state and further write IOs will error out. Once the free space is available, it will automatically convert replicas into ReadWrite.
Disparity in allocated space among pools:
Replicas of cStor volumes are randomly spread among pools of SPC without considering provisioned or allocated space of the pools. Due to this, there can be a disparity in allocated space among pools. The disparity at the pool level can also happen when there is a disparity in consumed space among volumes and snapshots on the volumes.
The disparity is shown in the sample output of `kubectl get csp` at the top where the first pool is having `Allocated` space as 1.40TB, and another pool has 550G.
Few Gotchas:
- If we delete a PVC which has one or more snapshots, PVC, PV, underlying volume and snapshots will be deleted. But the VolumeSnapshot and VolumeSnapshotData CRs will remain in the cluster. This issue is being tracked here.
- The deletion of PVC will fail if there are any clones created from the snapshots of this PVC.
- Being referential snapshots, PVCs created from them cannot be detached from the original PVC. They can only be detached by the migration of the data to a new PVC.
Please provide your valuable feedback & comments below and let me know what I can cover in my next blog.





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu