

I'm a Developer Advocate at MayaData, a company dedicated to enabling data agility through the use of Kubernetes as a data layer and the sponsor of the CNCF project OpenEBS and other open source projects. Take it for a test drive via free and easy to use management software by registering here.
Simplifying the use of Apache Kafka on Kubernetes
Sometimes you get a nice big chunk of data, all structured and ready to read in, process, and do something with. Sometimes. More commonly, your data comes in dribbles, bursts, and sometimes a fire-hose. So what do you do with this kind of streaming data? How do you make sure you’re processing efficiently and close to real-time, while not dropping data due to lack of capacity?
Well, you might want to look into a streaming pub/sub system like Apache Kafka. It works great inside of Kubernetes -- with the help of OpenEBS Dynamic LocalPVs -- and gives you a message bus that all of your components can talk on. With Apache Kafka, you can have data streaming in on one topic. You can consume that topic with a job that will categorize the bits of data and put them on different topics. You might have other jobs that process and create their own artifacts that they push to a topic, whatever you might like. And then, maybe you have a final topic you use to put all of the incoming data along with related data generated by your app components into your data lake.

You can use it as a reliable message queue, but with multiple subscribers, data persistence, and the ability to run code in the data stream. Just throw some data at it and let Apache Kafka organize it for you and get the data where it needs to be. Because of its design, it’s capable of buffering for a while if you get a burst of data that comes in faster than your processors can process it. This turns out to be a big deal when you’re trying to keep your software components loosely coupled.
You can see that the code is pretty straightforward from this python example:
#!/usr/bin/env python
from time import sleep
from json import dumps
from kafka import KafkaProducer
import os
print('\n\nrunning on ', os.environ['MY_POD_NAME'], '\n')
producer = KafkaProducer(bootstrap_servers=['kafka-svc'],
value_serializer=lambda x:
dumps(x).encode('utf-8'))
for i in range(200):
data = {'key' : 'string'}
producer.send('random', value=data)
print("sent ", i, "th clump of random data\n")
sleep(.1)
That’s a pretty easy way to output data. In this example, ‘random’ is a topic name, and Python will dutifully put our sequential integer onto that Kafka topic for consumption by anyone who asks. It’s pretty much just as easy to catch it on the other end:
#!/usr/bin/env python
from kafka import KafkaConsumer
import os
print('\n\nrunning on ', os.environ['MY_POD_NAME'], '\n')
consumer = KafkaConsumer('random',
bootstrap_servers = 'kafka-svc',
api_version = (0, 10))
for m in consumer:
print(m.value, "\n")
Apache Kafka can keep multiple replicas for resiliency
While our data is “in-flight”, Kafka can keep multiple replicas for resiliency. So, you can effectively use Kafka as a structured, buffered output for your program, and you can output more or less whatever you like, receive it on the other side. Kafka will keep it around until none of the consumers need it anymore. Um, where are we going to keep it?
Persistence in Kubernetes is also easy to solve with OpenEBS. You can install it on your cluster and create EBS style volumes using instance storage, use it to orchestrate existing disks on your nodes, and even use a local ZFS pool to create volumes in.
Cool. So, we have the need for Apache Kafka so our code can talk to other pieces of code as well as databases and other components (did I mention there’s a wealth of ready-to-use connectors out there?). We want it in Kubernetes because that’s where we’re running our app, and that way, it’s easy to manage. And we have OpenEBS to handle this new persistence requirement that Kafka brings with it.
So, let’s spin up a test cluster in our favorite cloud and see what we can do with this piece of technology.- Set up a cluster with some nodes that have local ssds, like aws i3 nodes.
$ kubectl get nodes NAME STATUS ROLES AGE VERSION ip-172-20-34-74.us-east-2.compute.internal Ready node 6d18h v1.14.10 ip-172-20-45-3.us-east-2.compute.internal Ready node 6d18h v1.14.10 ip-172-20-53-19.us-east-2.compute.internal Ready node 6d18h v1.14.10 ip-172-20-59-66.us-east-2.compute.internal Ready node 6d18h v1.14.10 ip-172-20-63-65.us-east-2.compute.internal Ready master 6d18h v1.14.10 - Install OpenEBS on the cluster (you can do this right from OpenEBS Director now)
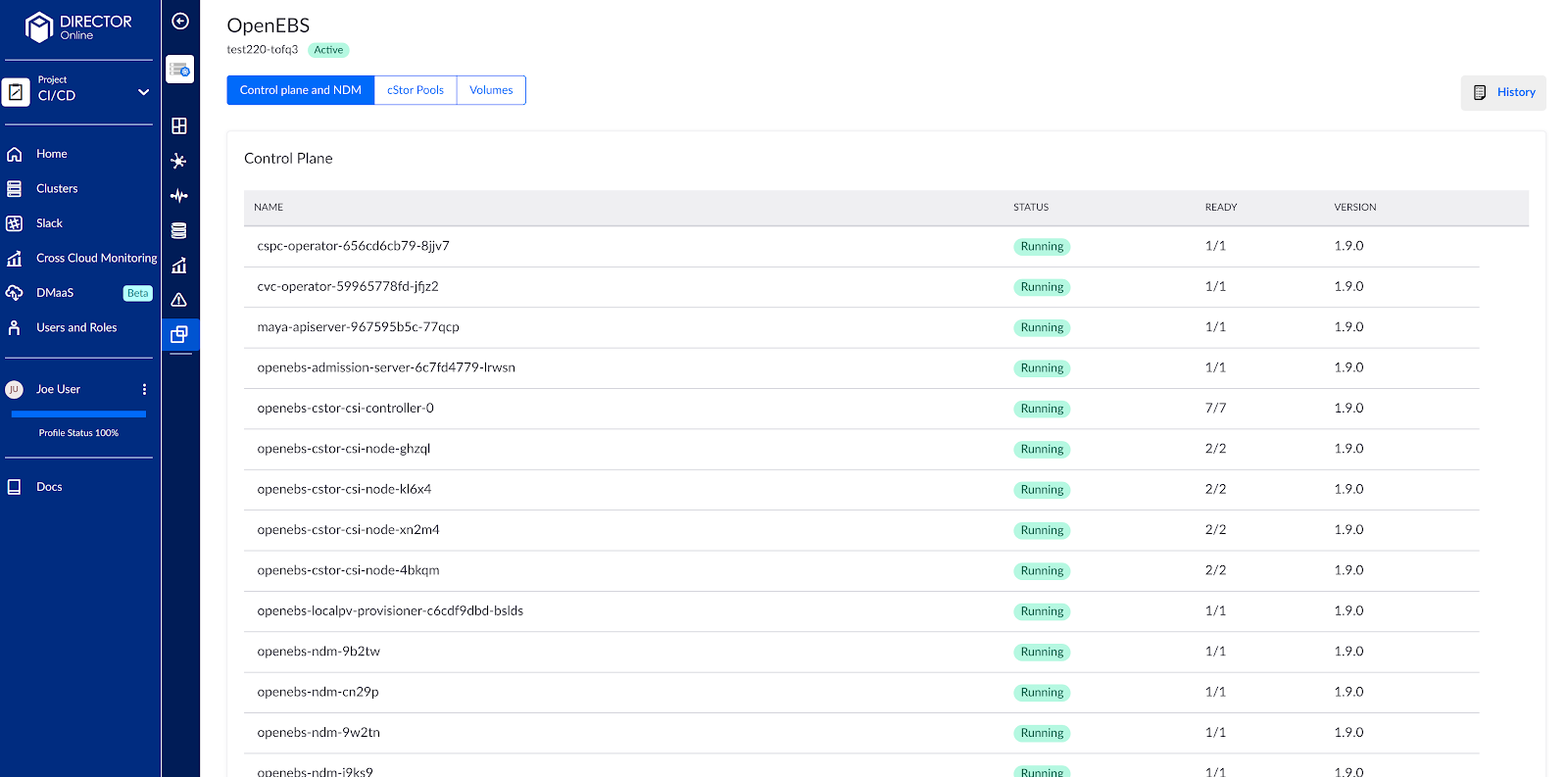
- Use OpenEBS to make a new StorageClass that targets that local ssd, or just use `openebs-device.’ I’ll use ZFS LocalPV in this example:
--- apiVersion: extensions/v1beta1 kind: DaemonSet metadata: namespace: openebs name: system-setup labels: openebs.io/component-name: system-setup openebs.io/version: 1.4.0 annotations: command: &cmd sed -i 's/main/main contrib/' /etc/apt/sources.list ; apt -y install ; apt -y update ; apt -y install open-iscsi zfsutils-linux; sudo sh -c 'systemctl enable iscsid ; sudo systemctl start iscsid ; sudo systemctl status iscsid ; for d in /dev/nvme0n1; do umount $d ; wipefs -f -a $d ; lsblk ; done; modprobe zfs ; zpool create zfspv-pool /dev/nvme0n1 ; zfs list' spec: selector: matchLabels: openebs.io/component-name: system-setup template: metadata: labels: openebs.io/component-name: system-setup spec: hostNetwork: true initContainers: - name: init-node command: - nsenter - --mount=/proc/1/ns/mnt - -- - sh - -c - *cmd image: alpine:3.7 securityContext: privileged: true hostPID: true containers: - name: wait image: k8s.gcr.io/pause:3.1 hostPID: true hostNetwork: true tolerations: - effect: NoSchedule key: node-role.kubernetes.io/master --- apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: openebs-zfs allowVolumeExpansion: true parameters: fstype: "zfs" poolname: "zfspv-pool" provisioner: zfs.csi.openebs.io volumeBindingMode: WaitForFirstConsumer - Install Zookeeper and Kafka (we like the KUDO operator for it) using that StorageClass
$ kubectl get pods -l heritage=kudo NAMEkafka-kafka-0 2/2 Running 0 11m kafka-kafka-1 2/2 Running 0 11m kafka-kafka-2 2/2 Running 0 11m zookeeper-instance-zookeeper-0 1/1 Running 0 11m zookeeper-instance-zookeeper-1 1/1 Running 0 11m zookeeper-instance-zookeeper-2 1/1 Running 0 11m $ kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE kafka-datadir-kafka-kafka-0 Bound pvc-9e408ab2-8bd8-11ea-b4f1-060d94d0ae04 5Gi RWO openebs-zfs 11m kafka-datadir-kafka-kafka-1 Bound pvc-b24f6bac-8bd8-11ea-b4f1-060d94d0ae04 5Gi RWO openebs-zfs 11m kafka-datadir-kafka-kafka-2 Bound pvc-c682fbd7-8bd8-11ea-b4f1-060d94d0ae04 5Gi RWO openebs-zfs 11m zookeeper-instance-datadir-zookeeper-instance-zookeeper-0 Bound pvc-ef99ec6c-8bd7-11ea-b4f1-060d94d0ae04 5Gi RWO openebs-zfs 11m zookeeper-instance-datadir-zookeeper-instance-zookeeper-1 Bound pvc-efa0ca56-8bd7-11ea-b4f1-060d94d0ae04 5Gi RWO openebs-zfs 11m zookeeper-instance-datadir-zookeeper-instance-zookeeper-2 Bound pvc-efaaf239-8bd7-11ea-b4f1-060d94d0ae04 5Gi RWO openebs-zfs 11m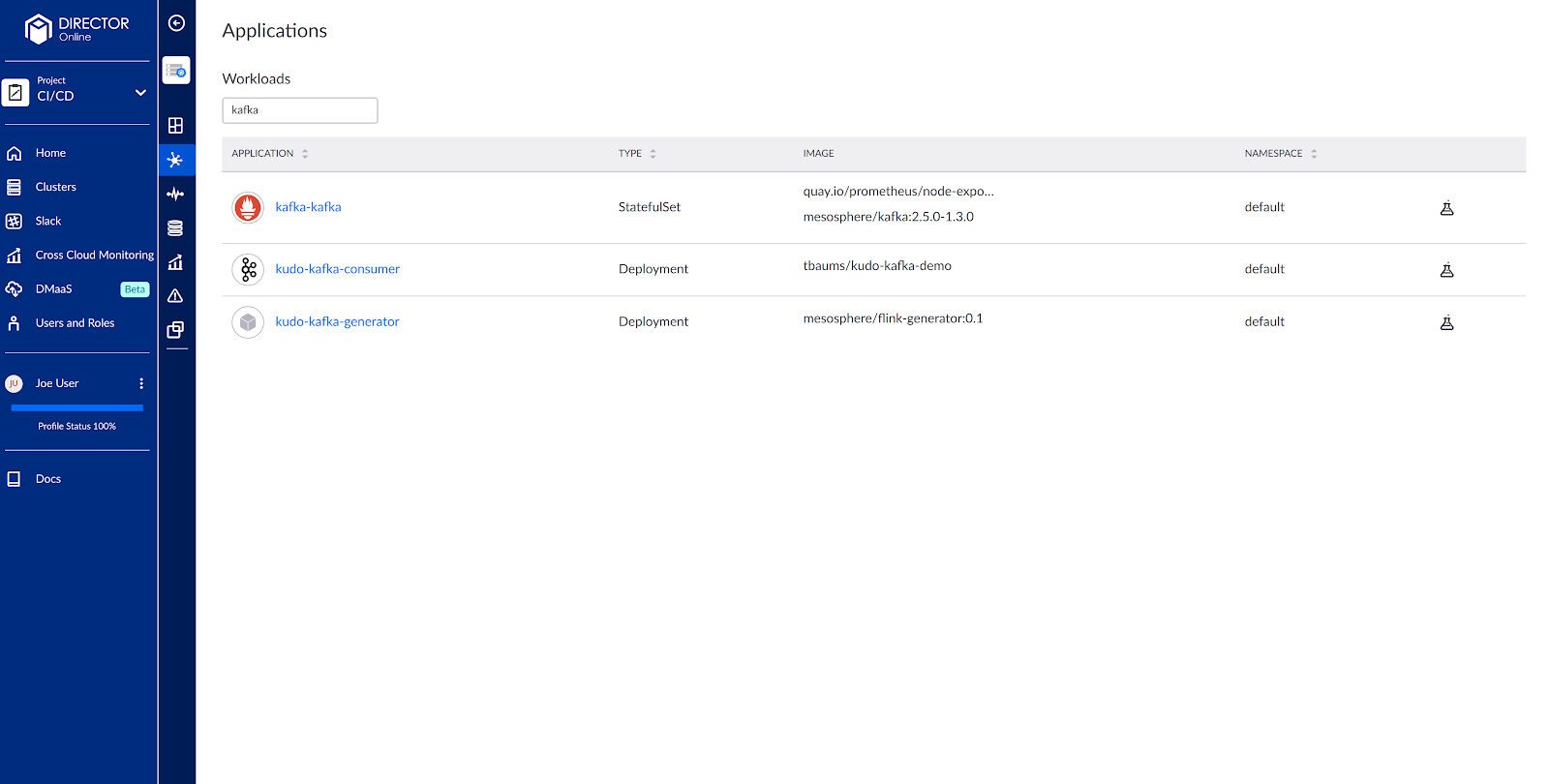
- Set up the Grafana dashboard and kick the tires on it a bit.
You can get more detail on these steps here.
Check back in this space for more information on Kafka in the future.
Important Links
Access Director online - https://director.mayadata.io
For help - https://help.mayadata.io
Join OpenEBS community — https://slack.openebs.io





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu