
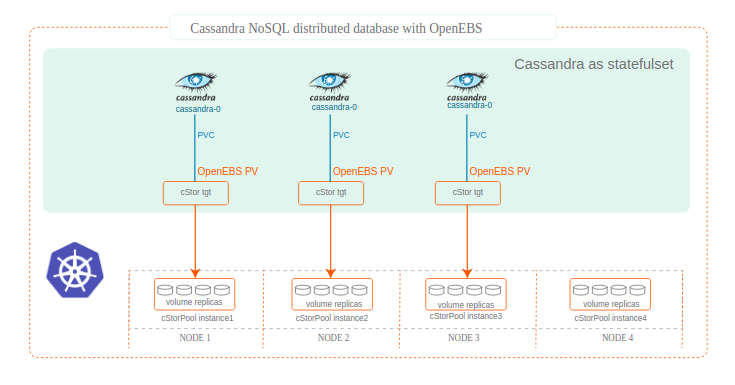
Apache Cassandra is a distributed NoSQL database management system designed to handle large amounts of data across nodes, providing high availability with no single point of failure. It uses asynchronous masterless replication allowing low latency operations for all clients. Cassandra is usually deployed as a stateful on Kubernetes and requires persistent storage for each instance of Cassandra. OpenEBS provides persistent volumes on the fly when Cassandra instances are scaled up.
Apache Cassandra Deployment on OpenEBS:
Step 1: Install OpenEBS
If OpenEBS is not installed in your K8s cluster, this can be done from here. If OpenEBS is already installed, go to the next step.
Step 2: Configure cStor Pool
After OpenEBS installation, the cStor pool has to be configured. If cStor Pool is not configured in your OpenEBS cluster, this can be done from here. During cStor Pool creation, make sure that the maxPools parameter is set to >=3. Sample YAML named openebs-config.yaml for configuring cStor Pool is provided below. If the cStor pool is already configured, go to the next step.
#Use the following YAMLs to create a cStor Storage Pool.
# and associated storage class.
apiVersion: openebs.io/v1alpha1
kind: StoragePoolClaim
metadata:
name: cstor-disk
spec:
name: cstor-disk
type: disk
poolSpec:
poolType: striped
# NOTE - Appropriate disks need to be fetched using `kubectl get blockdevices -n openebs`
#
# `Block devices` is a custom resource supported by OpenEBS with `node-disk-manager`
# as the disk operator
# Replace the following with actual disk CRs from your cluster `kubectl get blockdevices -n openebs`
# Uncomment the below lines after updating the actual disk names.
blockDevices:
blockDeviceList:
# Replace the following with actual disk CRs from your cluster from `kubectl get blockdevices -n openebs`
# - blockdevice-69cdfd958dcce3025ed1ff02b936d9b4
# - blockdevice-891ad1b581591ae6b54a36b5526550a2
# - blockdevice-ceaab442d802ca6aae20c36d20859a0b
---
Step 3: Create Storage Class
You must configure a StorageClass to provision cStor volume on a given cStor pool. StorageClass is the interface through which most of the OpenEBS storage policies are defined. In this solution, we are using a StorageClass to consume the cStor Pool, which is created using external disks attached to the Nodes. Since Cassandra is a StatefulSet application, it requires only one replication at the storage level. So the cStor volume replicaCount is 1. Sample YAML named openebs-sc-disk.yaml to consume cStor pool with cStor volume replica count as 1 is provided below.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: openebs-cstor-disk
annotations:
openebs.io/cas-type: cstor
cas.openebs.io/config: |
- name: StoragePoolClaim
value: "cstor-disk"
- name: ReplicaCount
value: "1"
provisioner: openebs.io/provisioner-iscsi
reclaimPolicy: Delete
---
Step 4: Launch Cassandra
Create a sample cassandra-statefulset.yaml file in the Configuration details section. This can be applied to deploy the Cassandra database with OpenEBS. Run kubectl apply -f cassandra-statefulset.yaml to see Cassandra running. This will configure the required PVC also.
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: cassandra
labels:
app: cassandra
spec:
serviceName: cassandra
replicas: 3
selector:
matchLabels:
app: cassandra
template:
metadata:
labels:
app: cassandra
spec:
containers:
- name: cassandra
image: gcr.io/google-samples/cassandra:v11
imagePullPolicy: Always
ports:
- containerPort: 7000
name: intra-node
- containerPort: 7001
name: tls-intra-node
- containerPort: 7199
name: jmx
- containerPort: 9042
name: cql
resources:
limits:
cpu: "500m"
memory: 1Gi
requests:
cpu: "500m"
memory: 1Gi
securityContext:
capabilities:
add:
- IPC_LOCK
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "PID=$(pidof java) && kill $PID && while ps -p $PID > /dev/null; do sleep 1; done"]
env:
- name: MAX_HEAP_SIZE
value: 512M
- name: HEAP_NEWSIZE
value: 100M
- name: CASSANDRA_SEEDS
value: "cassandra-0.cassandra.default.svc.cluster.local"
- name: CASSANDRA_CLUSTER_NAME
value: "K8Demo"
- name: CASSANDRA_DC
value: "DC1-K8Demo"
- name: CASSANDRA_RACK
value: "Rack1-K8Demo"
- name: CASSANDRA_AUTO_BOOTSTRAP
value: "false"
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
readinessProbe:
exec:
command:
- /bin/bash
- -c
- /ready-probe.sh
initialDelaySeconds: 15
timeoutSeconds: 5
# These volume mounts are persistent. They are like inline claims,
# but not exactly because the names need to match exactly one of
# the stateful pod volumes.
volumeMounts:
- name: cassandra-data
mountPath: /cassandra_data
volumeClaimTemplates:
- metadata:
name: cassandra-data
annotations:
volume.beta.kubernetes.io/storage-class: openebs-cstor-disk
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 5G
Apache Cassandra Monitoring on Kubera:
Connect your cluster to Kubera on which the Cassandra application is deployed. To know more, click here.
Step 1:
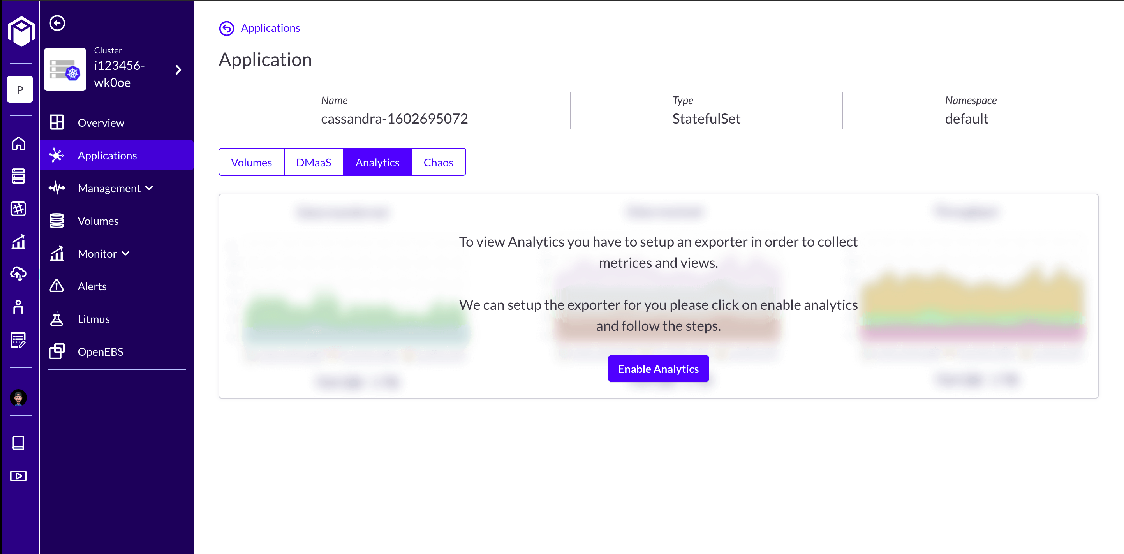
After connecting your cluster to Kubera, go to Cluster-->Applications-->Cassandra-->Analytics.
You will get a dashboard to enable analytics. Click on Enable Analytics.
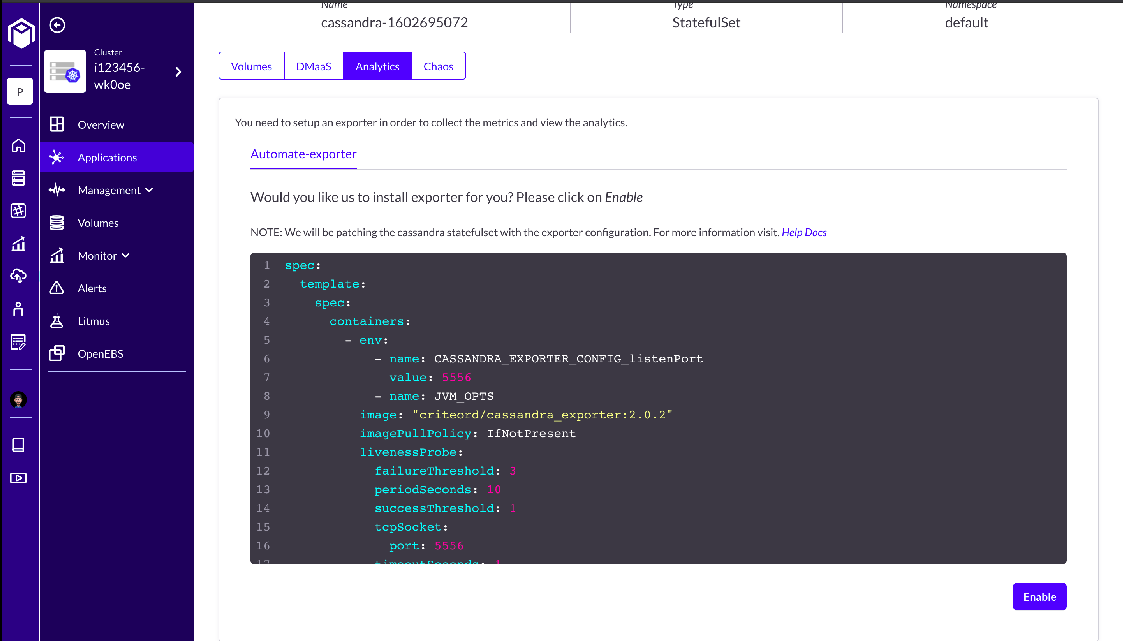
Step 2:
Clicking on Enable Analytics gives us the option of enabling the Automate Exporter. To enable the Automate-Exporter, click on the Enable option, as shown in the image.
Step 3:
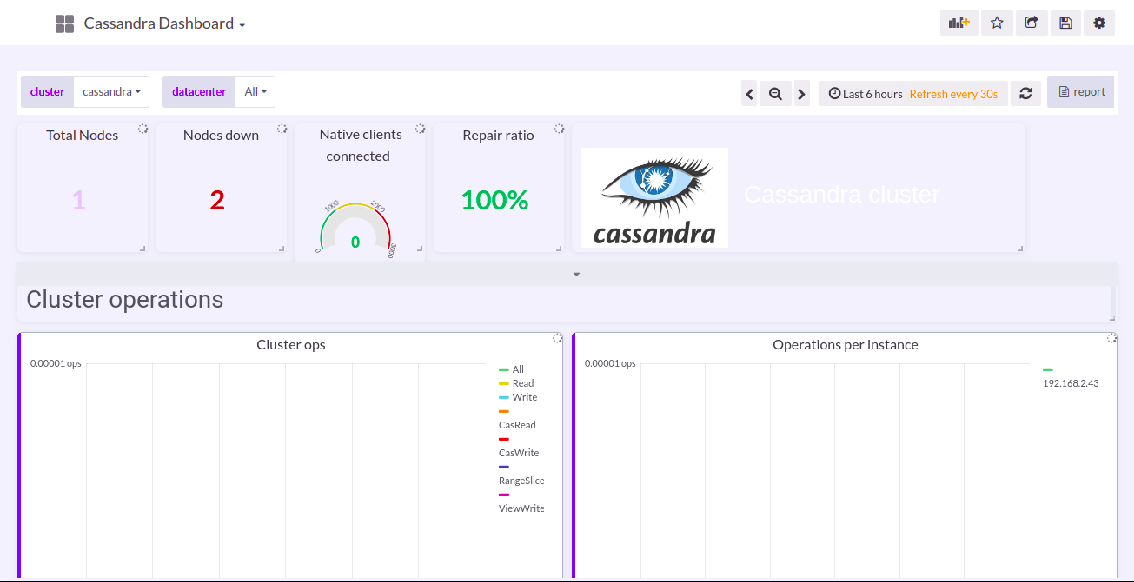
Clicking on Enable will redirect us to the Cassandra Application Dashboard.
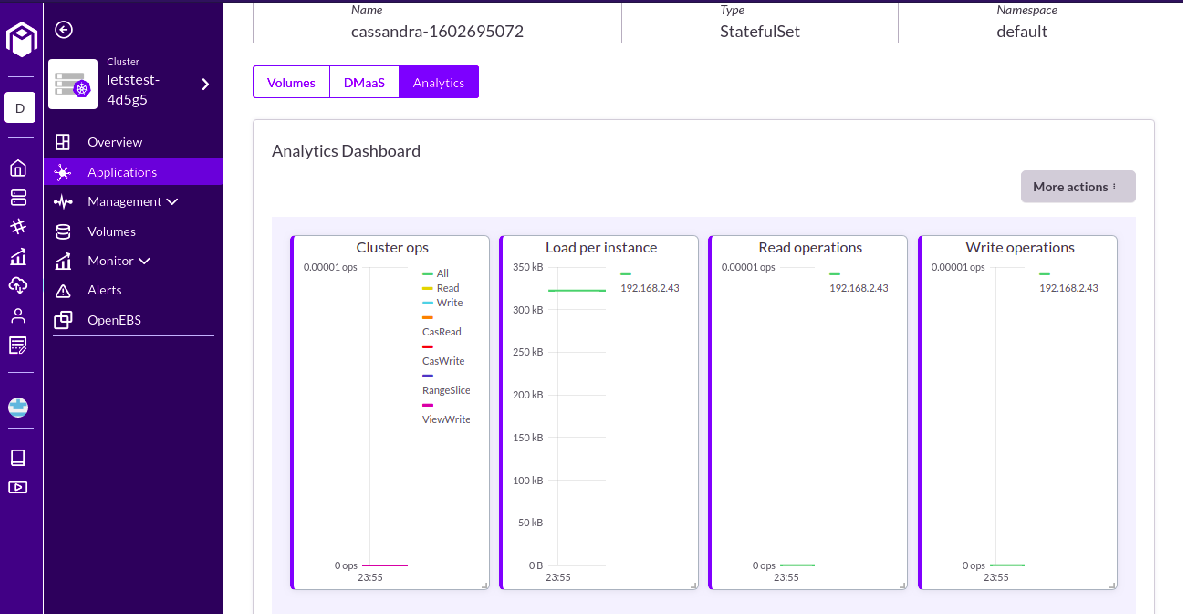
Step 4:
Clicking on View More present at the bottom to get the detailed overview and statistics of the application, as shown in the image below.





Game changer in Container and Storage Paradigm- MayaData gets acquired by DataCore Software
Don Williams
Don Williams
Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Understanding Persistent Volumes and PVCs in Kubernetes & OpenEBS
Murat Karslioglu
Murat Karslioglu