

I recently wrote a blog about how Kubernetes creates a global computing grid that delivers unprecedented compute flexibility. Then I wrote a blog about the importance of going fully Kubernetes-native. In today’s blog I would like to drill down into the role that the NVMe over Fabrics (NVMe-oF or just NVMF) standard will play in enabling Kubernetes infrastructure flexibility.

What is NVMe?
NVMe is a protocol that dictates how a CPU, moves memory via the PCI bus to a storage device. NVMe communicates over a set of rings (per CPU) where commands get submitted from any CPU to the underlying NVMe device. The design of NVMe eliminates intermediate layers between the CPU and the storage device. NVMe devices consist of a controller, queues, namespaces, namespace IDs, and the actual storage media with some form of an interface.
Storage media can be grouped into sections called namespaces with an ID. In the context of NVMF, namespaces provide a way to enforce access control for the disks / consumers. Namespaces are analogous to an OS partition, except the partitioning is done in hardware by the controller and not the OS (you can still have OS partitions on namespaces). Some NVMe namespaces might be hidden from a user (e.g. for security isolation). A controller connects to a port through queues and a namespace through its namespace ID. A controller is allowed to connect to multiple namespaces and a namespace is allowed to be controlled by multiple controllers (and thus also, multiple ports).
Imagine smearing out this NVMe device across multiple computers and you get to the next important concept, a storage fabric.
What is NVMF?
When you put a network between the PCI bus and the storage device, you use NVMe over Fabric (aka NVMe-oF or simply NVMF). NVMF enables fast access between hosts and storage systems over a network. Compared to iSCSI, NVMF has much lower access latency, in practice adding only a small latency difference between local and remote storage. NVMF delivers a breakthrough in throughput and seek time relative to traditional device attached storage:
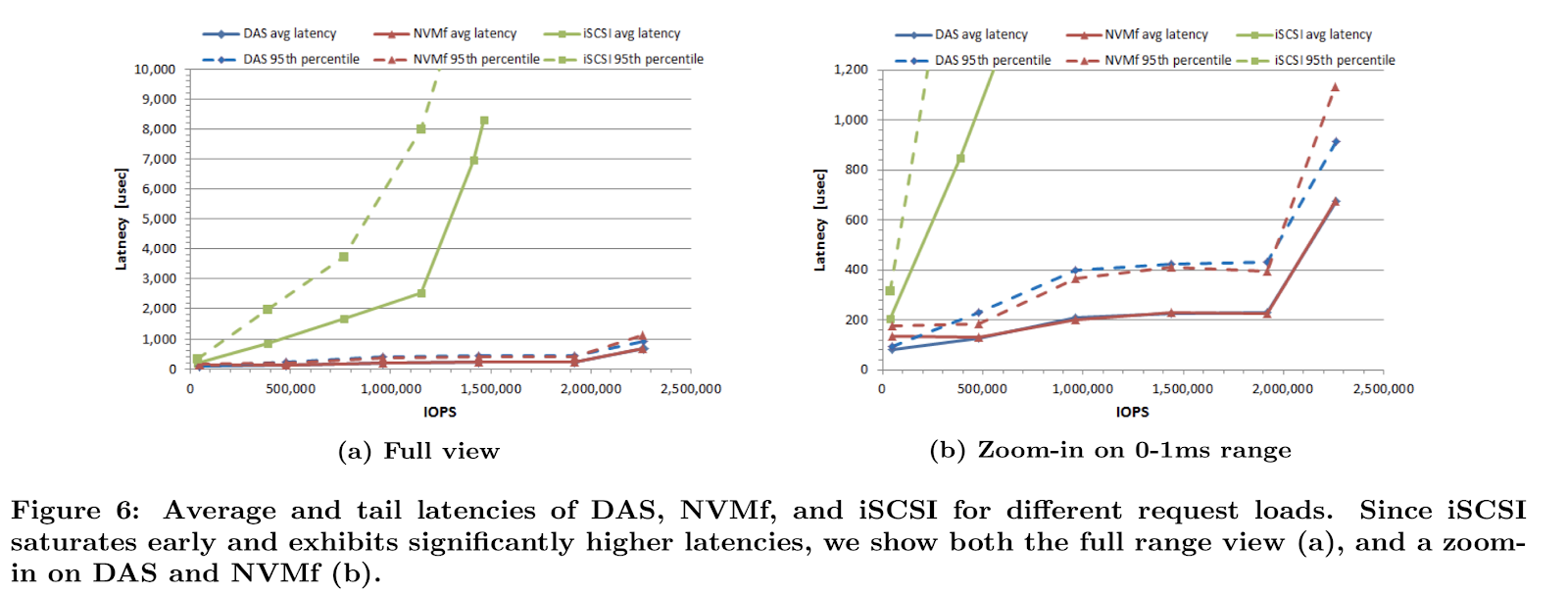 (source: Samsung)
(source: Samsung)This is possible because NVMF uses RDMA to efficiently access the memory of another computer without using the CPU or operating system of either. RDMA is a transport protocol that bypasses the kernel stack, offloading the workload to network hardware. This means the transport layer takes place in the RDMA NIC itself so data is transferred directly to or from application memory without having to involve the normal OS-level network stack, achieving low latency with low CPU consumption.
Of course, NVMF performance is gated by the networking infrastructure used, whether Ethernet, Infiniband or Fibre Channel. The November 2018 final ratification of the NVMe/TCP transport specification has accelerated adoption of NVMF because it allows storage fabrics to be deployed on standard network hardware.
NVMF can be used with white label storage systems (JBOD), feature-rich block storage systems (SAN), and storage systems built with previous generation (SATA) devices. This means data centers can simultaneously leverage low latency devices while also using more traditional storage subsystems. NVMF also supports using storage class memory as a cache in the data center compute hierarchy.
Why is NVMF Important?
Think of NVMe as a replacement for SCSI and NVMF as a replacement for iSCSI and iSER. NVMF has several distinguishing technical attributes that add up to huge performance scalability at the storage infrastructure layer:
- Protocol Efficiency: The NVMe-oF protocol is designed specifically for efficient memory transfers at scale. Designed from the ground up for scalability, the NVMe-oF protocol dramatically reduces the internal locking needed to serialize I/O and improves the efficiency of interrupt handling. NVMe-oF also supports MSI-X and interrupt steering, which prevents bottlenecking at the CPU level and enables massive scalability as systems scale. Combined with the large number of cores in modern processors, NVMe-oF delivers massive parallelism to connected devices which increases I/O throughput and lowers I/O latency.
- Command Set Efficiency: NVMe-oF has a streamlined and simple command set that uses less than half the number of CPU instructions to process an I/O request that SAS or SATA does, providing higher IOPS per CPU instruction cycle and lower I/O latency in the host software stack. NVMe-oF also supports enterprise features such as reservations and client features such as power management, extending the improved efficiency beyond just I/O. NVMEOF devices can approach DDR4 performance levels and, with SCM, become an integral component of the computing memory hierarchy.
- Queue Parallelism: With 65,535 parallel queues, each with a queue depth of 65,535 entries, NVMe-oF supports massive parallelism. Every CPU has a private queue to communicate with a data device and is capable of achieving high speeds because there are no locks between queues that live on separate cores. Because each controller has its own set of queues per CPU, I/O throughput increases linearly with the number of available cores.
- Integrated Security: NVMe-oF includes a tunneling protocol that provides security features produced by the Trusted Computing Group (TCG) and other related communities. Features planned for NVMe-oF devices and systems include simple access control, data at rest protection, crypto-erase, purge-level erase and others. Additional information on NVMe-oF security is available in the Trusted Computing Group and NVM Express Joint White Paper: TCG Storage, Opal and NVMe.
NVMe-oF is designed not only to solve the limitations of scale-out storage, but also to lay the foundation for a storage fabric that dynamically shifts as workloads demand.
What Makes NVMF Important to Kubernetes?
Kubernetes applications implicitly need the infrastructure flexibility enabled by NVMF. NVMF and Kubernetes makes distributed computing within sites easier. The key point of my Kubernetes-native blog was:
“(Kubernetes-native)...applications break apart into their constituent elements and can deploy and scale across the latency pyramid where they fit best. ... the elements dance across the infrastructure following their constituents in what I imagine as a containerized “ballet” focused on delivering the best possible user experience at the lowest possible latencies.”
However, multicloud, multisite and edge deployments introduce significant additional complexity for organizations operating Kubernetes at (or beyond) enterprise scale. Business needs are pushing IT teams to move workloads between sites, clouds, WAN & edge, and rapidly be able to clone, burst, and then destroy workloads anywhere around the world as needed. Yet Kubernetes deployment across multiple regions, sites, clouds, WAN & edge remains problematic.
OpenEBS is the solution for latency sensitive stateful Kubernetes workloads that need standardized data agility. A NVMF-based disaggregated storage physical fabric mates perfectly with the disaggregated data agility software infrastructure offered by OpenEBS. NVMF allows data to physically float across a single storage fabric while OpenEBS allows stateful workloads to be loosely coupled across multiple storage infrastructures. And the OpenEBS MayaStor project natively integrates to NVMF to simplify the developer experience.
Together, NVMF and OpenEBS become the dance floor for those Kubernetes-native application components to do their infrastructure-aware (and infrastructure-intelligent) ballet. Given its performance and scalability, however, perhaps this is better called the NVMF Boogie.
Note: This blog was originally published on November 7th, 2019 on DevOps blogs.





Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Why OpenEBS 3.0 for Kubernetes and Storage?
Kiran Mova
Kiran Mova
Deploy PostgreSQL On Kubernetes Using OpenEBS LocalPV
Murat Karslioglu
Murat Karslioglu