

Litmus operator allows developers and DevOps architects to introduce chaos into the applications and Kubernetes infrastructure in a declarative intent format. In other words — the Kubernetes way.

Litmus is growing in popularity throughout the community as a preferred means of injecting chaos in Kubernetes-based CI/CD pipelines (see reference use-cases for NuoDB, Prometheus & Cassandra). As one of the contributors to this project, I find that very exciting! One of the key benefits that Litmus brings to the table is the fact that, in simple terms, a chaos test/experiment can be run as a Kubernetes job with a custom resource as a test result. As you can discern, this is a model that promises easy integration with CI systems to implement chaos-themed e2e pipelines.
Why do we need a chaos operator and a workflow?
While what we use now is Kubernetes native, the community felt that the toolset should be further improved to encourage use in the actual places where chaos is thriving today: deployment environments (whether it be Dev/Staging/Pre-Prod/Production). While this certainly doesn’t mean Litmus in its current form cannot be used against such environments (Visit the OpenEBS workload dashboards to run some live chaos on active prod-grade apps!), there are some compelling differences, or rather, needs that must be met by the chaos frameworks to operate efficiently in these environments. Some of the core requirements identified were:
- The ability to schedule a chaos experiment (or a batch run of several experiments).
- The ability to monitor and visualize chaos results mapped to an application over a period of time, thereby analyzing its resiliency.
- The ability to run continuous-chaos as a background service based on filters such as annotations. This also implies the need for a resilient chaos execution engine that can tolerate failures and guarantee test-run resiliency.
- Standardized specs for chaos experiments with an option to download categorized experiment bundles.
In short, chaos needs to be orchestrated !!
The Lifecycle of a Chaos Experiment
We define three steps in the workflow of chaos orchestration:
- Definition of a chaos experiment — the nature of the chaos itself.
- The scheduling of this chaos — When and how often the chaos needs to be run.
- Predefined chaos experiments on a per-application basis as reference templates, which we call chaos charts.
We address the above requirements by making use of Kubernetes Custom Resources, Kubernetes Operators and Helm Charts, respectively.
ChaosEngine: Specifying the Chaos Intent
The ChaosEngine is the core schema that defines the chaos workflow for a given application and is the single source of truth about actions requested and performed. Currently, it defines the following:
- Application Data (namespace, labels, kind)
- A list of chaos experiments to be executed
- Attributes of the experiments, such as rank/priority
- An execution schedule for the batch run of the experiments
The ChaosEngine should be created and applied by the Developer/DevOps/SRE persona, with the desired effect of triggering the chaos workflow specified.
Here is a sample ChaosEngine Spec for reference:
Chaos Operator: Automating the Chaos Workflow
Operators have emerged as the de-facto standard for managing the lifecycle of non-trivial and non-standard resources (read: applications) in the Kubernetes world. In essence, these are nothing but custom-controllers with direct access to the Kubernetes API. They execute reconcile functions to ensure the desired state of a given custom resource is always met.
The Litmus Chaos Operator reconciles the state of the ChaosEngine. It's a primary resource and performs specific actions upon CRUD operations of the ChaosEngine CR. It is built using the popular Operator-SDK framework, which provides bootstrap support for new operator projects, allowing teams to focus on business/operational logic. The operator, which itself runs as a Kubernetes deployment, also defines secondary resources (the engine runner pod and engine monitor service). These are created and managed in order to implement the reconcile functions.
The Chaos Operator supports selective injection of chaos on applications through an annotation litmuschaos.io/chaos: “true”. With this annotation, it will skip applications that have chaos disabled.
Engine Runner Pod: This pod is launched by the Chaos Operator with the desired app information burned in (typically, as ENV) upon the creation of an instance of the ChaosEngine CR. It consists of the main runner container that either executes experiments or spawns experiment executors (litmusbooks) and an engine monitor sidecar, which is a custom Prometheus exporter used to collect chaos metrics. The state and results of these experiments are maintained in ChaosEngine CR and ChaosResult CRs.
Engine Monitor Service: The monitor service exposes the /metrics endpoint to allow scrape functions by Prometheus or other similarly supported monitoring platforms.
Chaos Exporter
As described, the chaos exporter is tied to a ChaosEngine custom resource which, in turn, is associated with the given application deployment. Two types of metrics are provided:
Fixed: TotalExperimentCount, TotalPassedTests, TotalFailedTests. These are derived from the ChaosEngine’s initial specifications and the overall experiment results.
Dynamic: Represents individual experiment run status. The list of experiments may vary across ChaosEngines (or newer tests may be patched into a given ChaosEngine CR). The exporter reports experiment status per the list in the ChaosEngine. Currently, the status of the experiments are represented via numerical values (Not-Executed: 0, Running: 1, Fail: 2, Pass: 3).
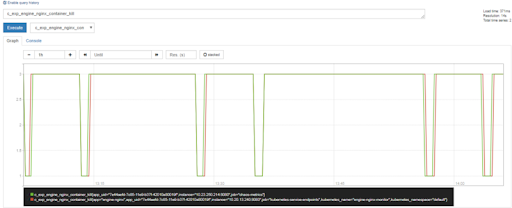
The metrics carry the application_uuid as a label in order to help dashboard solutions such as Grafana to filter metrics against deployed applications.
Chaos Charts: Packaging the Chaos Experiments
While the ChaosEngine defines the overall chaos intent and workflow for an application, there still exists a need to specify lower-level chaos experiment parameters, and the parameter list changes on a case-by-case basis. In the non-operator Litmus world, this is specified inside the litmusbook job as ENV. However, with the current requirements, these need to be placed inside a dedicated spec, with similar specs packaged together to form a downloadable chaos experiment bundle.
This is achieved by defining another custom resource called “ChaosExperiment”, with a set of these Custom Resources (CRs) packaged and installed as “Chaos Charts” using the Helm Kubernetes package manager. The chaos charts gather experiments belonging to a given category such as general Kubernetes Chaos, Provider specific (for ex: OpenEBS) Chaos, or Application specific Chaos (for ex: NuoDB).
These ChaosExperiments are listed/referenced in the ChaosEngine with their respective execution priority levels and are read by the executors to inject the desired chaos.
Here is a sample ChaosExperiment Spec for reference:
The spec.definition.fields and their corresponding values are used to construct the eventual execution artifact that runs the chaos experiment (typically, the litmusbook).
Next Steps in the Chaos Operator Development
The Litmus Chaos Operator is alpha today and is capable of performing batch runs of standard chaos experiments such as random pod failures and container crashes against applications annotated for chaos. It can also reliably collect data and metrics for these runs. As I write this post, support for scheduled chaos and priority based execution is being developed and will be ready very soon! The short-term roadmap also includes support for more useful metrics, such as an overall app resiliency metric (derived from the chaos runs), additional providers and app-specific chaos chart bundles.
Having said that, feel free to try out the demo steps or watch this video to better understand the functionality of the Chaos Operator.
As always, we welcome any feedback and contributions (via issues, proposals, code, blogs, etc.). In general, we would love to hear what you think about this project.
References:
- https://github.com/litmuschaos/litmus
- https://github.com/litmuschaos/chaos-operator
- https://github.com/litmuschaos/chaos-exporter
- https://github.com/litmuschaos/chaos-charts
This article was first published on May 22, 2019 on MayaData's Medium Account





Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Why OpenEBS 3.0 for Kubernetes and Storage?
Kiran Mova
Kiran Mova
Deploy PostgreSQL On Kubernetes Using OpenEBS LocalPV
Murat Karslioglu
Murat Karslioglu