

#K8s in 2020: the Storage Admin is dead, Long live the Kubernetes SRE
The past couple of decades will likely go down in history as transformative years for Infrastructure Engineering as well as their operators. These operators span from the humble beginnings of the baby boomer System Administrators with long beards to the highly curious, energetic and enthusiastic millennial Kubernetes SREs of today.

Kubernetes SREs, otherwise known as platform engineers, has gained broad acceptance in almost all enterprises. These engineers are tasked with answering a couple of important questions as Kelsey Hightower, the author of the SRE Handbook, puts it:
- How do I make it as easy as possible for the decisions, the ideas, products, and services that my company develops gets into the hands of the customers?
- How do I securely, safely, repeatedly and cost-effectively put my company’s services into the hands of the customers?
Over the past decade, Kubernetes has changed the way platform engineers implement the solutions to achieve the above - from building in-house tools to using a standardized set of open source tools like Kubernetes and its add-ons for networking, security, storage and so on. In this post, we'll explore how the role of platform administrators is being replaced by Kubernetes SREs and the factors that have influenced this change.
Looking back, some of the notable developments that led to this transformation could be summarized as follows:
- The explosive growth of data and the application of data to make business decisions. IoT, edge computing and the dreams of having fully automated homes and cars are further fueling the explosion to unfathomable heights. A lot of innovation and money are being poured into building products that manage all this data and derive usable information as quickly as possible.
- Anything as a service is available via public and private clouds. The maturity of the Platform as a Services model and adoption of public clouds has allowed us to sustain the speed with which data and business are growing. We have witnessed cloud-first companies like Netflix reach the pinnacle of success, forcing every other company regardless of size to reconsider the cloud as an integral part of their offerings.
- DevOps movement! This movement is the result of hours of efforts from many individuals via Agile, SCRUM, Kanban practices and the paradigm shift in software development towards automated test-driven development, extending to further automation into Deployment and operations with GitOps. The biggest hurdle for agility - the fear of failure - has been eliminated by adopting a continuous improvement mindset, allowing for realized Day 0 contributions. Now, 2 weeks is the longest before code gets deployed from a new developer on the team. The disaggregation of the teams also allows for faster and more independent growth. Microservices, with all its quirks and challenges, has become a key enabler for the DevOps movement. Full-stack and curious engineers are surviving this paradigm shift at the expense of those with rigid boundaries related to their work and projects.
- Open Source Software is eating the world! Fostering a community over a company mindset and an “Open Source first” culture has led to the biggest open source company buyout of the decade. Maintaining easy adoption, being extensible, and providing deep customization options have become the core tenets of Open Source systems. We have also seen the typical persona of Open Source, or general, software engineers change from elitist, holier-than-thou ivory tower inhabitants to individuals that foster open governance and welcoming communities.
- Kubernetes. It almost feels like these transformations in the technology landscape as well as the people and processing have finally culminated in Kubernetes emerging as a clear winner - with almost all major vendors providing some flavor of Kubernetized services. There are now more than 100 variants of Kubernetes providers and almost every application has been proven to run on Kubernetes. Kubernetes is truly the new Operating System! Kubernetes is the new Data Center OS! Kubernetes is a new language!
For the world of data management, which saw a 16x or 32x increase in available storage capacity on the individual nodes, software-defined storage along with hyper-converged infrastructure-led many to forecast the death of storage administrators. While most advancements and futuristic ideas tend to come with doomsday predictions and often self-fulfilling prophecies, the imminent death didn’t really come until Kubernetes expanded into use for data management itself. Of course, there is still a lot of ground to cover - but the role of Storage Administrators has clearly changed.
Kubernetes and Data Management
At first, Kubernetes didn’t embrace data with open arms. In fact, the early entrants (Startups) that tried to add data to their containers and Kubernetes were too early and unfortunately had to shut down.
Like a stateful workload itself, which is persistent, startups also must be persistent to fend off the forces that have tried to keep stateful workloads out of Kubernetes. It took efforts from several storage companies to fight the marketing buzz around stateless workloads and functions as services and establish the fact that there really is no such thing as stateless. An app’s state must be stored somewhere. It is either stored in the cloud or proprietary APIs, causing lock-in, data gravity, and usage of proprietary APIs to move data into and out of their environments.
However, with Kubernetes itself being such a great product with the vibrant community, it was not easy to keep statefulness at bay. The last two years have been very promising for Storage Startups such as MayaData, Upbound, and Heptio, all of which are working to ease the data management challenges in Kubernetes with Open Source projects. Over the last couple of years, Kubernetes has expanded itself into running Data Pipelines, CI/CD, Observability Tools (Grafana, Prometheus, Elastic,..) and so forth.
This shift can be largely attributed to the efforts of many community members from different organizations. Significant enhancements to Kubernetes Data Layer in 2019 include:
- Establishing the CSI standard and implementing a GA version in Kubernetes, all in record time. Parallels can be drawn in other areas as well as impressive standards that emerge in the Kubernetes space and Cloud-Native spaces like SMI and Cloud Events. This has been the result of the work of the wonderful community fostered by CNCF.
- Extensibility of Kubernetes in terms of adding additional functionality via custom resources and custom controllers, the widespread acceptance of the Operator pattern.
- Ease and affordability of building hyper-converged Kubernetes platforms using a wide variety of network plugins optimized for the network gear attached to the nodes and storage. This is done using Local PV or Open Source projects like Vitess, Minio, OpenEBS, and Rook that allow Kubernetes to provide enterprise-grade storage.
The Storage Admin is Dead
Today’s Dev Teams are required to operate with greater agility in delivering applications. The greatest bottlenecks hindering agility typically revolve around people and processes surrounding the infrastructure. Using an expensive infrastructure meant asking for permissions, planning in advance for the budgeting season, planning for types of workloads to avoid noisy neighbor issues on shared infrastructure, etc. Now, even a developer laptop can be turned into a production-grade Kubernetes environment with storage included, thanks to virtualization, Vagrant, Docker, and KinD.
Teams that have embraced DevOps typically find that using Hyper-Converged Infrastructure also helps hyper-converged operations, giving developers exactly what they need, when they need it. Developers can now focus on what they do best, working on the business logic, while the IT operations/DevOps can focus on what they do best.
Dev Teams can now provision a decent Kubernetes cluster with persistent storage using tools like OpenEBS without waiting for a Storage Administrator to provision, plan and permit storage infrastructure.
It is common these days to have a single SRE managing up to 50 developers and dozens of services by depending on one of the Cloud Providers. In fact, we are a big GKE shop ourselves!

Long live the Kubernetes SRE (aka Platform Engineering Team)
Just like how the roles of Developers, QA and Ops have blended in to give rise to high velocity, functional/domain-based small teams, the roles of storage administrators have merged with the Platform Engineers who are building fully automated, YAML/intent-driven data infrastructure.
Data teams have become largely disaggregated or distributed, resulting in silos. This reflects the same microservice patterns for people. Enterprises are internalizing the concepts of Data as a Product and Data Mesh/Data Ops! The typical team structure now looks as follows, wonderfully articulated by Zhamak Dehghani’s article on Data Mesh. This article is a must-read for anyone looking to achieve Cloud-Native Data Management.
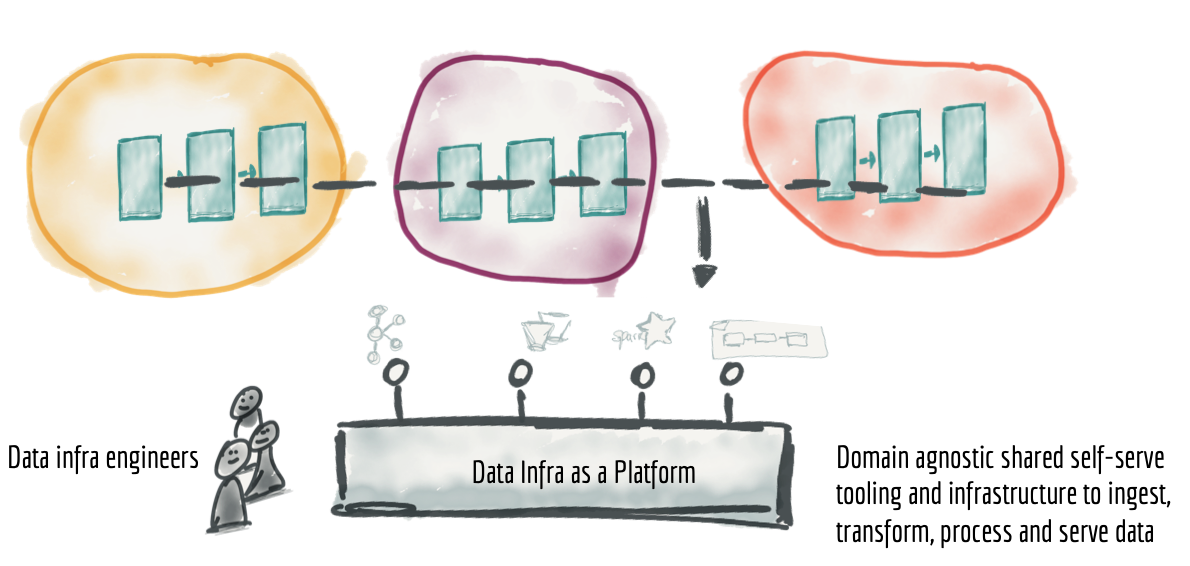
The ideal platform engineers develop a platform where developers can self-provision a source repository for their application. The self-service portal will go ahead and set up the required Docker and Kubernetes manifests and even enable CI/CD, all with just a few inputs.
It is evident that small enterprises really don’t need Storage Administrators anymore, and they can opt to either use a managed Kubernetes cluster from one of the several cloud providers or even run their own.
However, as a business, applications, and development team scales, the isolation can introduce chaos and make it harder for developers to move across teams. Platform Engineers, aka Kubernetes SREs, must then come to the rescue.
Platform Engineers help restore calm from chaos by setting up self-service portals for Dev teams to provision their own clusters or use a namespace within a cluster. Some platform teams have also extended the capabilities to the level of setting up code repositories with docker and Kubernetes manifests and integrate into CI/CD pipelines that also include Chaos Engineering.
 Long live Kubernetes SREs. Groot is reborn!
Long live Kubernetes SREs. Groot is reborn!
The role of the Kubernetes SREs has evolved, and they must now embrace responsibilities that were typically handled by the very storage administrators everyone declares extinct! These responsibilities include:
- The ability to proactively monitor and predict incidents before they happen via observability and auto-scaling features. Extending the capabilities to monitor storage infrastructure along with network and compute using a common set of tools.
- Budgeting and effective usage of the Infrastructure and storage components.
- Enforcing data security, governance, and compliance.
- Workload Mobility: Allow developers to move their workloads where they are needed or used, even to satisfy compliance policies like GDPR.
- While the CSI has been great, Kubernetes storage primitives act as basic building blocks that unlock the ability to develop advanced, enterprise-grade, storage administration features for Kubernetes, including application or cluster-level backup solutions. In fact, the Kubernetes Data Protection Workgroup is being formed to tackle these very issues. Similarly, VMware Velero is an interesting project to keep an eye on in this space.
The Kubernetes SREs will also have to work with the overall community to enable their enterprise to adopt best-in-class solutions that will ensure they remain competitive as the IT sector moves towards ARM-based Infrastructures, 5G Implementations, and proliferation of the Edge!
A final, but still important, aspect that Kubernetes SREs will be tasked with is to ensure their platforms are environmentally friendly. This could come from using more optimized deployments to actually migrating to infrastructures or cloud providers that have actually implemented next-generation sustainable data centers.
2020 looks bright and promising to Kubernetes SREs. Personally, I do everything I can to keep up with developments via the following resources in the data management space and Kubernetes:
Open Source Project communities
- Kubernetes SIG Storage
- Kubernetes SIG Apps
- Kubernetes UG Big Data
- Kubernetes WG Data Protection
- CNCF SIG Storage
- CNCF SIG App Delivery
- SODA
- Rook/Ceph
- OpenEBS
- Vitess
- TiKV
Conferences
- KubeCon
- SRECon
- Strata Data and AI
- Open Data Science
- Data Council
- QCon
- DevOpsDays
Blogs/Links
- https://kubernetes.io/blog/
- https://www.cncf.io/newsroom/blog/
- Kubernetes Storage Enhancements
- 2019 Data and AI Landscape
Podcasts/Webinars
- [CNCF] https://www.youtube.com/playlist?list=PLj6h78yzYM2PKJZ9hZ8CtDxJMzO5I6lZL
- [Kubernetes] https://kubernetespodcast.com/
- [Cloud Native] ]https://thepodlets.io/
- [Data Management] https://www.dataengineeringpodcast.com/
- [Data Management] ]https://www.oreilly.com/topics/oreilly-data-show-podcast
- [Storage] https://storageunpacked.com/
- [Storage] https://www.stitcher.com/podcast/storagereviewcom/storagereview-podcast
- [General] https://thenewstack.io/podcasts/
- [General] https://softwareengineeringdaily.com/
Another great source of engaging with the community is through your Local CNCF meetups or related Data Management meetups like Data-Driven, Data Council.
Do you know of another resource that is not listed above? Please share it with me via comments or on twitter.





Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Why OpenEBS 3.0 for Kubernetes and Storage?
Kiran Mova
Kiran Mova
Deploy PostgreSQL On Kubernetes Using OpenEBS LocalPV
Murat Karslioglu
Murat Karslioglu