

This article is part of a #Concepts series on Kubernetes and Litmus. In this post, we present an overview of the OpenEBS CI infrastructure with its Litmus powered e2e pipelines.
The OpenEBS project consists of several components (control plane and data plane) that directly support the dynamic provisioning and management of a persistent storage volume on the Kubernetes cluster. As with any microservice-oriented system following the DevOps paradigm, there is a clear need to continuously build and test each component, both in isolation (via unit tests) and in relation to the other pieces (integration tests) with an emphasis on standard end-user scenarios (e2e). Add in the need for basic interoperability verification (in terms of supported OS/Platform/Cluster versions) and you have the requirements for the CI framework.
The OpenEBS CI infrastructure is based on the Cloud-Native Gitlab CI framework, which is setup to monitor commits to the core components such as Maya, Jiva & cStor and also e2e (reduces turnaround time to verify testcase sanity). It uses Litmus to drive the e2e pipelines, thereby providing a reference for implementation of a Litmus-Experiment based e2e suite.
Gitlab Infrastructure
Some reasons for adopting Gitlab as the CI framework of choice (amongst standard benefits such as tight integration with our existing SCM, 2-factor auth, webhook support, well-defined UI with pipeline graphs etc..,) were driven by the need to move away from a plugin-based model (jenkins thrives on plugins, which may not always be advantageous) to a self-contained platform that supports simple pipeline definitions (.gitlab-ci.yaml is far easier to maintain than the groovy-based jenkinsfile!). Gitlab also offers a more mature kubernetes-native solution that gives users the ability to dogfood OpenEBS storage as the back-end store (PostgreSQL) for the Gitlab server.
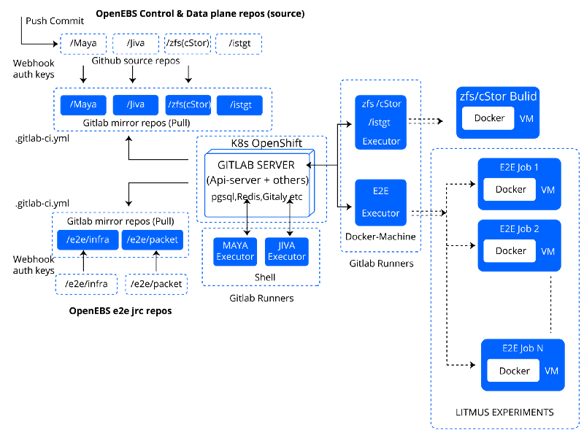
The Gitlab server
The Gitlab server (with its microservices such as Unicorn, Shell, Workhorse, Registry, Sidekiq, Gitaly, PostgreSQL, Redis, Minio) is hosted on a multi-node baremetal OpenShift cluster and is configured with pull-based repository mirroring of the OpenEBS component Github repos and a webhook based setup that triggers the pipelines upon commits.
While Maya and Jiva repos are mapped to shell-based executors due to certain build and integration-test requirements, cStor (zfs) and e2e repos are mapped to docker-machine based executors. The docker-machine executors are inherently auto-scaling, a necessary feature for e2e builds as multiple parallel jobs are spawned during the course of e2e pipelines.
OpenEBS CI Workflow
Each commit to the component source triggers the “gitlab build” procedure, which can be split into two logical phases: “component build” and “e2e.”
The component build executes the respective makefile which typically involves running unit tests, building the GO binaries, creating docker images, running integration tests and pushing docker images tagged with the commit SHA to the respective container repositories. It also performs certain pre-e2e routines before finally triggering the e2e pipelines.
The e2e phase involves running several parallel pipelines (based on Kubernetes cluster platforms or versions), with each pipeline containing multiple stages such as test bed setup, application deployment, Litmus experiments (functional and chaos), and finally clean-up. Needless to say, the component versions used are the ones built in the previous phase.
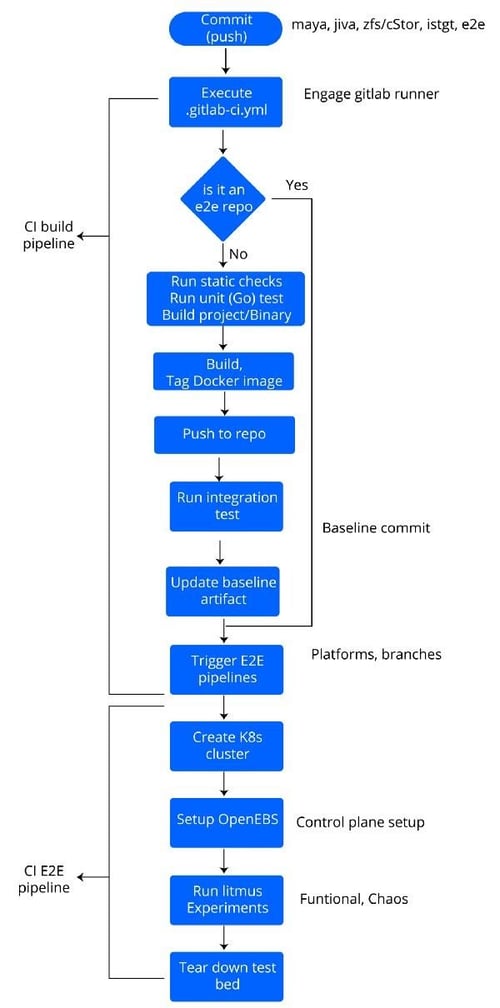
OpenEBS CI Workflow
Note: Currently, the Gitlab CI works in a “retrospective mode,” as it is invoked on commits to the upstream branches. There is work in progress to extend the support for pull requests (presently, a travis-based build verifies commit sanity to aid PR acceptance).
Baseline Commit
Before triggering the e2e pipelines as part of the final step, the build pipeline performs a pre-e2e routine to generate metadata about the impending e2e run. As is evident from the previous discussion, the e2e pipelines are triggered against commits to any of the OpenEBS component repos (maya, jiva, zfs/cstor, e2e). Images pushed as part of the build pipeline are deployed during the e2e. Therefore, it is necessary to baseline or identify an e2e run against the primary trigger (commit) while maintaining the details of image versions of the other relative components.
This is achieved by writing the details of the baseline commit (timestamp, component repo, branch and commit ID) into the file head of a “baseline artifact” maintained in a separate repository. Once the e2e pipeline is initiated, the baseline artifact is parsed ffor the “most current” image tags of each component, which will invariably include the current baseline commit and the latest ones for other components, in the test-bed preparation stage. This information is then used to precondition the OpenEBS Operator manifest before its deployment on the test clusters.
OpenEBS e2e Pipelines: Leveraging Litmus
One of the arguments against the inclusion of e2e as part of CI pipelines is that they could be flaky and time-consuming (under ideal circumstances it involves testing every moving part of the microservice and needs more maintenance). However, the e2e can confirm achievement of the goals that the solution was conceived and built to accomplish. The extent of coverage and the schedules can be optimized for development agility, but at OpenEBS, we feel it is a must-have in our CI pipelines.
OpenEBS CI makes use of Litmus to drive its e2e pipelines, right from test bed creation (cluster creation playbooks) all the way through the e2e tests (litmus experiments). The e2e pipeline involves several stages, with one or more gitlab jobs scheduled to run in a given stage. Each gitlab job is associated with a “runner script” that runs an “e2e test.” This in turn invokes/executes a litmus experiment (or litmus ansible playbook in the case of cluster creation/destroy jobs).
The various stages in the e2e pipeline are discussed below:
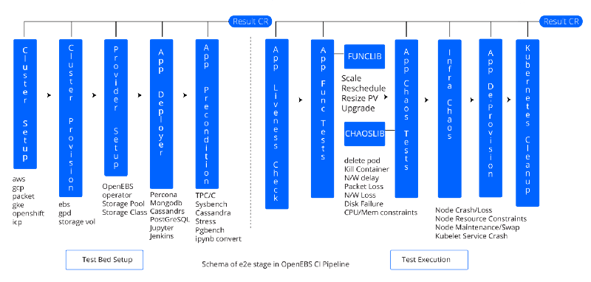
Cluster Creation: This stage calls up the Kubernetes cluster by executing the platform-specific playbooks. Cluster parameters are controlled via runtime arguments. The artifacts generated upon this job’s execution such as cluster config, which includes kubeconfig and cluster resource names, are passed over to subsequent stages as dependencies. The Litmus pre-requisites are also installed once the cluster is created. Currently, Litmus supports creation of clusters on these platforms:
- Baremetal Cloud: Packet (ARM based physical servers)
- Managed Kubernetes: GKE, EKS, AKS
- Cloud Hosted/Self-Installed: AWS, GCP (via KOPS)
- On-Premise: OpenShift (vSphere VMs)
Cluster Provision: Provision equips the cluster with additional disk resources native to the specific platform (GPD, EBS, Packet Block Storage, Azure Block Device) used by the storage-engines as physical storage resources.
Provider Setup: Here, the system deploys the customized/preconditioned OpenEBS Operator manifest (based on the baseline commit) on the cluster, thereby setting up the control plane and preparing default storage pool resources. The logging infrastructure (fluentd) is also setup on the created cluster.
Stateful Application Deployment: The OpenEBS e2e verifies interoperability with several standard stateful applications such as Percona-MySQL, MongoDB, Cassandra, PostgreSQL, Prometheus, Jenkins, Redis etc. These applications are deployed with OpenEBS storage classes (tuned for each app’s storage requirement). Each application is accompanied by respective load-generator jobs that simulate client operations and real-world workloads.
App Functionality Tests: Each deployed application is subjected to specific behavioural tests such as replica scale, upgrade, storage resize, app replica re-deployment, storage affinity etc. Most of these tests are common day-2 operations.
Storage/Persistent Volume Chaos Tests: The PV components such as controller/replica pods are subjected to chaos (pod crash/kill, lossy networks, disconnects) using tools such as chaoskube, pumba, and kubernetes APIs (via kubectl) to verify data availability and application liveness during adverse conditions.
Infrastructure Chaos Tests: The cluster components such as storage pools, nodes and disks are subjected to different failures using kubernetes APIs (forces evicts, cordon, drain) as well as platform/provider specific APIs (gcloud, awscli, packet) to verify data persistence and application liveness.
Stateful Application Cleanup: TThe deployed apps are deleted in this stage, thereby verifying de-provisioning and cleanup functionalities in the OpenEBS control plane.
Cluster Cleanup: The cluster resources (nodes, disks, VPCs) are deleted. With this final step, the e2e pipeline ends.
Gitlab e2e Job Runner Template
Each Gitlab job running the e2e test executes (bash) scripts containing steps to run and monitor a Litmus experiment. These scripts are invoked using desired arguments, specified as part of the job definition in the e2e repository’s `.gitlab-ci.yml`. The standard template maintained in these (bash) runner scripts and the performed tasks are described below.
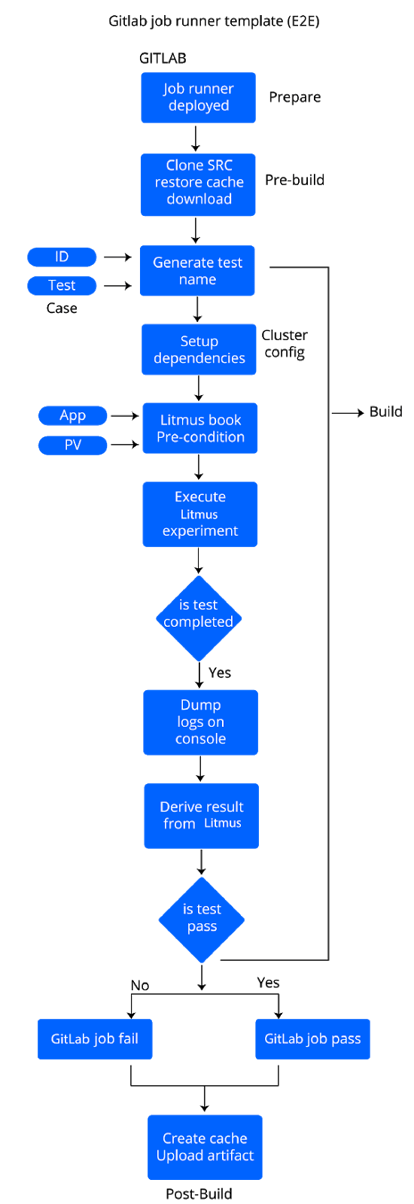
Gitlab runner template(E2E)
Generate Unique Test Name:Each gitlab job is associated with a litmus experiment that has a test/experiment name. The result of this litmus experiment is stored in a Litmus Custom Resource (CR) of the same name. The success of a test and therefore the gitlab job is derived from this CR. Occasionally, it is possible that the same litmus experiment is run against different applications or storage engines in a pipeline, thereby necessitating a unique element or ID in the CR name. In this step, a user-defined input (run_id) is accepted to generate a unique test/CR name.
Setup Dependencies: Depending on the nature of the gitlab job (cluster create/delete playbooks OR litmus experiments), the executor machine is updated with the appropriate directory structure and target cluster info (such as cluster configuration file, cluster names, disk details, VPC information etc.) to ensure successful test execution.
Precondition Litmusbook:Each litmusbook (the Kubernetes job specification YAML) consists of a default set of test inputs such as placeholders for application, storage, chaos info, etc. These are overridden/replaced by desired values in this step. In addition, the default name of the test is replaced with the unique name generated by the runner at the start of execution.
Run Litmus Experiment: The litmusbook is deployed and monitored for completion, with a polling interval of 10s. The status of both the litmus Kubernetes job and the ansible-runner container is checked as necessary and sufficient conditions, respectively, to determine completion of the litmus experiment.
Get Litmus Experiment Result: The result CR with the unique name generated is queried to determine the Litmus experiment result. The runner script completes execution with a zero/non-zero exit code depending on a pass/failure result, thereby setting the gitlab job status.
Logging Framework for e2e
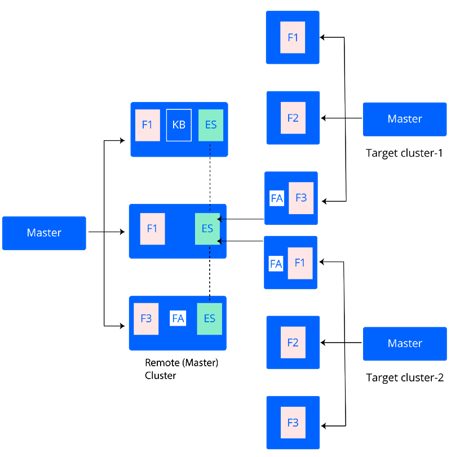
OpenEBS CI uses the popular EFK (Elasticsearch-Fluentd-Kibana) stack as the logging framework for the e2e pipelines. Each target cluster brought up as part of the e2e pipeline is configured with the fluentd-forwarder daemonset and fluentd-aggregator deployment, with the latter streaming the logs to the remote ElasticSearch instance running on the master (Gitlab-CI) cluster. These are then rendered by the Kibana visualization platform that is also running on the master cluster. The forwarders are configured with the appropriate filters based on pipeline and commit IDs to aid in a quick data analysis.
Conclusion
Hopefully this article has provided you with a better understanding of the CI/E2E practices in the OpenEBS project. CI is an important factor in contributor happiness as well as user confidence, and we are focused on continually making it more robust. Feel free to share your questions, comments and feedback with us — we are always listening!
This article was first published on Apr 2, 2019 on OpenEBS's Medium Account





Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Why OpenEBS 3.0 for Kubernetes and Storage?
Kiran Mova
Kiran Mova
Deploy PostgreSQL On Kubernetes Using OpenEBS LocalPV
Murat Karslioglu
Murat Karslioglu