

What a big topic! My goal here is just to introduce Kubernetes concepts specifically to support testing activity. In particular, the testing activity we’re trying to get to is a fully automatable, cloud-agnostic, chaos testing framework.
.png?width=706&name=Introduction%20to%20Kubernetes%20and%20Chaos%20Testing%20(2).png)
The tool we’ll use for Chaos testing is called Litmus (https://github.com/litmuschaos/litmus), and it runs inside this Kubernetes thing. We’ll talk more about that in a minute.
First of all, why do we want to do chaos testing at all?
Why Chaos Testing?
Chaos testing helps you find out how your application responds to infrastructure events. This isn’t that big a deal for a monolithic app where all the state is probably on one server. If your app is a suite of microservices that are all spread out across a bunch of servers, and if those microservices need to use the network to talk to other related services, then you’ll want to make sure the app comes back after a network interruption, right?
Or maybe you want to make sure your app continues working after:
- A server reboot
- An app component crash
- CPU starvation on the server
Litmus can help make sure of that. The way Litmus helps with that is by injecting chaos. This means Litmus triggers infrastructure events randomly and reports back on how Kubernetes handles it. The net effect is that you have event logs for an infrastructure event that you can correlate with application logs to find out how the app behaved in that particular infrastructure event. Say, for example, my app reads from a MinIO object-store Deployment, and the chaos I inject is to kill the pod associated with that MinIO Deployment; I can see when Litmus killed the pod, and when the pod went away, and what my app did when it couldn’t get to the object store, all in my Kubernetes logs. I don’t always get accurate information about the type and onset of real-world infrastructure events, but with Litmus, I can see the whole picture.
Sounds cool, right? There are lots of ways to Chaos Test your app, but if you’re already running your app in Kubernetes (and maybe you Devs have an app that you’re trying to do that with now?), then Litmus is your tool. But let’s come back to Kubernetes, what is it, and how does it work?
What’s Kubernetes?
There’s no way a blog post can sum up Kubernetes. It is, fundamentally, a container orchestration suite that you can use to find a server to run your containers on. To help it decide where to put the containers, it includes a consistent, declarative language for describing what the app components need. Kubernetes provides a nice abstraction of the compute infrastructure it runs on, and developers can use the same language to describe their app’s infrastructure requirements. We’ll walk through some components and architecture in a bit, but first, a little theory.
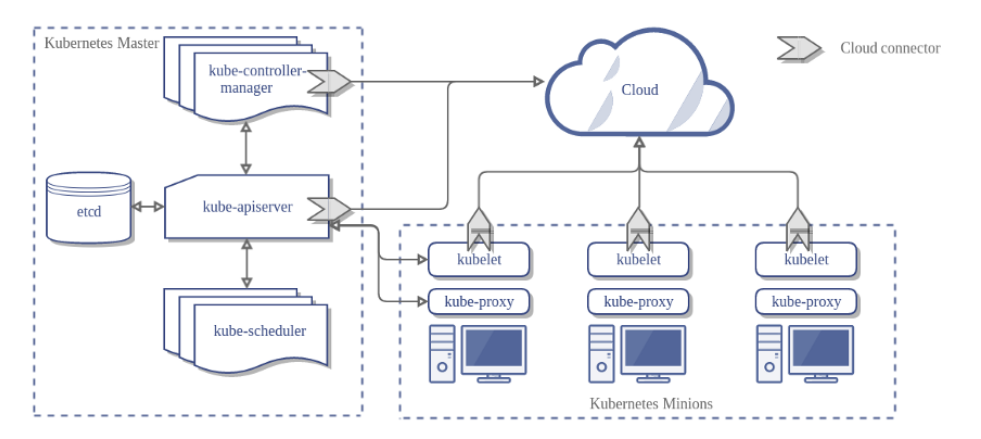

Kubernetes is an orchestrator for Cloud Native applications that are designed as a suite of microservices, which services all run in containers. Now, Kubernetes reads the description of the app that the developer writes. Kubernetes also collects info about the current state of the infrastructure. It uses all this info to make changes to infrastructure. When the Infrastructure looks the same as the developer’s specification, we’re done. Well, we’re done until something changes.
What’s going to change? Either the application or the infrastructure. The app might change because people or test programs are connecting to it, so that the application might be allocating more memory, asking databases for info, processing that info, and logging about that connection. The infrastructure might change because people or infrastructure management programs are adding, changing, or removing nodes from the cluster, so maybe Kubernetes is spinning up app components, connecting those components to load balancers, and then decommissioning other app components on the nodes that are changing. Kubernetes keeps track of all this change and continually makes sure the current state looks like the configured state. The software components that make these changes are called controllers. Controllers watch for changes in Kubernetes resources and change the infrastructure to get the current and configured states to match. A far better description of how all of this works can be found here: https://kubernetes.io/docs/concepts/architecture/controller/. For this document, we’ll call this pattern of watching for changes and modifying the infrastructure in response, the Reconciliation Loop.

Kubernetes is pretty complicated. Many components are working in concert to accomplish all of the above. In the next section, we’re going to race through some of the jargon associated with Kubernetes. Hang on!
Glossary
- K8s: An abbreviation of Kubernetes
- Resource: Some Kubernetes object, e.g., a pod, or a persistent volume.
- Nodes: Nodes are instances of Linux running Kubelet, and participating in a Kubernetes cluster. They can be bare metal or virtual machines. Nodes need a container runtime installed, like docker or containerd.
- Labels: Labels are metadata associated with some resource. Labels come in key=value pairs.
- Pods: Pods are the basic primitive for Kubernetes workloads. A pod has one or more containers in it, has a common namespace for things like network devices and processes, and probably has one or more services exposed so other pods can talk to it. Pods are intended to be short-lived.
- Deployments and StatefulSets: Deployments and StatefulSets create and organize groups of related pods. You might, for example, create a deployment that specifies that 10 instances of your app’s API server are running on the cluster at all times. You might use a StatefulSet in situations where that API needs some persistent storage that’s sitting on the node that the API is running on, and you want to make sure the API gets the same storage after a restart.
- Services: Services define an address and port that other pods within the cluster, or other applications outside of the cluster, can establish a network connection to. This is typically a TCP port, but it could be anything. Services can be cluster-facing, external (via the load balancer, or just a port on each of the nodes).
- Volumes: Apps that need storage can be associated with a Persistent Volume. These volumes are associated with a pod by a Persistent Volume Claim, where you configure the parameters of the volume. Kubernetes creates the volume based on the declarative configuration in the claim, and the storage class referenced. Volumes can outlive pods.
- Namespaces: Kubernetes uses namespaces to organize resources it knows about. Your deployments, pods, services, and PVCs all belong in one namespace or another. As an example, if you install OpenEBS, all of the OpenEBS components share a single namespace.
- ConfigMaps and Secrets: Most apps require a config file of some sort. ConfigMaps and Secrets are like persistent volumes but simpler. They are intended for use for configuration files, as well as SSL certificates and the like.
- Custom Resource Definitions: Kubernetes is extensible via Custom Resource Definitions. CRDs define new kinds of objects, as well as controllers that watch those objects and act on them.
- Controllers and Operators: Controllers, as mentioned above, watch and work on resources. Operators are a special case of controllers. You use the Operator Pattern to extend Kubernetes.
Kubernetes was initially designed for hosting stateless applications. For stateless apps, the app gets everything it needs for its output in its input. For stateful apps, the app remembers stuff and then uses that in conjunction with inputs to generate its output. The app is said to “keep state” and use state during its processing. So what to do with the application state?
Put it in the cloud, of course! The cloud providers all have services that are designed for you to keep state for your 12-factor app. The app runs in Kubernetes, it keeps its state in proprietary solutions like RDS and S3, and then you use and ELB to talk to the front end. Done. Or, you can put it in Kubernetes itself using tools like OpenEBS to manage your storage; this way, your databases work like any other app you deploy.
One advantage of putting it in Kubernetes is that you then get to find out what happens when the app’s connection to the storage is interrupted. Since you have control over all of the infrastructure just by changing Kubernetes, you can use tools like Litmus, which work within Kubernetes, to simulate an outage. Outages happen. What’s important is how your application responds to the outage. Does it come back up on its own? After how long? With Litmus, you know exactly when you’ve injected the chaos, and you can observe the results in a controlled environment. If you just put all of your stateful components in cloud services, you can’t necessarily simulate outages the same way, and you’ll have to rely on your cloud provider’s info to correlate storage events with application behaviors.

This is one compelling reason for keeping it all inside Kubernetes — storage, stateful apps, and stateless apps, along with networking components — because it’s easy to correlate event logs. Kubernetes also provides a nice consistent user interface for developers (as opposed to internal docs for internal infra management tools, which are harder for new engineers to find and digest, generally speaking). With Litmus, since it’s implemented as a Controller (we talked about controllers, right?) with its own CRDs (remember that too?) and takes advantage of all of this built-in observability and usability, it’s pretty easy to fit chaos testing into your existing k8s deployment workflows.
So,
kubectl apply -f https://litmuschaos.github.io/pages/litmus-operator-v1.1.0.yamlShould get you started with Litmus, and you can see it running with
kubectl get pods -n litmushttps://docs.openebs.io/docs/next/chaostest.html has a full walkthrough, but I’ll summarize here:
- Install litmus
- Create an SA that grants access to the apps in the same namespace as the app you want to test (e.g., MinIO in the namespace “backup”)
- Create a ChaosEngine in the app’s namespace that will operate on the app based on labels you define in the engine manifest.
- Watch(1) the chaos!
For the SA, Role, and RoleBinding, I’ll include a working sample from our documentation. RBAC in Kubernetes is a whole other topic.
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: chaos-sa
namespace: backup
labels:
name: chaos-sa
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: Role
metadata:
name: chaos-sa
namespace: backup
labels:
name: chaos-sa
rules:
- apiGroups: ["","litmuschaos.io","batch","apps"]
resources: ["pods","jobs","daemonsets","pods/exec","chaosengines","chaosexperiments","chaosresults"]
verbs: ["create","list","get","patch","update","delete"]
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: chaos-sa
namespace: backup
labels:
name: chaos-sa
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: chaos-sa
subjects:
- kind: ServiceAccount
name: chaos-sa
namespace: backupApplying this authorizes litmus to manipulate the app. We can tell Litmus what to do to the app with a Chaos Experiment like this one:
---
# chaosengine.yaml
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: minio-chaos
namespace: backup
spec:
annotationCheck: 'false'
components:
runner:
image: 'litmuschaos/chaos-executor:1.0.0'
type: 'go'
jobCleanUpPolicy: 'delete'
monitoring: false
appinfo:
appns: 'backup'
applabel: 'app=minio'
appkind: 'deployment'
chaosServiceAccount: chaos-sa
experiments:
- name: pod-delete
spec:
components:
- name: TARGET_CONTAINER
value: minio-stretchedWhen we apply this, sure enough, after a couple of minutes, the pod associated with the deployment called “minio-stretched” goes away, and Kubernetes dutifully creates another one to replace it.
Now, I can fire up Kibana or what have you, and look at how the app responds during the object store outage. I know exactly when it went down and came back up. There are loads of tools to help find out what happened to my application. Once I fix any bugs related to that particular type of event, I’ve got a ready-made regression test for the change. When I integrate my component with everyone else’s, I can find out how my application’s failure and recovery impacts other components. And when it’s all running in my prod cluster, my SREs can use the same test to validate their alerting infrastructure and SLA requirements.
Thanks all for taking this journey with me. If this sounds like something you want to check out, head over to the Litmus Chaos Hub and then meet us in #Litmus.
Cheers,
Brian





Managing Ephemeral Storage on Kubernetes with OpenEBS
Kiran Mova
Kiran Mova
Why OpenEBS 3.0 for Kubernetes and Storage?
Kiran Mova
Kiran Mova
Deploy PostgreSQL On Kubernetes Using OpenEBS LocalPV
Murat Karslioglu
Murat Karslioglu